최근 depth foundation model들이 많이 발표되었습니다. mono camera만으로도 depth를 상당한 퀄리티로 estimation하는데요. 몇가지 모델에 대해서 알아보겠습니다.
전통의 컴퓨터비전을 이용한 방법으로는 stereo에서 Rectification(정렬)하여 epopolar condition을 만족시킵니다. 이후 disparity를 계산하고 (동일한 feature point가 두 이미지에서 차지하는 픽셀 좌표의 차이) triangulation을 이용해서 depth를 추정합니다.
$Z = \frac{f \dot baseline}{Disparity}$
자세한 부분은 아래 포스팅 참고하세요.
[SLAM] 3. 2D-2D geometry, Epipolar Geometry
안녕하세요. 후니대디입니다. 이번 포스팅은 2D-2D (two view) camera geometry에 대해서 살펴보겠습니다. Camera Model 시작하기전에 camera model 먼저 살펴보겠습니다. 3D world의 points를 2D image plane에 매핑하는
jaehoon-daddy.tistory.com
[SLAM] 4. 3D-2D geometry, Triangulation, PnP
안녕하세요. 후니대디입니다. 지난번에는 2D-2D geometry로 Essential Matrix, Fundamental Matrix에 관해 다루어봤습니다. 즉, Two view가 존재할때 (stereo 혹은 sequenced frame) two view간의 관계를 설명해보았습니다.
jaehoon-daddy.tistory.com
DepthAnything

DepthAnytning은 foundation depth 모델의 시발점이라고 할 수 있습니다. 애초에 depth label을 가진 데이터의 개수가 많지 않기 때문입니다.
최근에는 많은 MDE(monocular depth estimation) 모델이 나왔는데, discriminative model을 기반으로 하는 방법과 stable diffusion을 기반으로 하는 방법으로 나눌수 있는데 depthanything은 전자에 속합니다.
SSL
unlabeled dataset활용을 위해서 ST++ 의 방식을 사용하였습니다. Teacher model은 labeled dataset으로학습시키고 T모델에 unlabeled data를 통해 얻는 depth estimation을 pseudo label로 얻습니다. Student model은 labeled dataset과 pseudo labeled dataset을 shuffle해서 scratch부터 학습시킵니다.

문제는 성능의 향상이 미약하다는 점이였고 저자는 데이터양에서 그 원인을 찾습니다.
perturbation
앞선 문제를 해결하기 위해 image perturbation으로 color fittering, gaussian blurring, strong spatial distortion을 unlabeled image에만 사용합니다.
CutMix는 애초에 classification에 활용되는 방법인데 depth 에 어떻게 적용했는지 보면,

label이 없는 임의의 이미지 두장을 공간적으로 interpolation한다는 의미입니다.

M, 1-M으로 정의된 영역에서 affine-invariant loss를 얻습니다.

Semantic-Assisted Perception
기존의 연구들에서 auxilary semantic sementation task를 통해서 depth esimtation성능향상을 시도하였는데 본 논문에서는 RAM, GroundingDINO, HQ-SAM을 조합하여 unlabeled image에 semantic segmentation label을 할당하는 시도를 했습니다. 처음에는 encoder를 공유하고 별개의 decoder를 사용하는 방법을 취했지만 성능향상이 없었다고 합니다. 해서 DINOv2의 semantic feature를 depth model로 transfer하는 것을 제안하였는데 feature alignment loss는 아래와 같습니다.

f는 depth model에 의해 추출된 feature이며 f'는 DINOv2 encoder의 feature입니다. cosine similarity가 일정값이상 초과하면 해당 픽셀은 $L_{feat}$가 고려되지 않도록 설정하여 DINOv2 encoder에 심하게 bias되는것을 방지합니다.
DepthAnything v2
v1에서는 MDE성능 향상을 위해 대규모 데이터셋을 구축하였는데 많은 label imperfect하다는 것을 파악하였습니다. 이를 위해 synthetic data를 사용하였습니다. (BlenderMVS, Hypersim, IRS, TartanAir, VKITTI 2)
문제는 synthetic data와 real image사이의 간극입니다. 즉 synthetic data만 학습에 사용한 모델의 generalization성능에 문제가 있다는 뜻입니다.

이를 위해 비교적 robust한 DINOv2-G를 이용해서 synthetic image를 학습시키고 이를 이용해 unlabeled real images에 pseudo label을 생성하고 최종 student model을 이 pseudo label을 사용해서 학습시킵니다. 마지막단계에서 synthetic data는 필요하지 않습니다.
v1과 동일하게 pseudo label샘플에 대해서 loss 상위 10%의 영역은 무시하고 feature alignment loss를 사용합니다. 이외의 loss function은 MiDaS의 loss를 사용합니다.

Unidepth

앞서의 방법들은 MDE로 보통 relative depth를 추정합니다. 문제는 실제 application단에서는 실제의 depth estimation값이 필요합니다. Unidepth는 metric depth를 추정하는 MMDE 모델입니다.
단일 이미지만으로 metric depth를 추정하기 위해 intrinsic matrix도 prediction합니다. 즉, depth와 camera parameter 이렇게 두개의 Task를 수행하는 model을 만들었습니다.
또한 보통의 좌표계(X, Y, Z)대신에 방위각, 고도각, log depth로 이루어진 가상의 구형 좌표계를 활용하였습니다.

camera embedding에서 focal length와 principal point가 업데이트 될 수 있도록 설계합니다.
또한 geometric augmentation을 적용하였습니다. 이 때 Geometric Invariance Loss인 양뱡향 loss를 적용하여 서로 다른 geometric augmentation을 적용하더라도 동일한 depth를 추정할 수 있도록 하였습니다.

depth pro

Unidepth와 마찬가지로 MMDE모델입니다. 핵심 아이디어는 ViT의 encoder를 다양한 scale에서 추출한 patch에 적용하고 패치에 대한 depth estimation을 하느의 최종 고해상도 depth map으로 concat하는 것입니다.
DPT decoder와 유사한 형태의 decoder 모듈을 사용하여 최종 depth map을 출력합니다.
intrinsic의 처리를 위해서는 별도의 head를 추가하여 focal lengt를 추정합니다. principal point와 skew는 depth에 큰 영향을 미치지 않기때문에 추정하지않고 absolute scale 확보를 위해 focal length만을 고려합니다.
다른 모델과 달리 특별한 부분은 two-stage training으로 1단계에서는 real, synthetic dataset을 조합하여 학습을 하고 2단계에서 boundary sharpness의 성능향상을 위해 synthetic data만을 사용합니다.
Metric3D
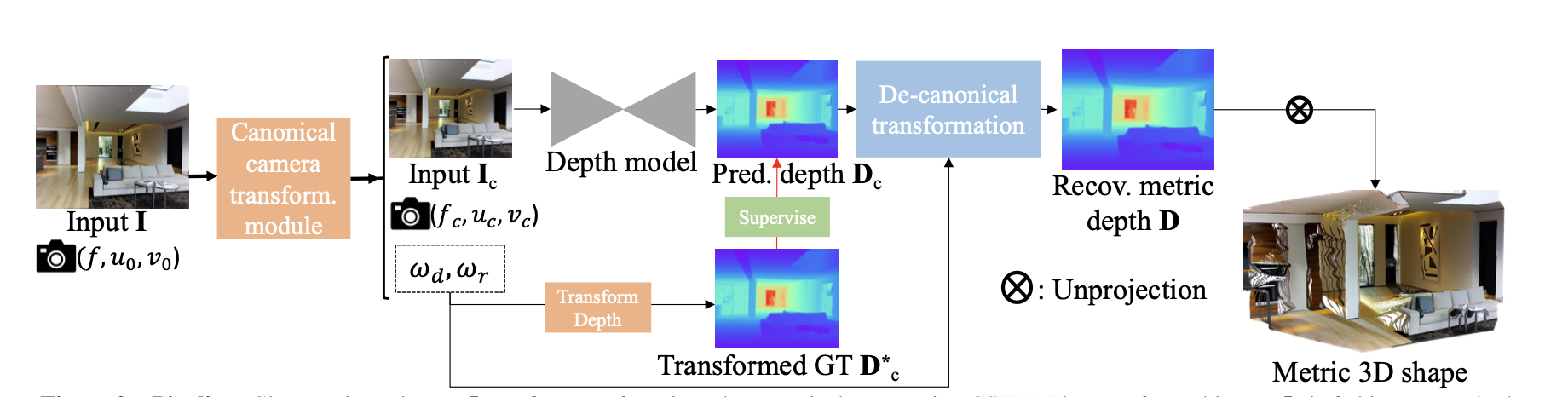
해당 논문은 Metric Depth를 추정합니다. 제 생각에 주요 특징은 Canonical Camera Transformation부분인데 data, label을 canonical space로 변환하여 camera parameter가 모델성능에 영향을 주는 것을 최소화하는 부분입니다.
depth pro랑 다르게 focal length를 estimation하지는 않습니다. 즉, 미리 intrinsic 은 알고 있어야 합니다.
loss로는 RPNL이라는 random proposal normalization loss를 추가하였는데 기존의 전체 이미지에 기반한 정규화는 local 의 detail을 잃어버릴수 있어서 local의 depth distribution을 더 잘 보존하기 위해 해당 loss를 추가하였습니다.

모델의 컨셉은 ConvNeXt-large를 백본으로하여 UNet아키텍쳐를 기반으로 구현하였습니다.
Metric3D v2

Metric3D v2는 depth estimation과 surface normal을 동시에 추정하는 multi task model로 구성되어있습니다. v1과 마찬가지로 canonical space에서 학습을 진행하여 metric ambiguity를 해결하고 RPNL loss와 depth, normal의 consistency를 일치시키기 위한 loss를 추가하였습니다.
Joint Optimization에서 ConvGRU를 기반으로 iterative optimization을 하여 depth와 normal을 세밀하게 최적화합니다. depth와 normal을 서로 시너지가 나는 변수들이라 multi-task가 성능향상에 도움이 되는 듯합니다.
GRU를 사용해서 optimization하는 방법은 아래 Droid slam포스팅 참고하세요.
[paper review] DROID-SLAM (Deep Visual SLAM) 논문 리뷰
안녕하세요. 이번 포스팅은 DROID-SLAM이라는 논문을 리뷰하겠습니다. '21에 발표된 성능 좋은 Deep-based SLAM으로 그 구조를 뜯어보도록 하겠습니다. Intro 우선 visual SLAM을 살펴보겠습니다. 제가 임의
jaehoon-daddy.tistory.com



