기본적으로 Supervised Learning을 위한 Label확보는 많은 비용을 필요로 합니다. 그렇기에 representation정도는 unlabeled data만으로도 확보할수있지 않을까?하는 시작에서 나온것이 self-supervision입니다.
self-supervision

즉, unlabeled data를 이용해서 훌륭한 representation(feature라고 생각해도 됩니다) 을 얻고자하는 것이 self-supervision의 목적입니다. 보통 위 그림처럼 이렇게 학습한 representation을 이용해서 downstream task에 적용하여 모델을 평가합니다. (나이브하게 ssl의 정의를 정리하면 백본 네트워크를 효율적으로 학습해서 downstream작업에서 활용할 수 있는 고품질의 representation 얻기)
self-prediction
ssl방법중에 하나로 보통 데이터의 일부를 이용해서 나머지를 예측하는 task를 말합니다.
time-series(시계열) 다음번 step을 예측하는 방식이 대표적입니다. 이제 구체적인 방법을 살펴봅시다.
Autoregressive Generation

이전의 결과를 통해 앞으로는 결과를 예측하는 방법이다. language라면 다음에 올 단어를 예측하는 경우이다. GPT, PixelCNN이 있고 보통 VQ와 함께 사용된다.
(*VQ : 데이터를 효율적으로 압축하는 방법으로 연속적인 데이터를 이산적인 code book 벡터로 변환)
Masked Prediction

정보의 일부를 masking하여 masking하지 않은 부분을 활용하여 masking영역을 예측하는 식으로 학습합니다. 보통 masking은 random하게 진행되기 때문에 다양한 scale, size의 학습이 가능합니다. 해당 방법이 뒤에 설명할 contrastive learning보다 좋은 성능을 내고 있습니다.
BERT, MAE 등이 해당 방법의 예 입니다.
Innate relationship prediction

image에서 augmentation 정도를 맞추거나 patch 기반의 jigsaw 퍼즐을 푸는식의 방식이 있습니다. contrastive learning에 auxilary하게 쓰이기도 합니다.
위의 그림처럼 어떤 augmentation이 쓰였지를 맞추는 식으로 이 방법을 통해 augmentation aware한 feature를 얻을 수 있습니다.
Hybrid self-prediction
마지막으로 앞서의 방법들을 mix하는 방식들이 있습니다. DALL-E, VQ-GAN등이 있습니다.
Contrastive Learning


SSL의 두번째 method로, invariance를 학습하는 것이 목표입니다.
* prior-knowledge
anchor : 기준이 되는 데이터 샘플
positive pair : anchor와 상관관계가 높은 데이터 샘플 (key)
negative pair : anchor와 상관관계가 낮은 데이터 샘플
view : anchor와 동일한 semantic을 가지는 샘플인데, 보통 augmentation을 샘플이나 다른 modality의 동일한 의미의 샘플을 뜻함

contrastive learning은 siamese network이라고 불리는 하나의 input으로부터 얻은 augmented view 여러개에 대한 latent를 비교하는 방식으로 발전했습니다. 이는 positive pair의 distance를 minimize하는 방식으로 작동하여 muti view의 고유의 feature를 뽑겠다는 목적을 가집니다. 보통 supervision의 방식보다 uniform하고 align된다는 사실이 실험적으로 증명되었습니다.
문제는 positive pair만으로는 representation이 잘 학습되지 않는 현상이 발생합니다.(representation collapse) 이를 위해서 negative pair를 활용하는 방법들이 또한 등장합니다.
Inter-sample classification(instance discrimination)
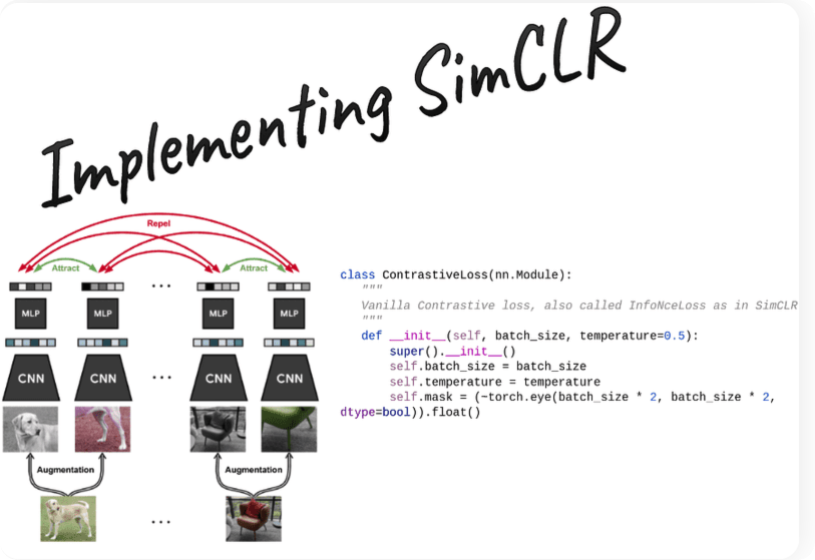
contrastive learning은 일종의 classification을 pretext task라고 볼 수 있는데, anchor와 positive, negative를 구별하는 것이기 때문입니다. 대표적인 방법으로는 MoCo, SimCLR이 있습니다.
간단히 요약하면 각각 다른 encoder를 통과시킨 different view(ex, augmentation)으로 생성한 positivie pairf를 가까워지도록 학습하는 방법입니다. (negative pair를 멀어지도록 학습)
의문이 드는 점은 gt가 없는데 negative sample을 어떻게 고를까요?
일반적으로 같은 배치내에서 다른 샘플들은 서로 다른 데이터라고 가정합니다.(same batch assumption). MoCo에서는 memory bak를 활용해서 이전 배치에서 생성된 모든 embedding을 memory bank에 저장후 비교해서 negative pair로 사용합니다. same batch assumption이 통하는 이유는 엄청나게 많은 데이터를 사용하기에 같은 class의 이미지가 동일 batch내에서 선택될 확률이 극히 낮기 때문입니다.
보통 batch내에 positive sample이 있다면 오히려 학습에 방해가 되고 negative sample이 많을수록 representation collapse를 방지하는데 효과적입니다. 그래서 batch size를 크게 활용합니다.
loss로는 보통 triplet loss를 활용합니다. metric learning의 일종으로 distance를 기반으로 합니다.
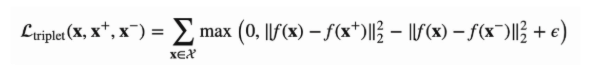
그 외에 cross-entropy loss를 활용한 InfoNCE방법이 있습니다. (참고)
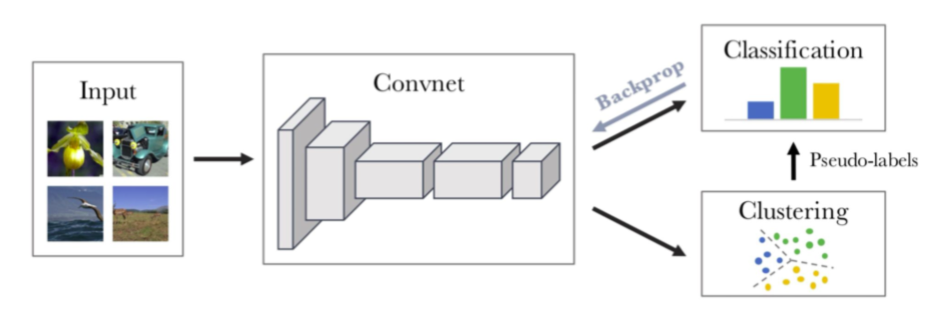
Feature clustering
encoder를 통해 나온 feature representation으로 샘플들을 clustering하는 방법으로 clustering으로 pseudo label을 명시적으로 달고 이를 통해 inter-sample classification을 진행합니다. inter-sample classification이 batch내에 다른 샘플들을 negative sample로 하는 가정에 대한 대안으로 볼 수 있습니다. DeepCluster, SwAV, interCLR이 있습니다.
Non-contrastive methods with joint embedding architecture
앞서 설명한 방법들은 representation collapse를 해결하기 위해 기본적으로 batch안에 negative sample이 많이 필요합니다. 아래는 이를 해결하기 위한 방법들 입니다.
BYOL & SimSiam
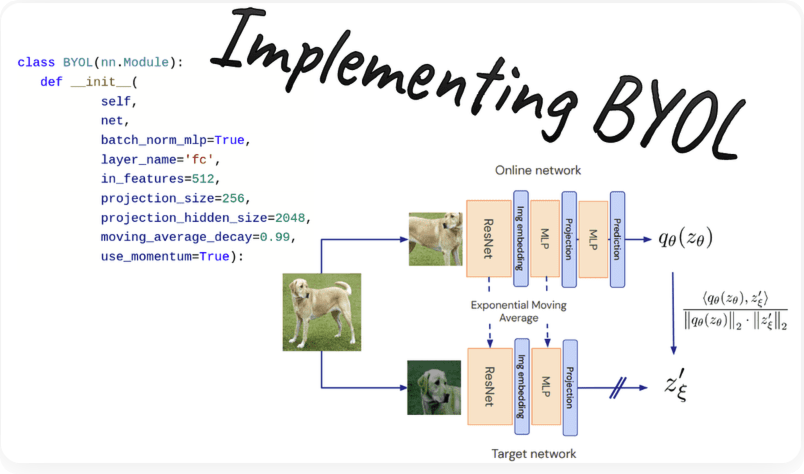
BYOL은 distilation 구조를 가지고 momentum encoder는 파라미터를 exponential moving average를 통해 앙상블하기 때문에 안정적으로 representation 학습이 가능합니다. simsiam의 경우 momentum encoder대신에 stop-gradient를 활용합니다.
predictor를 활용하는데 뒤부분의 layer로 갈수록 task specific한 정보가 생성되고 encoder쪽에는 pure한 representation을 생성하게 됩니다.
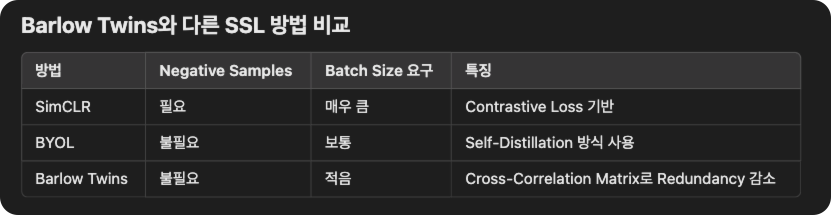
Barlow Twins & VICReg


위의 방법들도 결국 batch사이즈를 최소화하면서 negative collapse를 줄이는 방법을 고안하였습니다. 핵심은 disentangled representation의 개념이 사용되었는데, representation의 dimension들이 각각 서로 다른 의미를 가지도록 학습하는 방법입니다. barlow twins는 positive pair간 cross correlation matrix를 구해서 이 matrix가 identity matrix가 되도록 loss를 적용하는 방법입니다.