Knowledge distillation의 출발이유에서부터 알아봅시다. 최근에는 몇십억개의 파라미터를 가진 모델들도 흔하지만 실제 다운스트림하여 사용하는 모델은 최대한 모델을 효율적으로 압축해야합니다.
prune, weight share, knowledge distillation이 그 방법들의 대표적 예입니다.
Knowledge distillation?
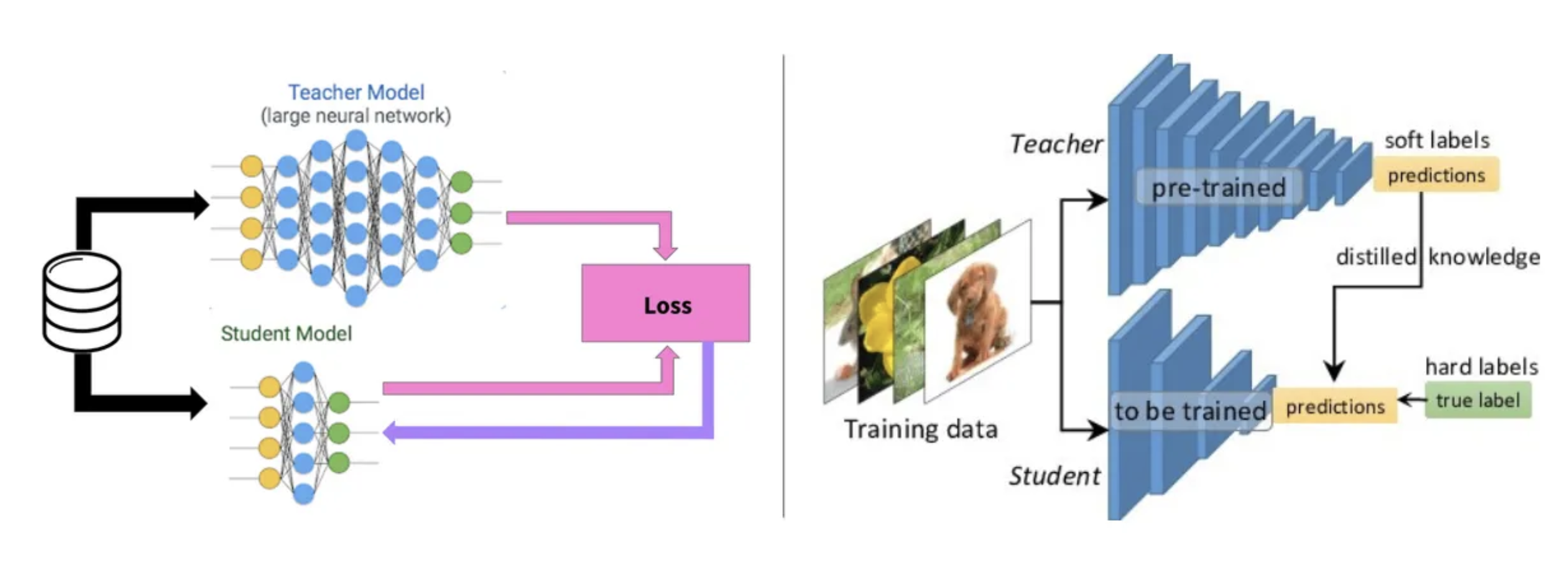
큰 모델(Teacher network), 작은 모델(Student network)를 사용해서 큰 모델을 모사하는 작은 모델을 만드는 것이 목적입니다. 예컨대 다음 글자를 예측하는 teacher 모델이 있다고 할 때 student 모델이 teacher모델이 생성한 psuedo label을 이용하는 것 입니다.
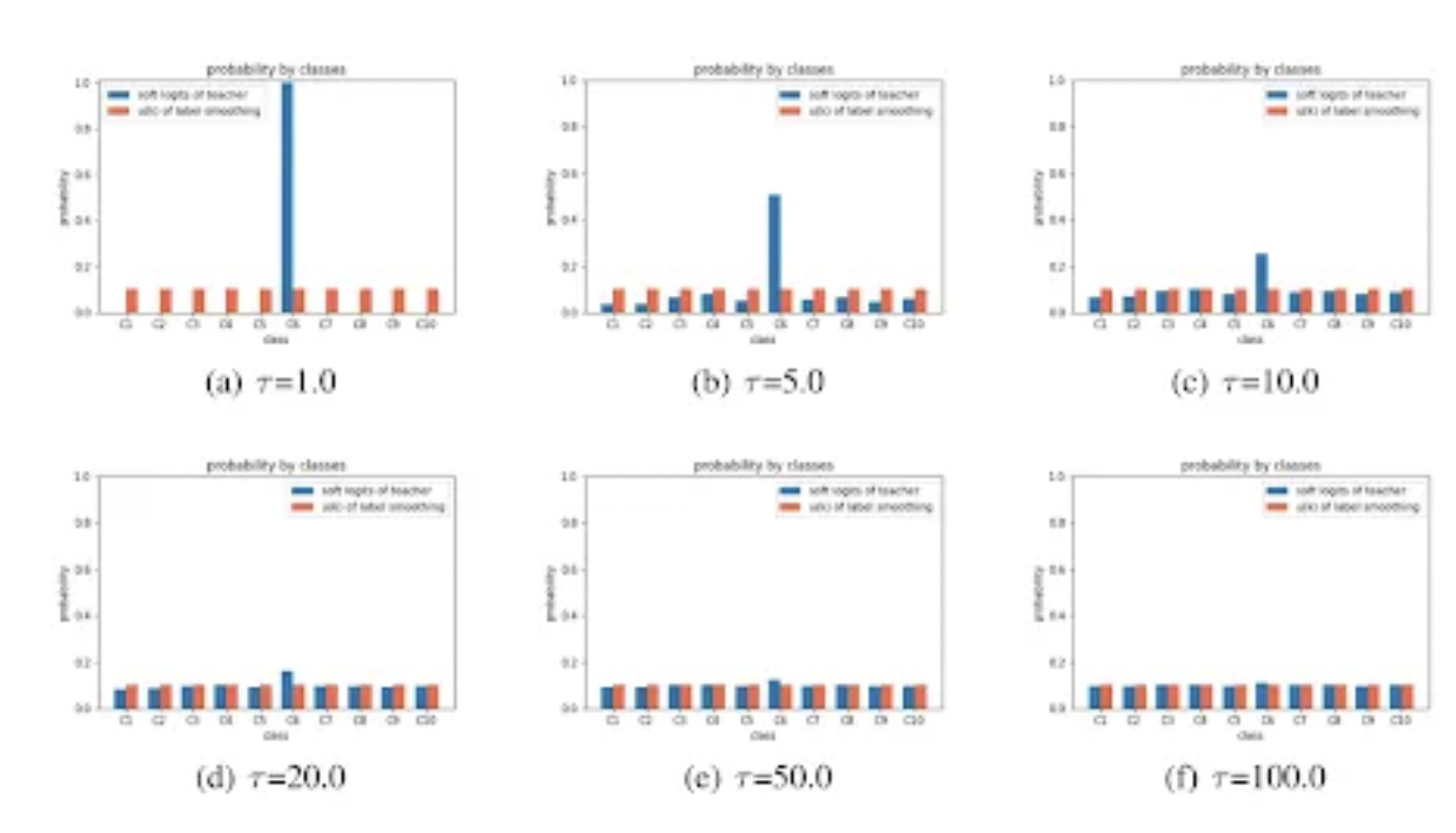
문제는 teacher의 logit값들의 분포가 매우 불균일해서 이를 평탄화하는 작업을 거치면 학습효과가 좋습니다. 이때 temperature라는 개념이 사용되는데 softmax에 들어가는 배열에 temperature라는 일정한 수로 나눠주면 편차가 줄어들게 됩니다. temperature가 높을수록 균일한 logit을 나타내게 됩니다.

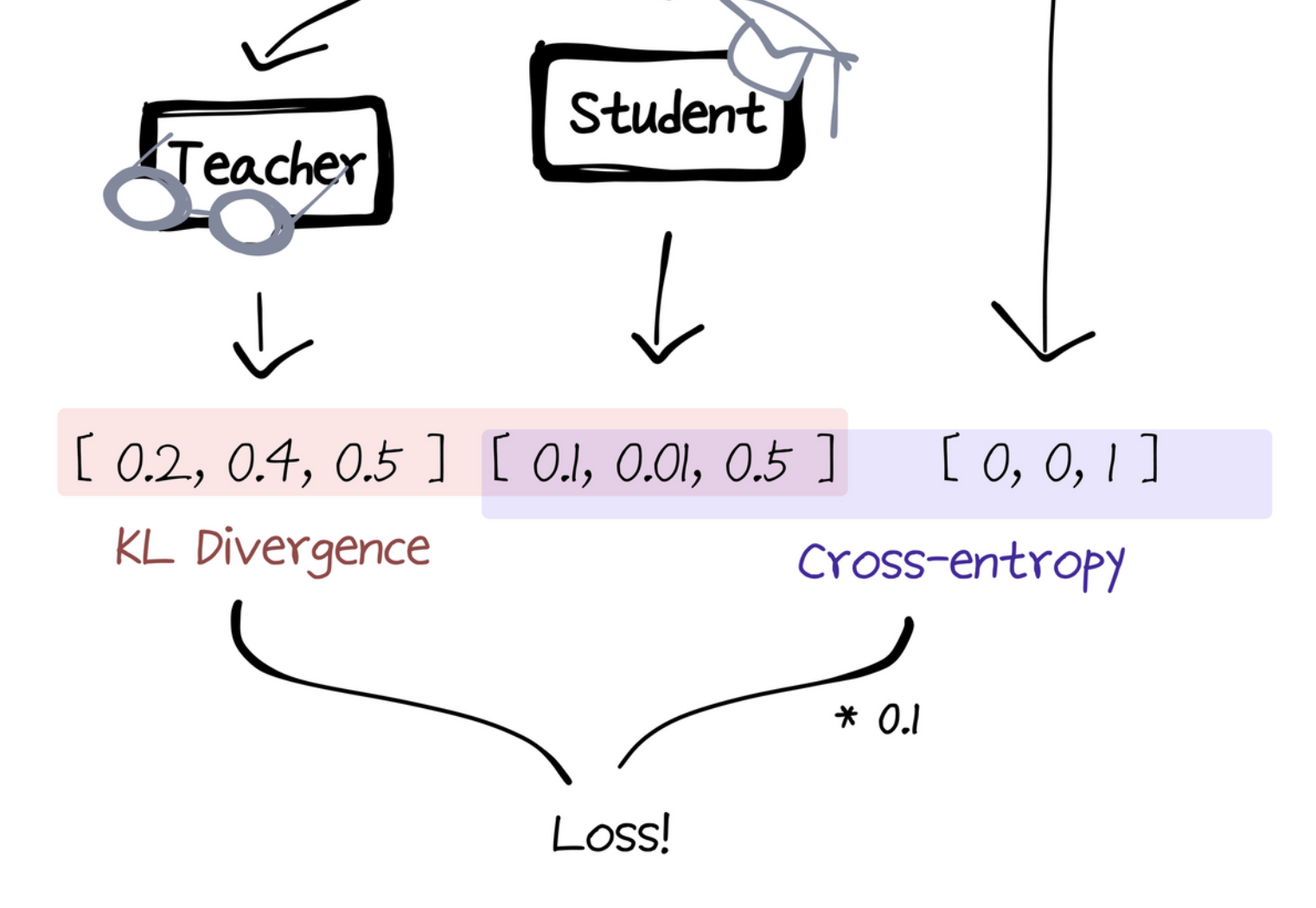
전체 모델의 동작 구조는 아래와 같습니다. 동일한 시퀀스를 Student와 Teacher에 입력시키고 예측한 결과를 KL Divergence Loss로 비교해서 첫 번째 로스를 구합니다. 또한 여기에 실제 정답과의 Student 출력값의 오차 또한 Crossentropy로 비교해서 두 번째 로스를 구합니다. 여기에 두 번째 로스값에 특정한 상수값을 곱해 비중을 줄여주고, 두 로스를 더해주면 모델의 전체 로스를 구할 수 있습니다. 이러한 구조로 학습하며 Teacher의 지식을 Student에게 전달할 수 있습니다.

Ref
https://medium.com/@hintkit/introduction-to-knowledge-distillation-3345b567d121



