안녕하세요.
이번 포스팅은 DROID-SLAM이라는 논문을 리뷰하겠습니다. '21에 발표된 성능 좋은 Deep-based SLAM으로 그 구조를 뜯어보도록 하겠습니다.
Intro

우선 visual SLAM을 살펴보겠습니다. 제가 임의로 나눠보았는데 접근방법에 따라 Direct, Indirect, Deep-based으로 나눌 수 있습니다. Direct같은 경우 보통 photometry error를 통해 optical flow를 구하고 이를 이용해서 Front-end에서 tracking을 합니다. 이거의 모든 pixel을 활용하기에 일반적으로 tracking loss 확률이 indirect보다 적습니다. back-end에서는 optimization을 수행합니다.
반면 indirect 방법은 feature와 그에 대해 descriptor를 뽑아 seq image와 matching을 하고 이를 통해 Front-end에서 tracking을 합니다. 대표적으로 orb-slam의 경우 feature extraction 방법이 orb라서 orb-slam으로 명명되었습니다. 이 후 BA라는 backend를 통해 최적화를 진행합니다. 보통 loop-closure기능이 있습니다.
마지막으로 Deep-based의 경우 사실상 end-to-end로 class method과 비벼볼만한 성능을 가진 모델이 없었습니다. superglue처럼 matching이나 혹은 feature를 뽑는데는 부분적으로 사용되어도 end-to-end로 사용되어 general env에서 높은 성능을 가진 모델은 Droid-SLAM이 스타트라고 생각해도 무방합니다.
Abstraction
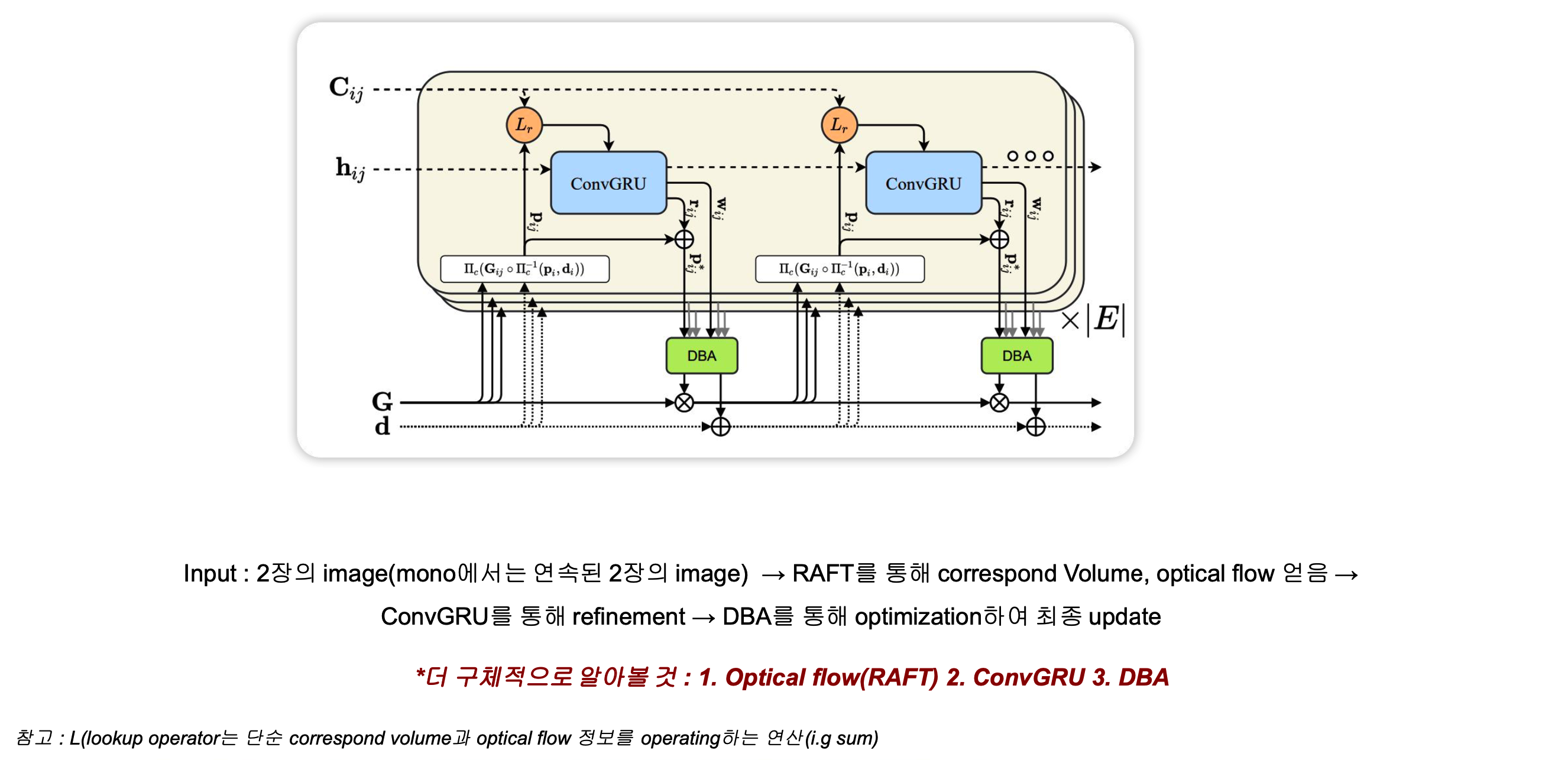
DROID-SLAM의 전체적인 흐름을 먼저 보겠습니다. 위의 그림은 operation unit으로 해당 unit을 반복하여 pose(G)와 depth(d)를 구하게 되는 flow-chart입니다. 우선 2장의 image(mono의 경우 sequence한 두 장의 이미지) 와 첫번째 image를 refence으로 하여 총 3장의 이미지가 input으로 들어가게됩니다. 그 다음 각각 feature extraction과 upsampling단계를 거쳐서 나온 HxW크기의 feature image 2장(reference 이미지 제외) 을 pixel by pixel 로 dot product를 수행합니다. 그렇게 되면 총 크기 HxWxHxW의 correspond volume을 구하게 됩니다. 구한 correspond volume을 서로 다른 4개의 kernel을 통과시켜 종 4D correspond volume을 만들게 됩니다. 위의 그림에서는 notation $C_{ij}$로 표현되어 있습니다.
이렇게 구한 correspond volume과 optical flow를 통해 개선된 pixel위치를 구하고 이를 DBA라는 module에 넣어서 pose와 depth를 incremental하게 구합니다. 자세한 것들은 후술할 예정입니다.
GRU
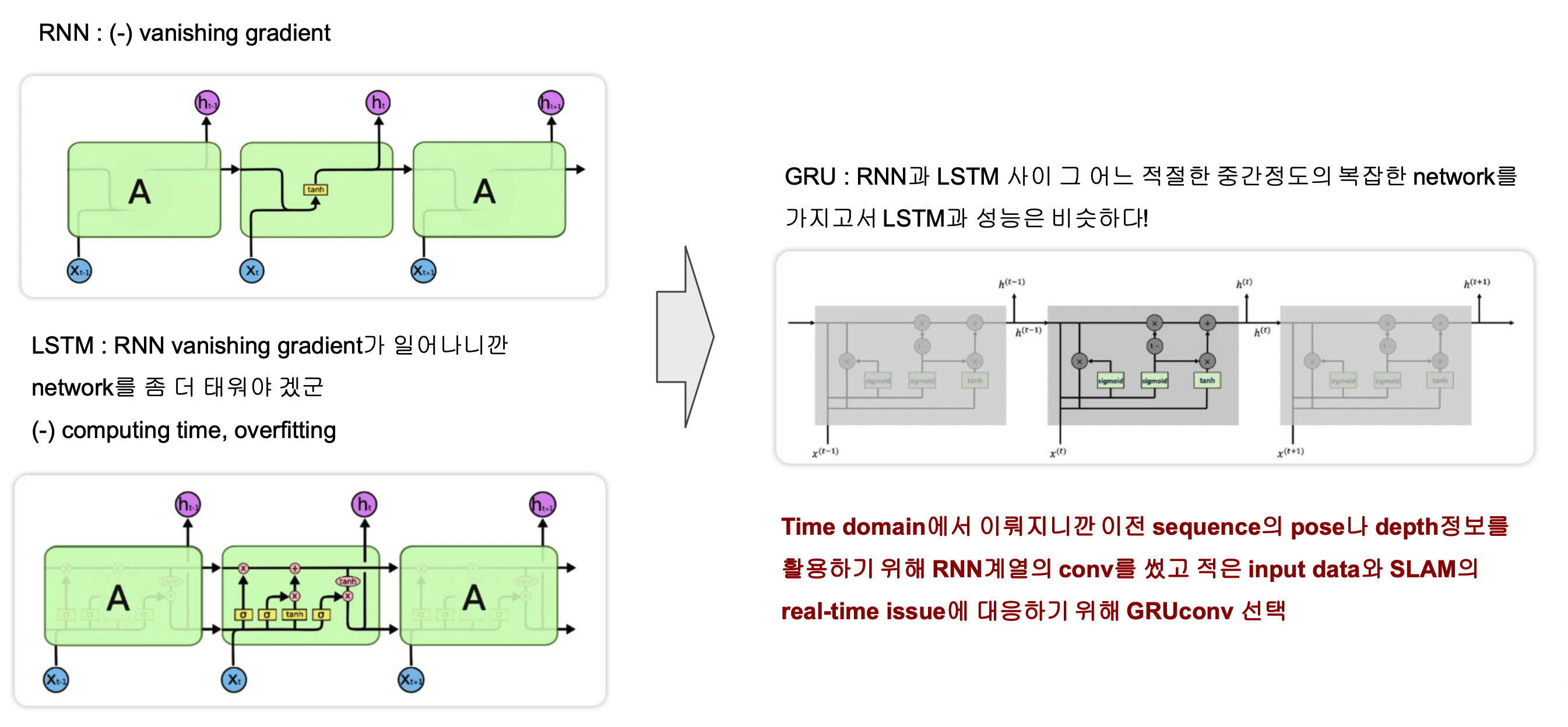
operation unit 그림에서 보면 GRU라는 convolution을 사용합니다. GRU는 시계열데이터에서 쓰는 convolution입니다. 이 쪽에서 가장 유명한 conv는 RNN입니다. 하지만 RNN의 경우 많은 conv를 지나게 되면 vanishing gradient가 일어나 학습이 잘 되지 않습니다. 그래서 나온 녀석이 LSTM입니다. module안쪽을 보면 activateion하나로 되어있는 RNN과 달리 복잡한 구조로 되어있습니다. Hidden layer 입출력도 각각2개 입니다. LSTM의 문제는 복잡한 network에 따른 computing time과 overfitting입니다. RNN과 LSTM사이정도로 복잡하면서 성능은 LSTM과 같은 것이 없을까하여 나온 것이 GRU입니다.
Abstraction에서 보면 operation unit을 반복하면서 pose와 depth를 업데이트합니다. GRU를 통해 이전 unit결과가 forward되면서 마치 GNN과 비슷한 역할을 하게 됩니다.
RAFT
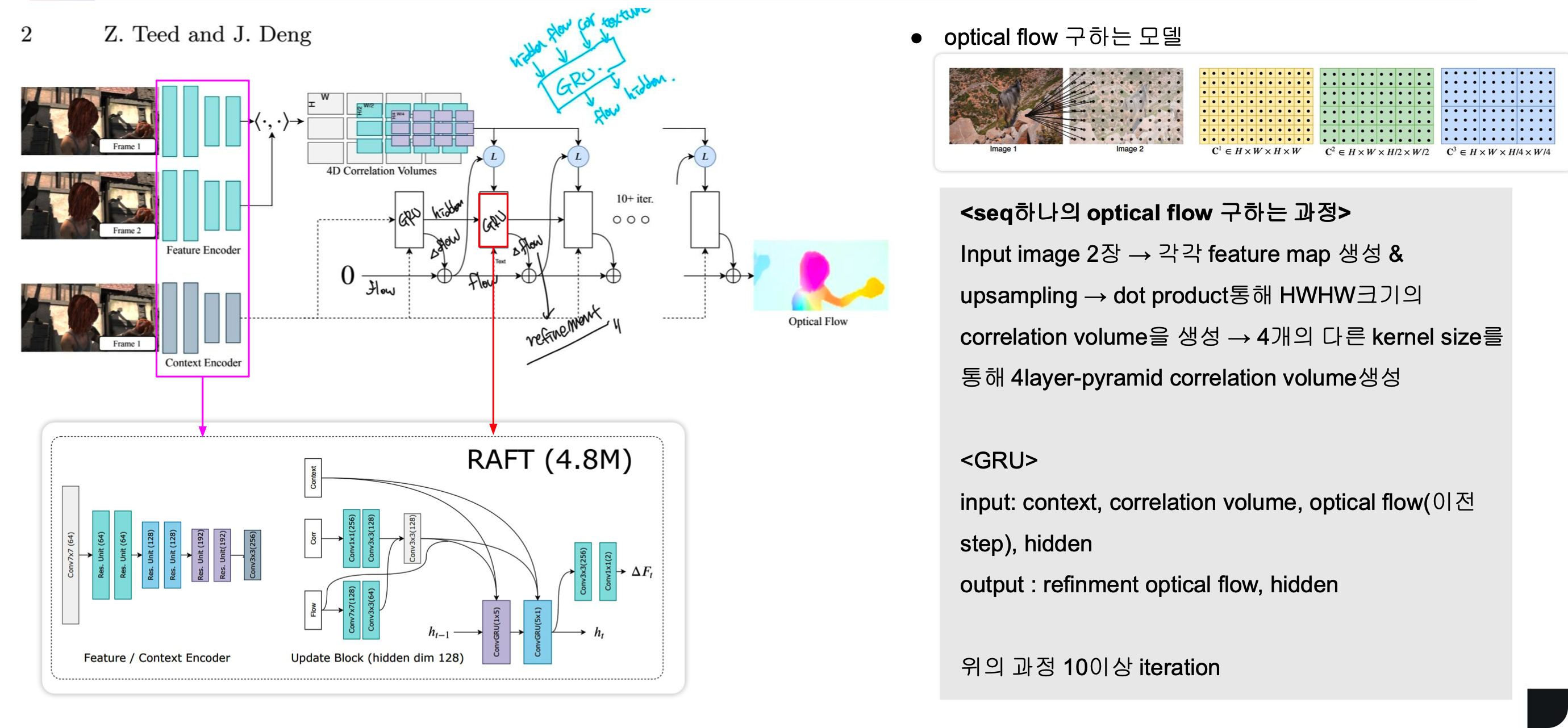
DROID-SLAM의 1저자는 앞서 RAFT의 논문을 발표했는데요 이 RAFT의 pipeline과 DROID-SLAM의 전체적인 pipeline이 거의 동일합니다. 해서 먼저 RAFT를 살펴보겠습니다.
RAFT는 optical flow를 구하는 모델입니다. 먼저 설명한 DROID-SLAM에서 correspond volume을 extraction하는 부분과 마찬가지로 연속된 이미지 2장에서 feature를 뽑고 upsampling하여(HxW 크기) 나온 pixel들을 서로 dot product해 4D correspond volume(HxWxHxW 크기)을 뽑아냅니다.
이제 이렇게 구한 correspond volume은 고정되어 GRU conv에 입력으로 들어갑니다. 좀 더 정확하게는 이전 step의 optical flow와 lookup operator를 거친 후에 GRU입력으로 들어가게 됩니다. loopup operator는 summation과 같은 operator입니다.
또 reference image(첫번째 이미지)를 context 로 하여 GRU의 input으로 들어갑니다. 이후 나온 output은 hidden layer와 refinement optical flow(델타값)으로 input으로 들어갔던 optical flow에 이 refinement 값을 더하여 optical flow를 업데이트 합니다.
이 것을 하나의 unit이라고 하면 이러한 unit을 10번 이상 반복합니다. 그러면서 optical flow값은 점점 refinement되어 정확도가 올라가게됩니다. 즉, input 2장의 이미지가 여러번의 unit을 거쳐 optical flow를 refinement하게 되는 것 입니다.
Update Operator
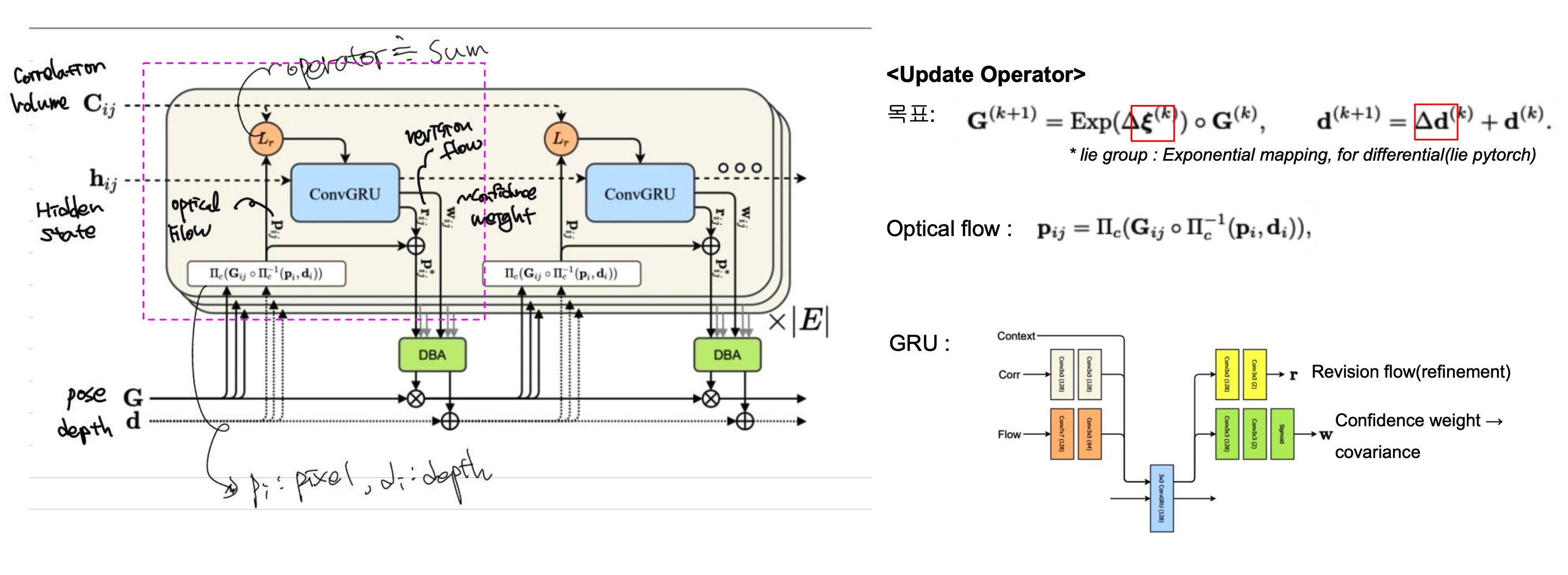
그럼 이제 다시 DROID-SLAM에서 updat operator부분을 살펴보겠습니다. 연속된 이미지를 통해 4D correspond volume은 구한 상황입니다. RAFT와는 다르게 DROID-SLAM의 목적은 tracking입니다. 즉, depth와 pose를 구해야 합니다. 해당 unit을 통해 pose와 depth의 refinement값을 구하게 됩니다. pose같은 경우 lie algebra에서의 4D vector를 구하게 되는데 이는 exponential map을 통해 Lie group으로 매핑할 수 있습니다. 위의 그림에서의 푸사이는 이를 말하는 것입니다. Lie대수의 자세한 내용은 아래 참고하세요
[SLAM] 2.리군, 리대수(Lie Group, Lie Algebra)
안녕하세요. 후니대디입니다. Lie Group, Lie Algebra에 대해서 포스팅하겠습니다. Lie라는 이름이 지어진 이유는 Lie Group에 대한 이론을 정립한 수학자 이름이 Sophus Lie이기 때문입니다. 리군,리대수는
jaehoon-daddy.tistory.com
GRU에 들어가는 input으로 RAFT와 비슷하게 correspond volume과 $P_{ij}$가 들어갑니다. $P_{ij}$는 pose와 depth를 알고있을때 frame1에서 대응되는 frame2의 픽셀입니다. 편의상 optical flow라고 그림에서는 적어놓았습니다.
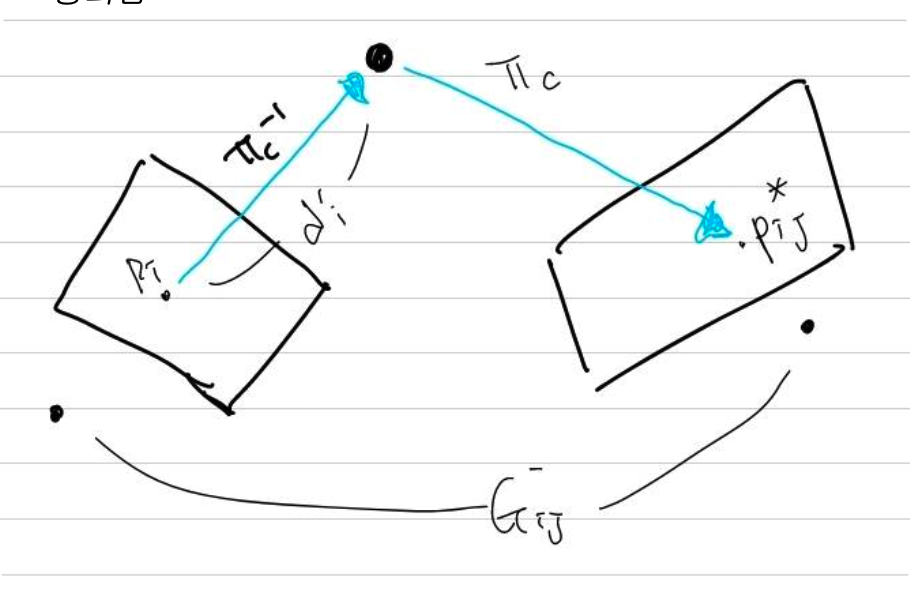
위의 그림을 보면 $P_{ij}$를 구하는 수식이 이해 될 겁니다. $\Pi $는 보통 camera plane으로 projection하는 notation으로 사용됩니다. inverse가 있으니 frame1에서 3D 유클리디언 공간으로 매핑이 되겠고(depth를 알고있으니 projection 공식으로 반대로 하여 구할 수 있습니다.)이를 다시 frame2(frame1에서 G(pose)만큼 이동한 image plane)공간으로 projection한 pixel을 말합니다.
이렇게 구한 $P_{ij}$와 correspond volume이 GRU의 input으로 들어가게 되고 아웃풋으로는 $P_{ji}$의 refinement값과 confidence weight가 출력됩니다. 이 refinement pixel값과 input으로 들어간 pixel값을 더하여 업데이트를 진행합니다. 그렇게 업데이트된 픽셀값과 DBA과정을 통해 pose refinement, depth refinement값을 최종적으로 얻게 됩니다.
DBA
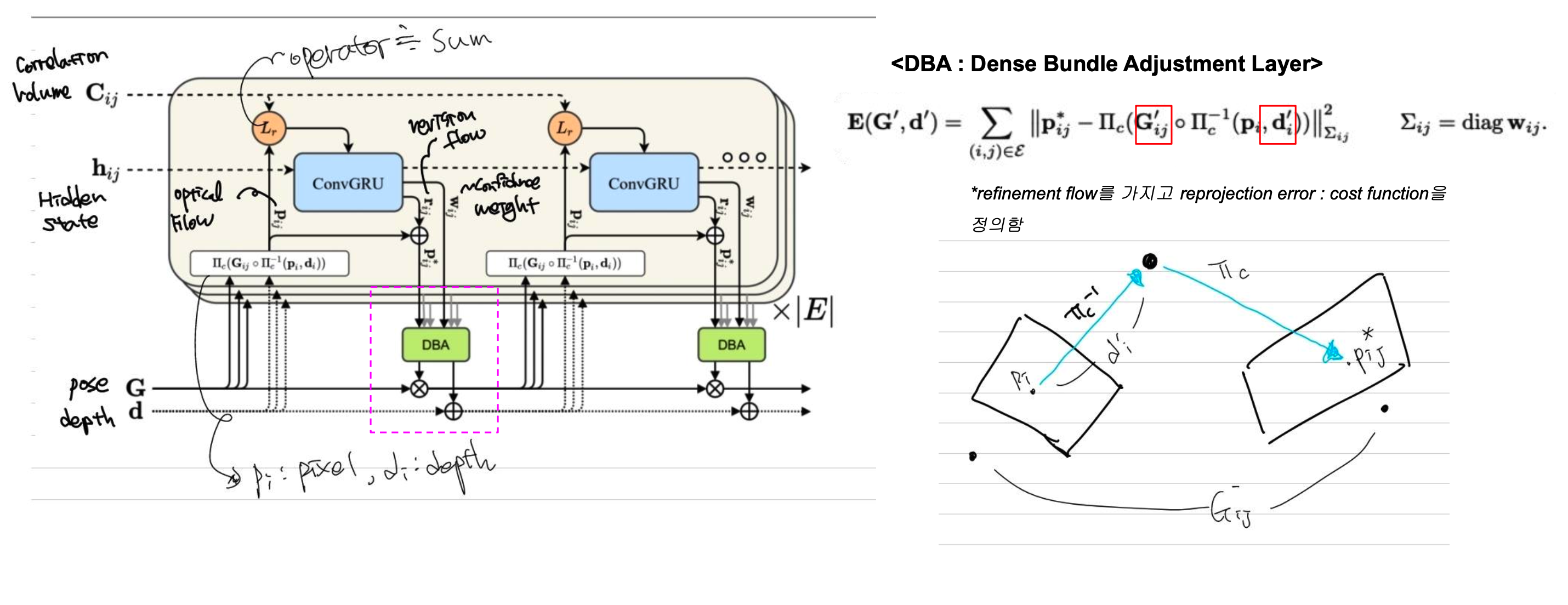
그럼 마지막으로 DBA대해서 알아보겠습니다. 위의 과정을 통해 $P_{ij}$값을 업데이트 하였습니다. 우리가 원하는건 pose와 depth의 refinement값이고 알고 있는건 refinement된 pixel의 위치 입니다. 따라서 위의 E라는 식을 통해 pose와 depth의 refinement를 구하게 됩니다.
엄밀히 말하면 DBA는 end-to-end에 속해있는 모듈이지만 그 자체는 학습하는 파라미터는 아닙니다.
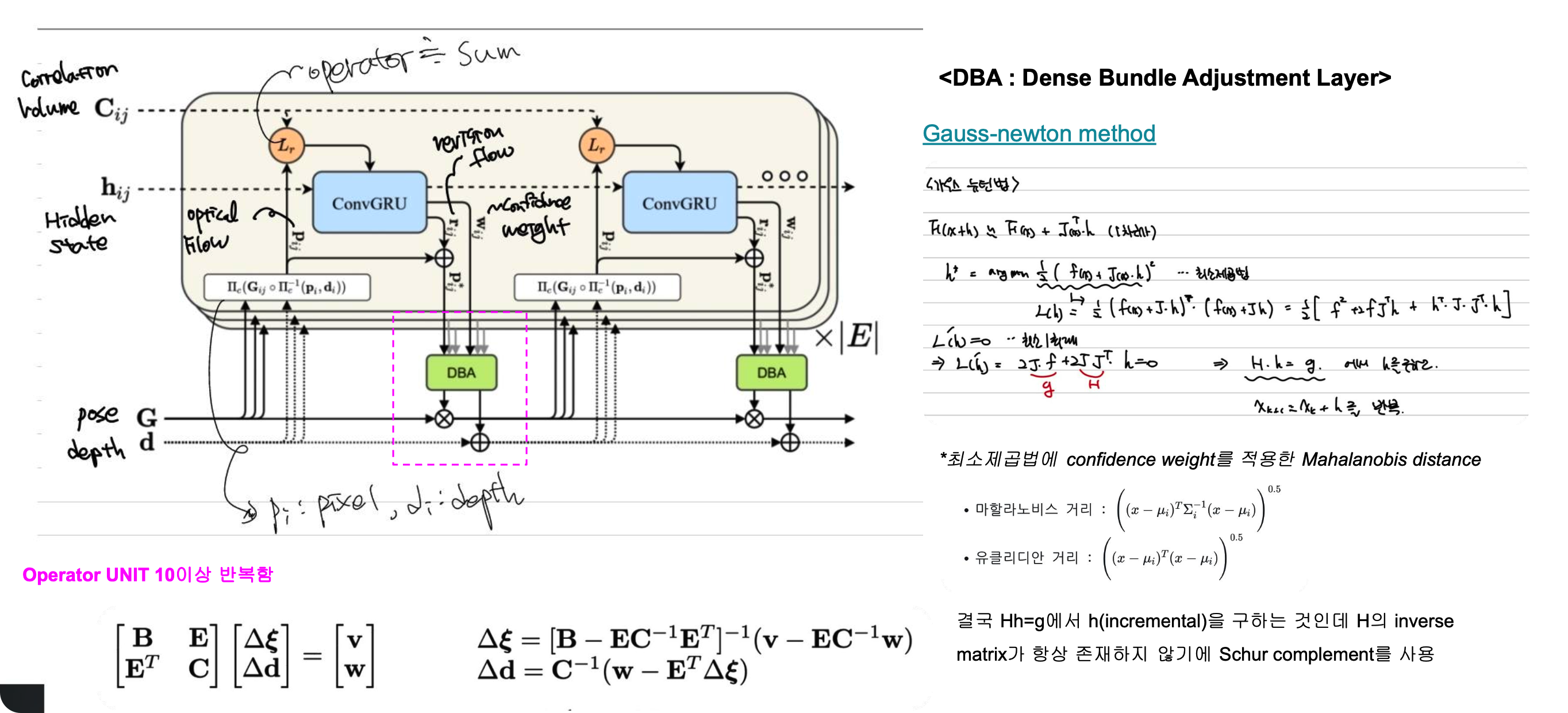
그러면 위의 E라는 식을 좀 더 알아보겠습니다. 여기서부터는 BA(bundle adjustment)내용과 동일합니다. E라는 식에서 우리는 G와 d term을 변수로 놓습니다. 그리고 gauss-newton법을 통해 incrementally G(pose), d(depth)값을 update해 나갑니다.
이에 대한 자세한 과정은 아래 첨부하였습니다.

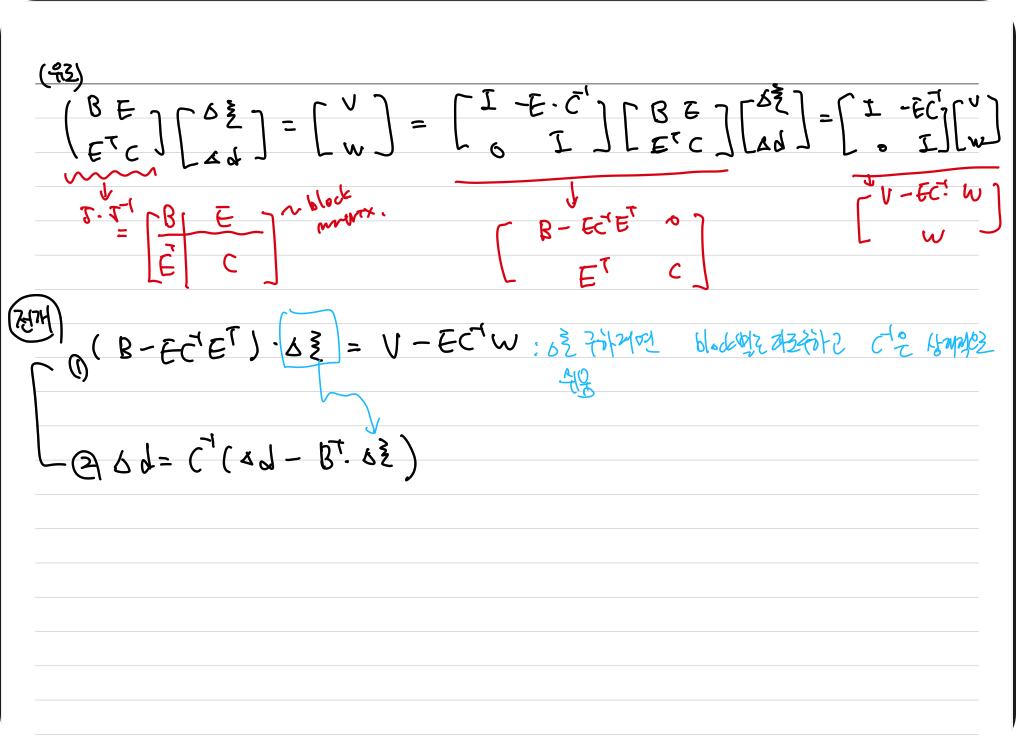
해당 과정은 한번의 sequence과정에서 일어나는일이며 unit operator는 여러번 반복하여 최적의 pose, depth를 구하게 됩니다.
Training / Experiments
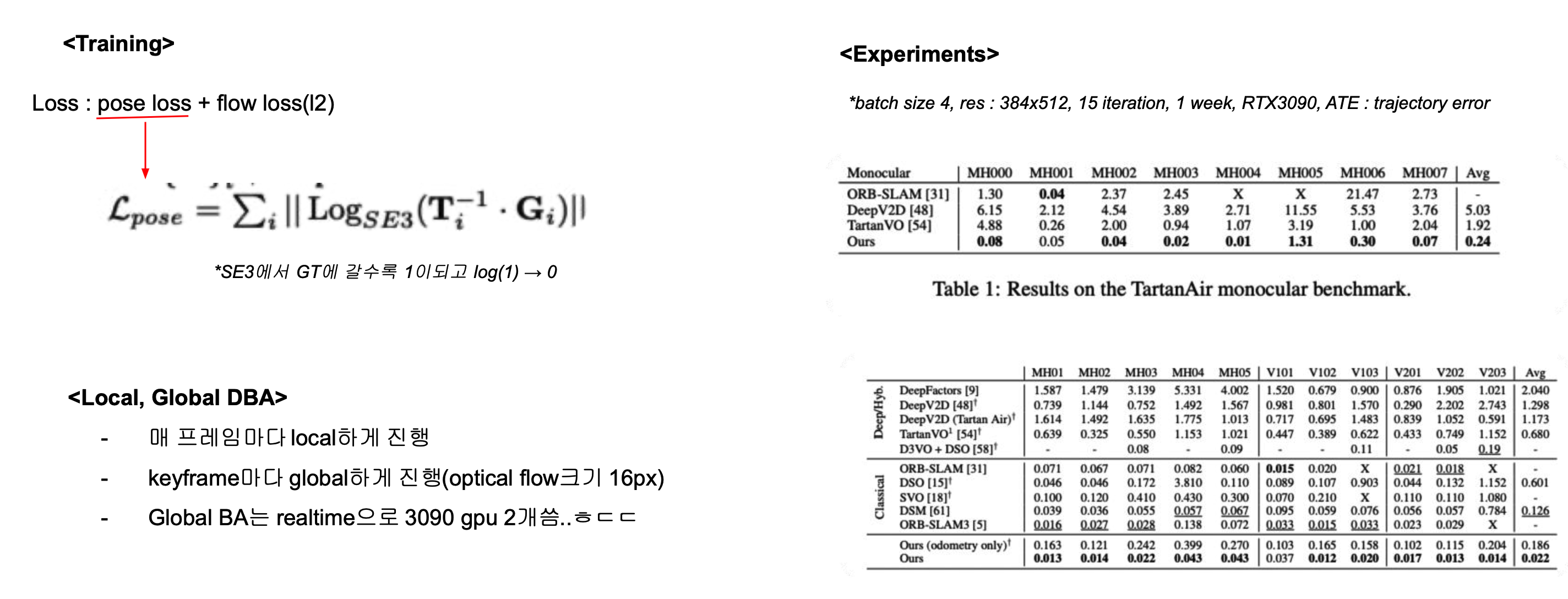
network 전체의 loss function으로는 pose와 optical flow의 loss를 합하여 정의하였습니다. pose loss에서 T는 estimation transform matrix이고 G는 GT입니다. GT에 가까워 질수록 두 matrix의 곱은 1에 가까워 질 것이고 전체적으로는 0에 가까워 질 것 입니다.
optical floww loss의 경우 pose, depth를 알고있으면 이를 통해 optical flow를 구할 수 있습니다(단순 픽셀을 차이). 이를 GT optical flow와 L2 distance를 loss로 하였습니다.
실험결과를 보면 놀랄만하게 성능이 좋습니다. 이를 위해 3090으로 일주일정도 학습을 하였다고 합니다. DBA가 위의 unit operator에서는 unit마다 한번씩 두개의 프레임만으로 작동되는데 global하게도 적용하였다고 합니다. dense points를 map points로 사용하고 있어서 연산량이 엄청날거라 생각했는데 역시 3090 두개로 global ba는 돌렸다고 합니다. 이것도 부족해서 엔지니어링적인 테크닉을 더했다고 합니다.
End-to-End로 이 정도의 성능이면 Pose가 prior로 필요한 nerf등에 같이 사용하여 full pipeline을 설계하는것도 가능은 할 것 같습니다.
감사합니다.




