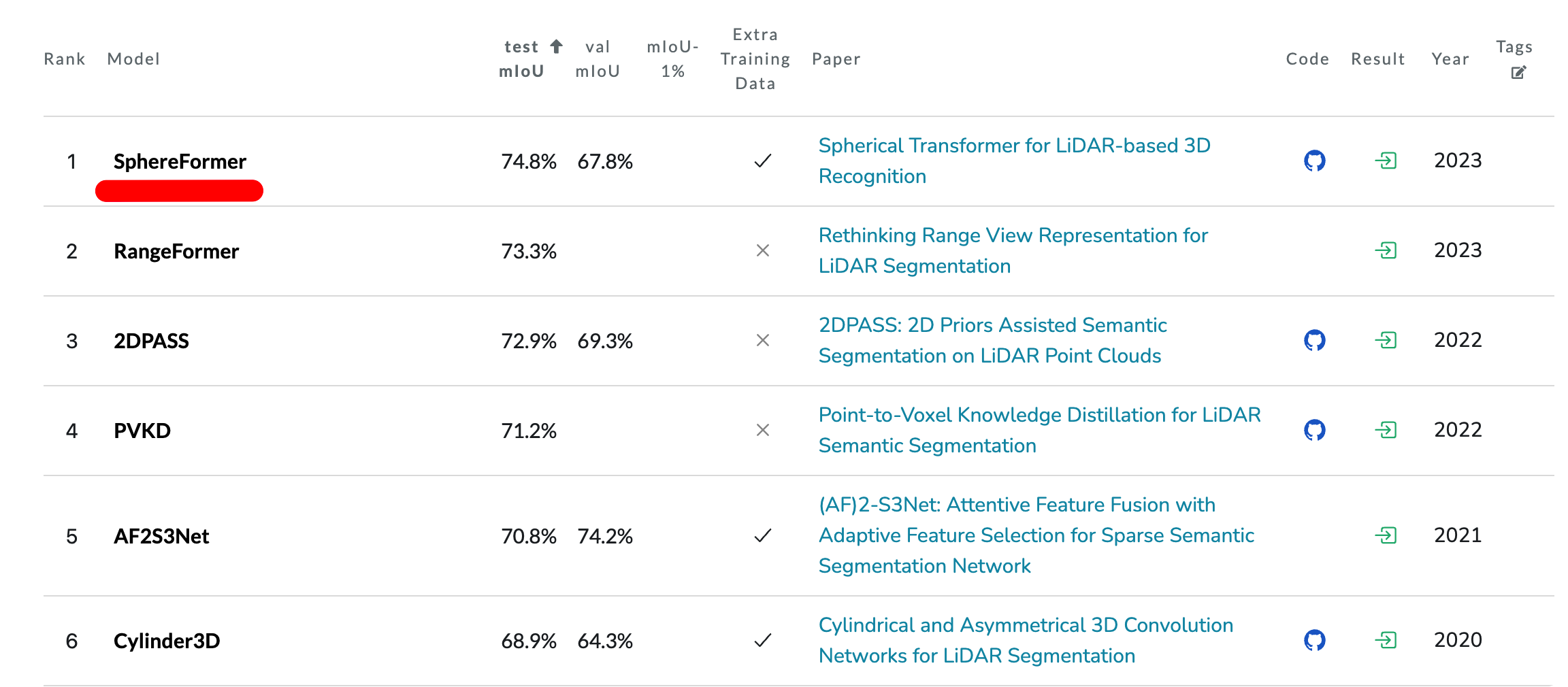
포스팅할 논문은 현재 기준 semantic segmentation leaderboard인 sematic KITTI에서 SoTA 성능, NuScenes 데이터에서는 rank2 에 랭크되어 있는 Spherical Transformer 모델입니다.
해당 논문은 기존의 transformer를 사용한 segmentation 모델의 약점인 SPARSE DISTANCE POINTS를 radial window self-attention을 이용하여 문제를 푼 모델입니다.
Intro
기존의 방법들은 local operator를 사용하거나(SparseConv), 2D CNN등을 응용하여 사용하였습니다. 이 방법들은 sparse distant point문제의 해결에 굉장히 취약합니다. 그 원인은 receptive field가 제한되어 있다보니 발생할 수 밖에 없습니다.

이를 위해 window self-attention(sparse transfomer, statify transfomer), dislated self-attention, large-kernel CNN등 방법이 있지만 근본적으로 해결하진 못했습니다.
해당 논문에서는 위의 그림(B)처럼 trasnformer의window를 sphearical 형태로하여 receptive field를 최대한 넓히는 방향으로 하는 전략을 제시합니다.
Prior Knowledge
Transfomer
이 후의 내용을 보기전에 최소한의 transformer에 대한 이해도가 필요합니다.
[Transformer] Transformer & Vision
안녕하세요. 이번 ML관련 포스팅에서는 Transformer관련하여 포스팅하겠습니다. 이미 나온지 꽤 오래되었고 많은 분야에서 활용되고 있는 아키텍쳐인데요. NLP분야에서 일찍이 탄생했지만 비전 및
jaehoon-daddy.tistory.com
요약하자면 Transformer는 기존의 RNN계열의 모듈처럼 encoder에서 입력 시퀀스들을 입력받고 디코더에서 출력 시퀀스를 출력하는 구조입니다.
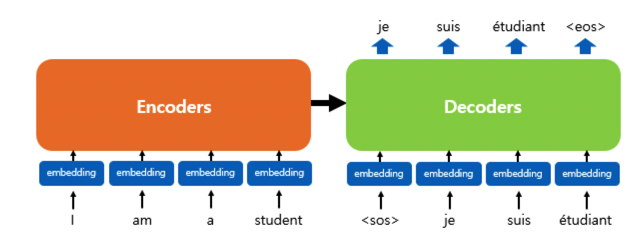
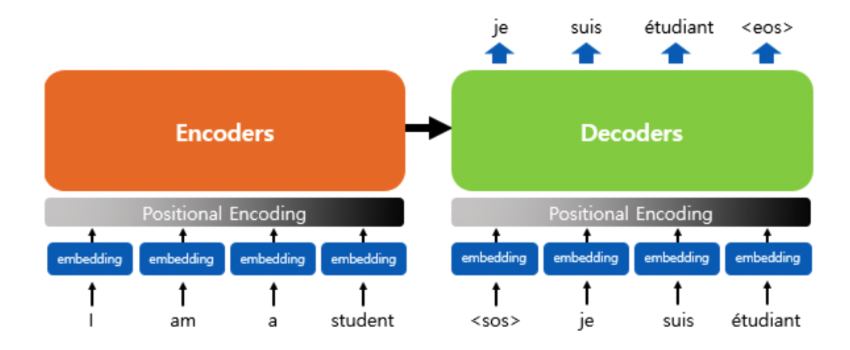
좀 더 구체적으로 encoder에 들어가는 input들을 imbedding화 시키고(쉽게 숫자로 이루어진 vector로 만든다는 의미입니다) 여기에 positional encoding을 더해 각각 input의 위치 정보까지 추가합니다.

위의 그림은 encoder와 decode가 어떻게 생겼는지 구체적으로 보여주는 그림입니다. encoder는 MHA1개와 FeedForward 1개로 이루어져있고 decoder는 MHA2개와 FF 1개로 이뤄져있습니다.
그럼 다음으로 self-attention을 들여다보겠습니다. self-attention을 통해 input들끼리의 맥락을 알게됩니다. 여기서 q,k,v가 사용됩니다.
각각의 input은 q,k,v를 가지고 있고 qw,kw,vw가 학습을 통해 이들을 업데이트 합니다. 각각의 input의 q는 다른 input의 k와 dot하여 score를 구하고 softmax를 합니다. 이 값에 v곱하고 이렇게 얻어진 값들을 합해 버립니다.
이 과정은 한번의 attention block의 과정이고 여러개가 있으면 n개만큼의 z가 얻어집니다. 이를 concat하여 최종 z를 만든후에 FF layer로 보내지게 됩니다. (FF layer는 단순 MLP layer 덩어리 입니다.)
ViT
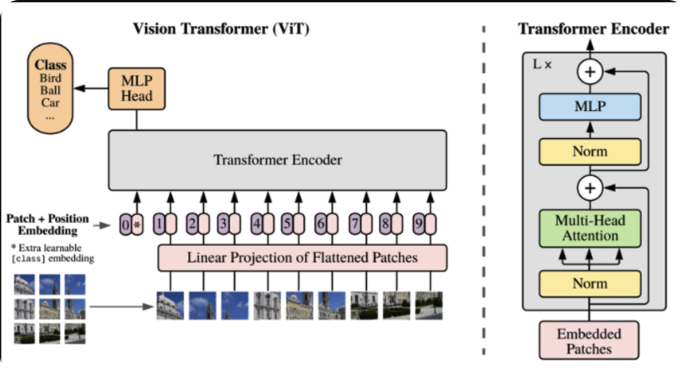
Vit는 Transfomer를 활용한 초기의 Vision classification Model입니다. 개요만 살펴보면 위의 transformer에서 encoder부분만 떼어온 형식입니다. 이미지를 patch단위로 자르고 patch마다 position embedding정보를 더하여 input값들을 embedding화합니다. 이 후 위에서 설명한 encoder에 들어가 self-attention과정과 FF(MLP)과정을 거쳐나온 output에 MLP head를 붙여 classification하는 형식입니다.
swin-transformer
swin-transformer는 window라는 개념이 사용됩니다. 기존의 ViT가 이미지의 해상도가 커질수록 모든 patch 조합에 대해 self-attention을 수행하는 것의 computation cost가 커집니다. 이를 해결하기 위해 swin-transformer는 hierarchical feature map을 구성합니다.

마치 CNN이 layer가 깊어질수록 넓은 범위의 locality를 갖는 거처럼 다양한 윈도우를 layer마다 적용하고 window안에서만 self-attention을 수행하게 됩니다.
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks

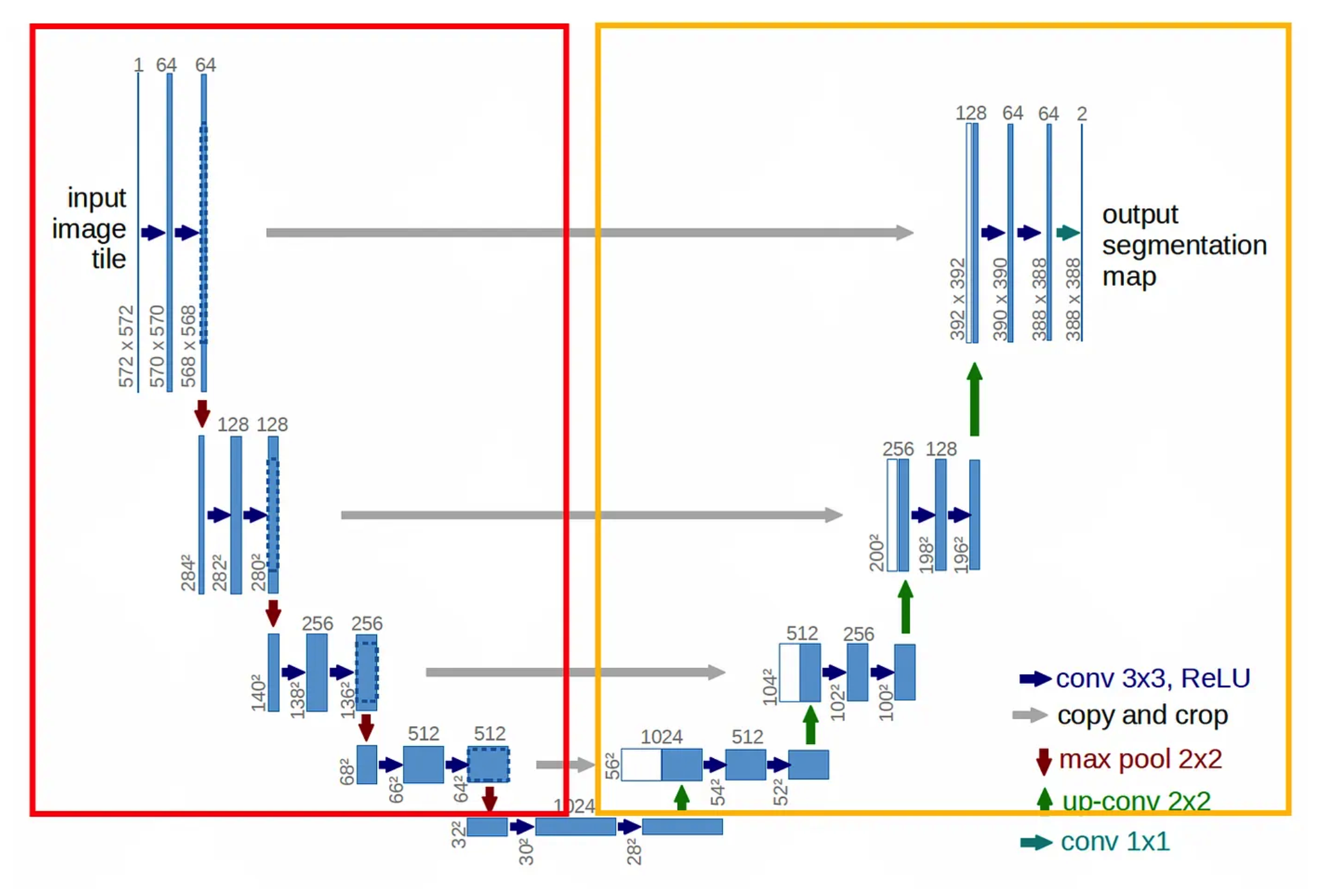
spherical transformer에서 baseline으로하는 모델입니다. U-net과 비슷한 encoder-decoder구조로 voxel기반으로히여 spconv3d를 거쳐 점점 downsampling후에 다시 upsampling하여 voxel-wise cross-entropy loss를 사용하는 구조입니다.
SPVNAS
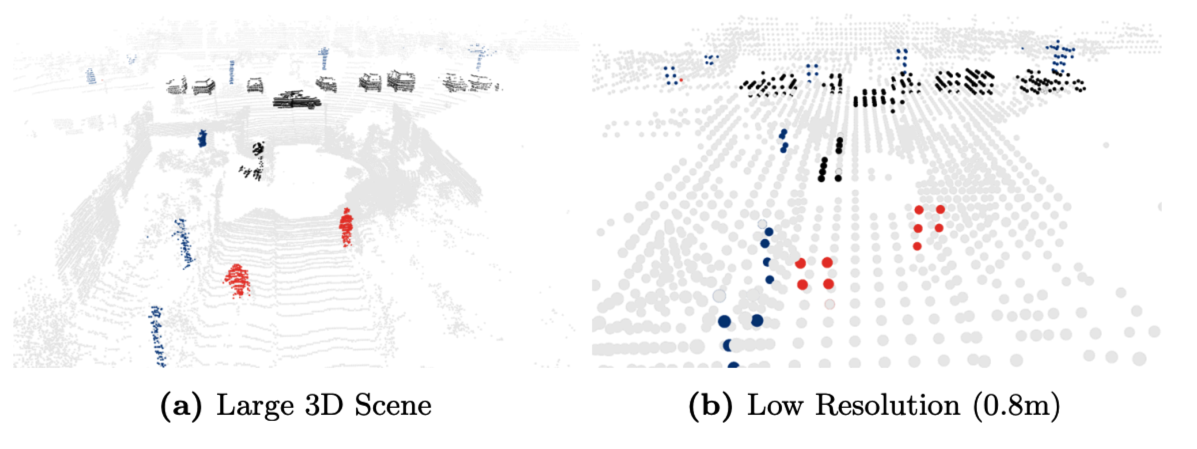
기존의 low-resolution voxelization은 small instances의 경우 detection하기가 chanllenge합니다. 특히 segmentation인 경우 더더욱 그렇습니다. SPVNAS는 이를 해결하는 것을 목적으로 한 module입니다. feature extraction할때 point-base는 computation cost가 문제이고 voxel-base는 information loss의 단점이 존재합니다. 즉, low-cost, high-resolution을 목적으로하는 point-based conv 입니다. spvnas는 voxel기반의 sparseconv 모듈을 빠르게 처리하도록 개선하고 voxel feature와 point base feature를 fusion하여 segmentation하는 방법입니다.

제시된 sparseconv는 기존의 많이 쓰는 spconv(second model에서 제안된 방법)대비 빠른 성능을 나타냅니다.
Spherical Transformer


논문의 순서와 다르게 전체적인 모델의 구조를 보겠습니다. 참고로 해당 그림은 supplement paper에 별도로 있습니다.
위에서 설명한 U-net기반의 아키텍쳐에서 encoder의 각각 5번의 block의 제일 마지막에 논문의 주요 내용인 sphereFormer가 적용됩니다. 즉 작은크기의 voxelization을 하고 spvconv3d를 거치면서 점점 downsampling합니다.(encoder) block의 제일마지막에는 sphereFormer가 적용되어 distant sparse points와의 관계를 학습하게 됩니다. 이후 decoder에서는 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks의 논문과 같이 u-net의 decoder와 동일합니다. loss는 voxel-wise cross-entropy를 사용합니다.(정확한건 코드확인 예정입니다)
그럼 SphereFormer를 살펴보겠습니다.
SphereFormer

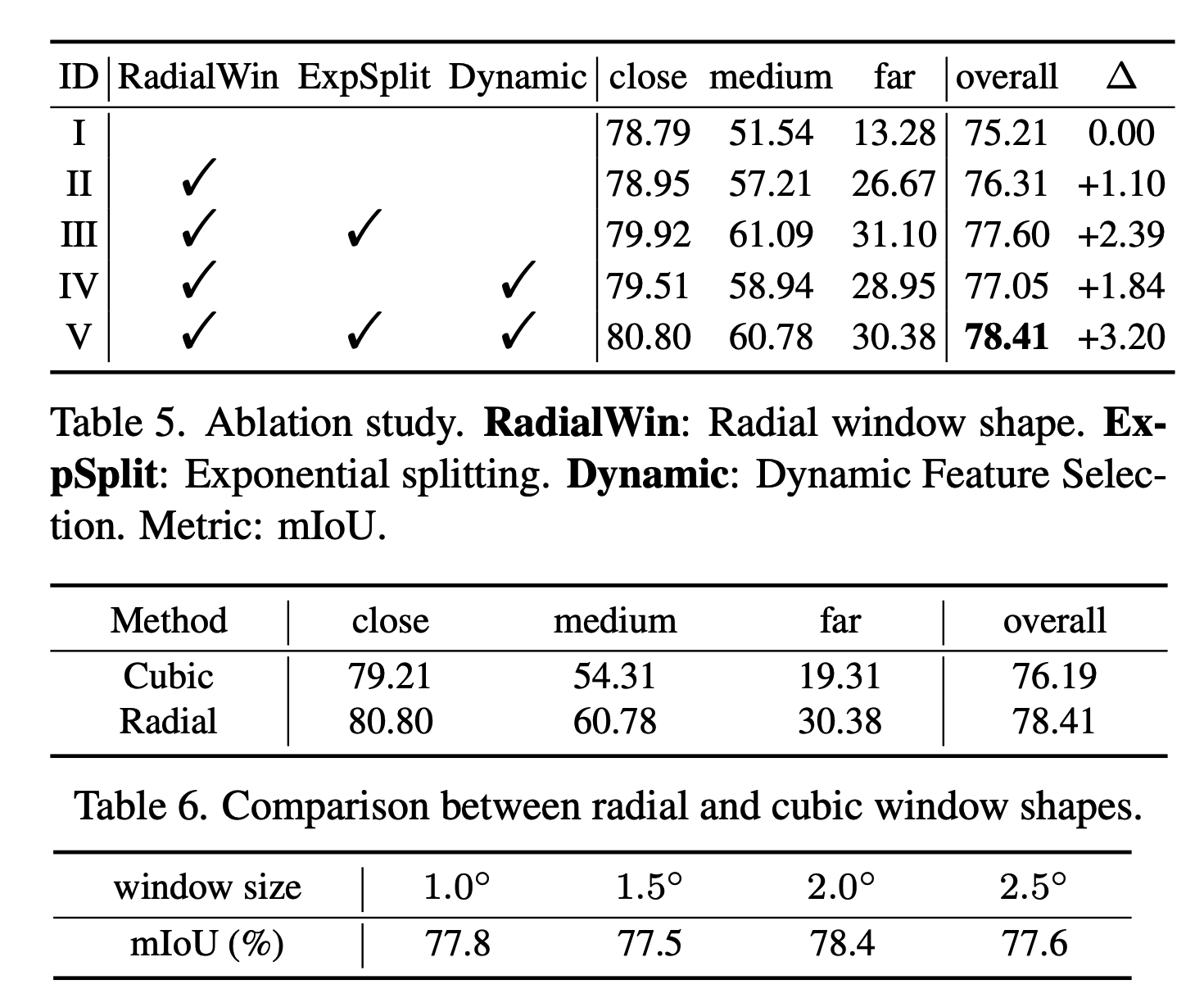
해당논문은 위에서 소개한 window기반의 transformation을 사용하였습니다. 하지만 기존의 cubic스타일의 window가 아닌 pyramid형태의 non-overlap window를 사용하였습니다.위에서 언급했듯, 모든 쿼리 포인트들은 자신 window 영역에서만 처리하기 때문에 vanila version에서는 제한된 effective receptive filed 때문에 문제가 있었습니다. 즉 long range contextual dependency를 해결하지 못했습니다. 간단한 해결책은 window 사이즈를 확대하는 것이지만 사이즈가 커지면 attention해야하는 feature들의 개수가 많아지기에 memory문제가 생깁니다. 해당논문에서는 radial window를 제시하게 됩니다.
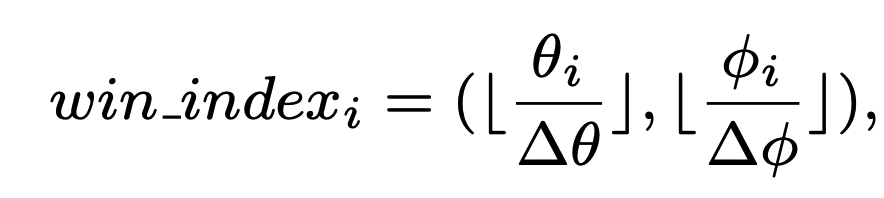
swin-transformation에 언급한 것과 비슷하게 연산량 문제로 global attention이 아닌 같은 window에 있는 feature들끼리 아래와 같이 self-attention과정을 거칩니다.
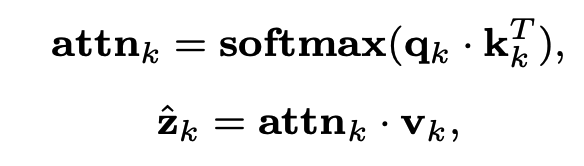
위의 attention을 여러개 적용한 multi-attention을 통해 나온 latent를 아래와 같이 concat합니다.
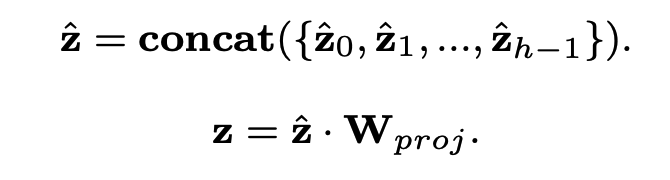
Position Encoding
attention에 들어간 feature는 point-base기 때문에 에초에 xyz position을 포함하고 있기에 별도의 position encoding이 필요하지 않다고 말합니다. 하지만 high-level feature로 갈수록 position 정보가 소실될 우려가 있기에 stratify transformer에서 적용한 relative positioning을 reference로 하여 context-based adaptive relative positional encoding을 진행합니다.
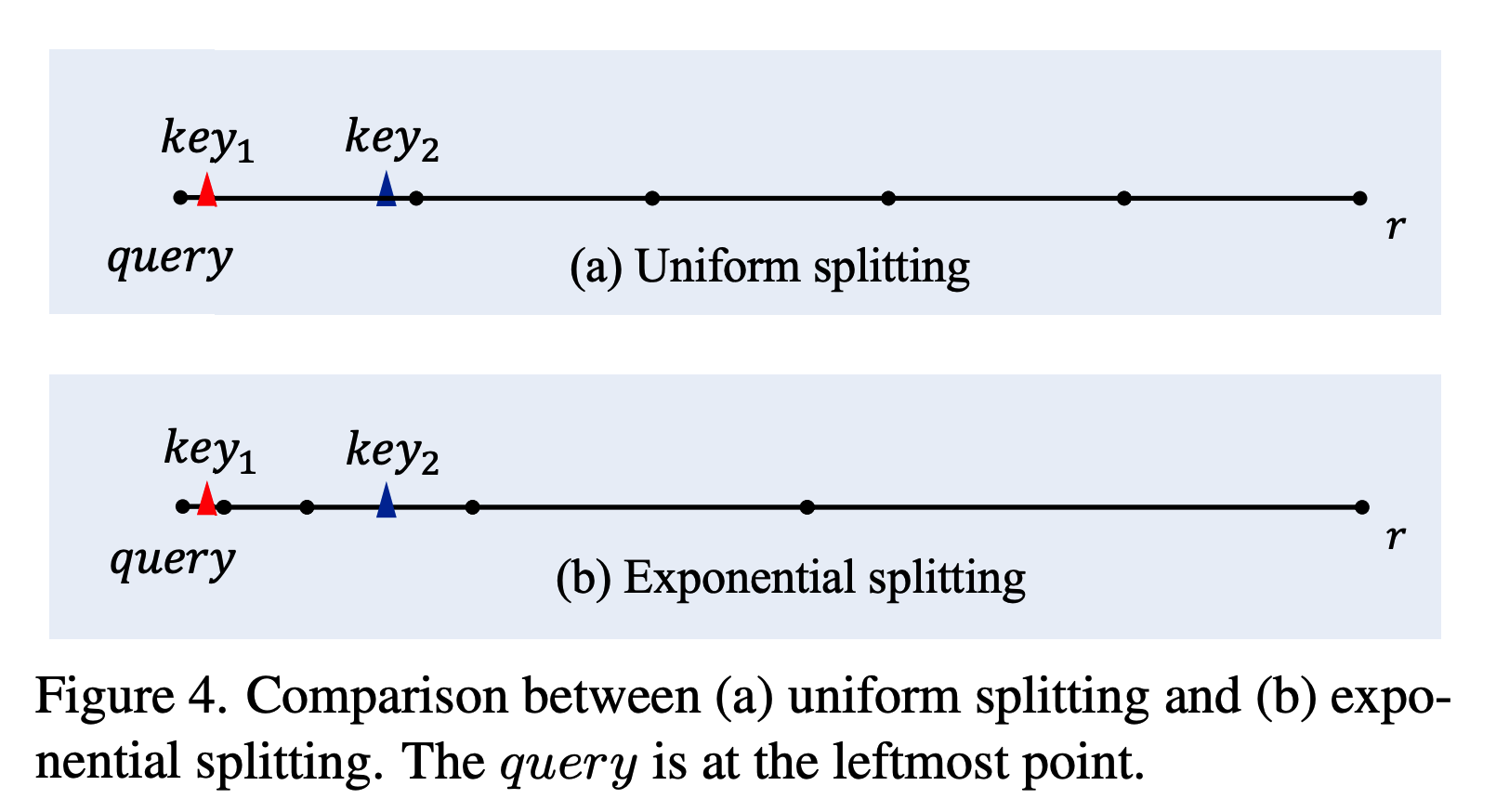
원통좌표계 기준으로 같은 window내에서 다시한번 공간을 쪼갭니다. r의 경우는 공간을 exponential split으로 가까이에는 짧게 자르고 먼거리에서는 크게split을 합니다. 세타와 파이는 uniform하게 공간을 나눕니다. 이후에 look-up table을 만들어서 r,세타,파이에 대해 각각 공간마다의 차이를 아래와 같은 수식에 대입하여 integer화 합니다. 이렇게 만든 index로 look-up table 즉 일종의 hash table을 만들어서 index와 실제 relative position ($\r_{ij}$, $\theta_{ij}$) 를 매핑합니다.

이후에 보통의 position encoding처럼 input data를 embedding할때 concat하는 것이 아니라 attention을 진행할때 look-up table에서 해당하는 position을 찾고 pos_bias라는 이름으로 sum하게 됩니다.

Dynamic Feature Selection
마지막으로 DFS단계에서는 위에서 설명한 radial window 방법과 cubic window방법을 섞어줍니다. 다양한 contextual information을 얻기 위해서라고 합니다.

n의 attention head가 있으면 반은 radial window로 나머지 반은 cubin window로 contextual latent를 구하고 이를 concat합니다.


Experiment

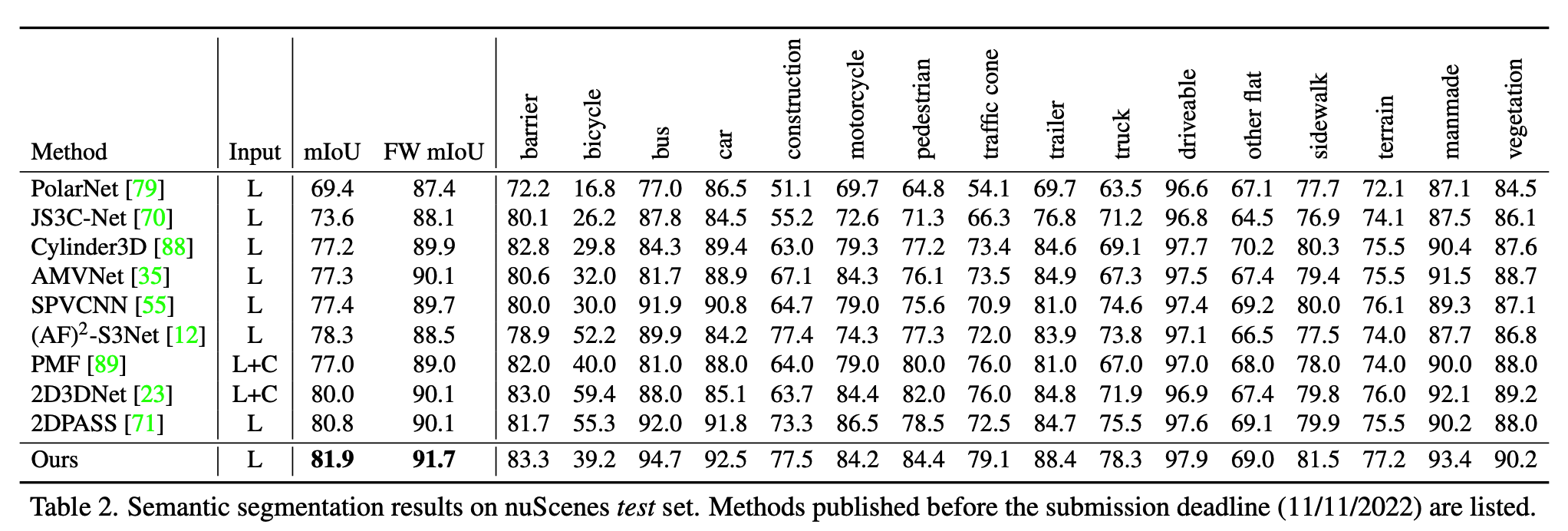
위의 실험결과는 segmentation결과입니다. (semantic KITTI와 nuscenes)

위의 실험결과는 sphereFormer를 detection backbone으로 활용한 결과합니다. segmentation처럼 월등하게 높진 않은 것 같습니다. 비교군 Model도 적구요.
전체적으로 요약하면 기존의 3D segmentation 의 U-Net구조의 encoder block에 distant sparse points의 contextual information을 알기위해 radial 기반의 window의 transformer를 사용한 모델입니다.
실험결과를 보면 detection에서는 transformer를 사용한 모델들의 성능이 그렇지 않은 모델에 대비하여 segmentation 대비 그렇게 뛰어나지는 않은 것같습니다. 이는 아무래도 outdoor의 detection의 경우 distant sparse point의 contextual information의 정보가 그리 중요하지 않아서라고 추측할 수 있겠습니다. 즉 일정범위내의 local feature들간의 context 만으로도 충분하다는 뜻이기도 합니다.




