![[paper review] Text-to-3D Using Gaussian Splatting(GSGEN) 논문리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FmSgfd%2FbtsBojiFDSb%2F2KnxxxxRysRKBRn2IIo1N1%2Fimg.png)
안녕하세요. 이번 포스팅은 text-to-3D의 분야의 논문인 GSGEN을 리뷰해보겠습니다. 제목에서 알 수 있듯이 Gaussian Splatting을 사용한 방법론이고 칭화대에서 ICLR '24에 발표한 논문입니다.
사전에 현재 Text-to-3D의 기반이 되고 있는 DreamFusion논문을 보시면 좋습니다.
[Paper Review] DreamFusion 논문 리뷰
안녕하세요. 오늘 포스팅할 논문은 DreamFusion으로 google에서 ICRA'23에 publish한 Text-to-3D 논문입니다. 최근 multi modal generative model의 발전이 눈부시고 여러 글로벌 기업에서 하루가 멀다하고 이와 관련
jaehoon-daddy.tistory.com
Intro
기존의 text-to-3D model들을 collapsed geometry 문제와 limited fidelity의 문제를 겪고있습니다. 이는 기존의 DreamFusion계열들이 3D prior들을 incorporate할 수 없기 때문입니다.
이를 위해 nerf와는 다르게 explicit한 method인 Gaussian Splatting과 pointcloud diffusion 모델을 활용합니다.
아키텍쳐는 2-stage로 이뤄져있으며 1에서는 Gaussian optimize과정이고 2에서는 fine-tune과정이라고 합니다. 아래에서 이에대해 자세히 보겠습니다.

preliminary
SDS loss에 대해 간략하게 리마인드 하면 generator(nerf)의 parameter를 업데이트하는 loss입니다. 기존의 diffusion loss에서 input에 generator(nerf)에서 rendering된 이미지가 입력되는데 이를 generator의 파라미터를 업데이트하는 방향으로 다시 쓰여진 loss입니다.


Gaussian Splatting은 nerf와 마찬가지인 novel view synthesis 모델인데 explicit하게 접근합니다.

position, covariances, color, opacity를 input으로하여 3D gaussian을 3D 공간상에 뿌리고 이를 image plane에 projection합니다. 이후에 screen을 16x16 패치로 나눈후 Gaussian을 위치 기준으로 sorting합니다. 이 후에는 point-based volume rendering을 적용합니다.
Geometry Optimization
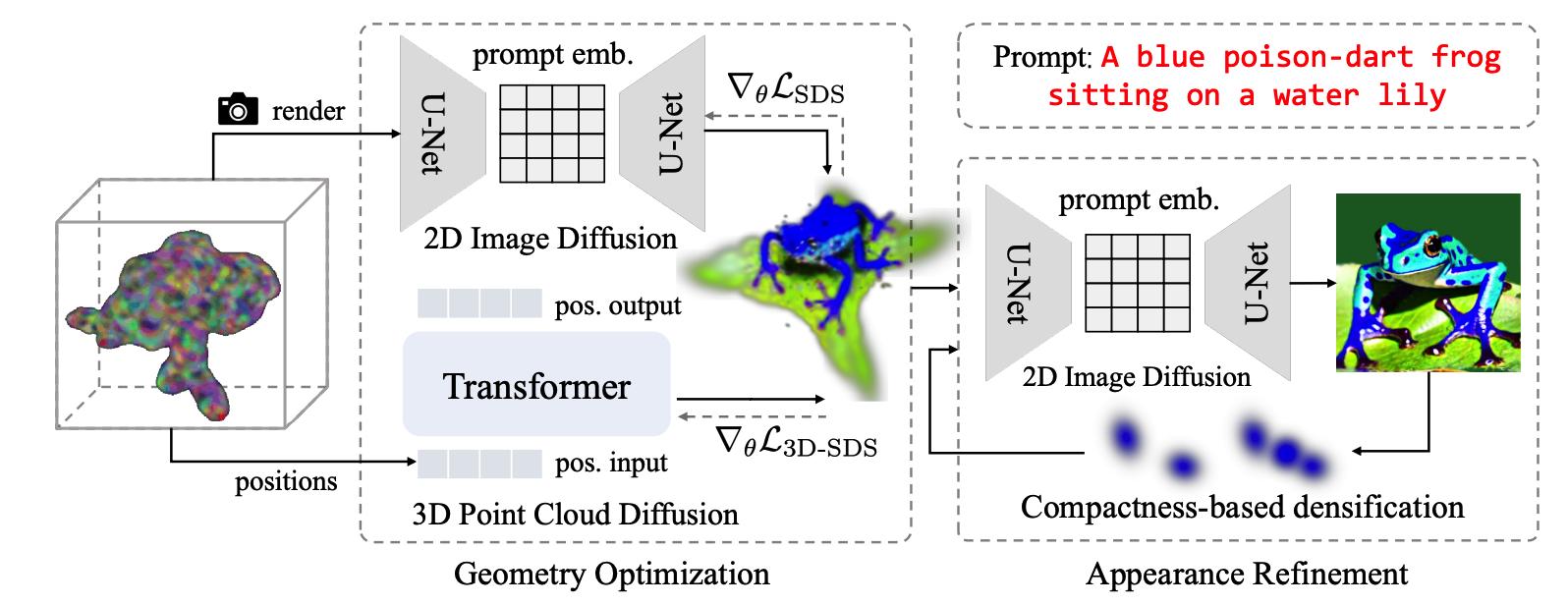
많은 기존의 방법론들이 고작 몇장의 view를 가지고 rendering을 해야하는 문제가 있었습니다. 이는 janus, collapsed geometry의 문제를 필연적으로 발생시킵니다. diffusion 모델은 3D spatial 정보를 가지고 있기 않기때문에 prompt를 통해서 guidance를 주는게 한계가 있습니다.
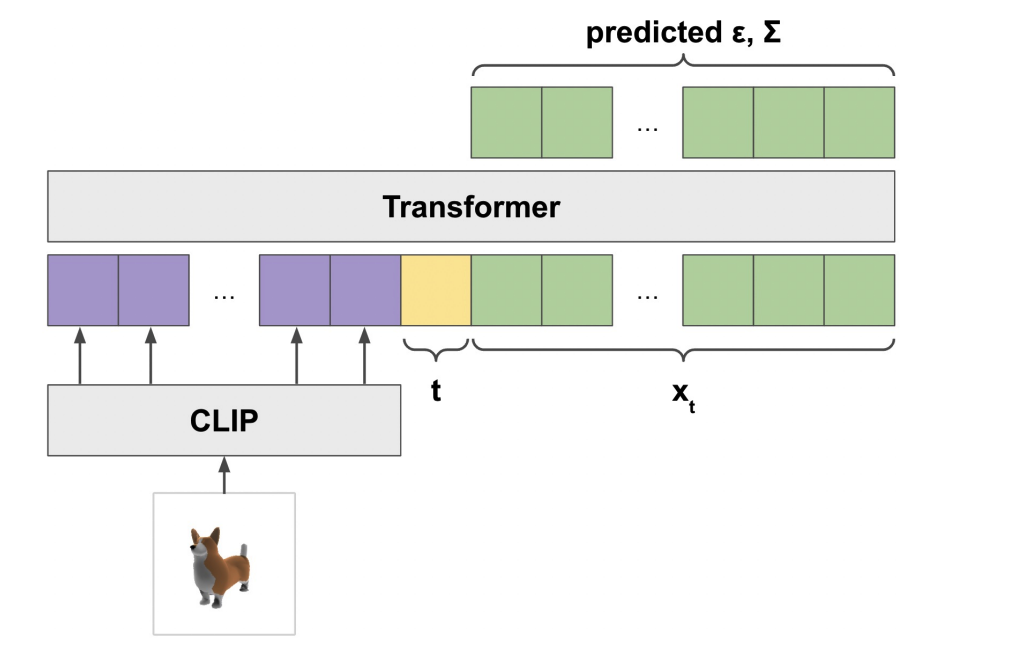
위의 그림은 point-E의 대략적인 구조입니다. clip을 통해 text-embedding이 들어가면 transformer를 통해 predicted points를 출력하는 형식입니다. 이를 유추해보면 2D image Diffusion에서 나온 image를 pretrained point-E에 입력시켜 pointcloud의 position을 구하는 부분을 gaussian과 매칭시켜 gaussian의 position을 업데이트하는 것으로 생각됩니다. 바로 align시키는것이 아닌 diffusion image모델의 학습과 같이 time iterative하게 학습시킵니다.
즉, 바로 point-E에 3D Gaussian을 붙이지 않고 3D SDS loss를 사용하여 gaussian position에 대한 최적화를 진행합니다.
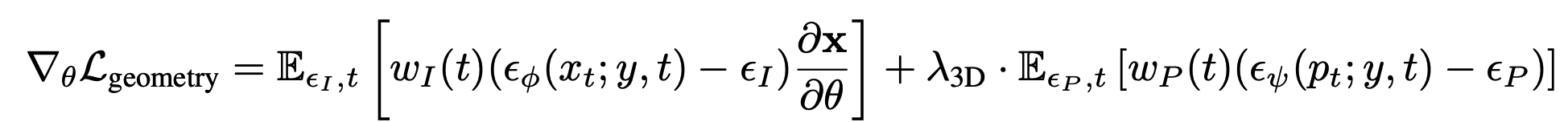
Refinement
1stage를 요약하면 기존의 DreamFusion과 같은 구조에서 rendering을 Gaussian splatting으로 변경하고 geometry inaccurate를 해결하기 위해 position에 대한 optimization은 point-E라는 pretrained모델을 사용하여 position 업데이트를 진행합니다.
이렇게 해서 나온 결과물을 다시 refinement단계를 거칩니다.
기존의 Gaussian 논문에서는 gaussian을 densify하게 하기 위해 큰 gradient를 사용하지만 해당 논문에서는 stochastic한 SDS loss때문에 적절한 threshold가 필요하다고 말합니다. 너무 작으면 misled될 수 있고, 너무 크면 blurry한 결과물이 나오게 됩니다. 이를 해결하기 위해 큰 threshold를 가지고 positional gradient기반의 split을 진행한다고 합니다. 좀 더 자세히 설명하면 KD Tree를 사용하여 각각의 Gaussian간의 distance를 구하고 distance가 각각의 radius보다 크면 Gaussian을 추가합니다.
반대로 일정 threshold이하의 opacity를 갖는 gaussian을 지웁니다.
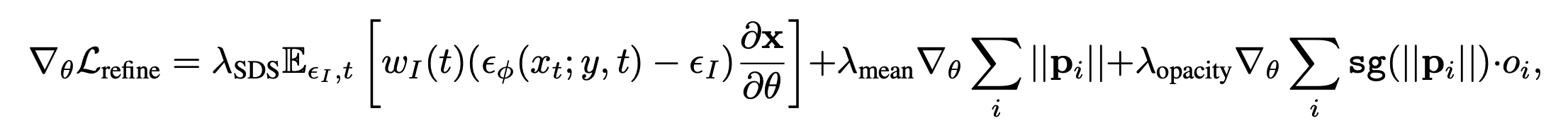
첫번째 텀은 기존 SDS와 같고 2번째텀은 1stage의 결과에서 일정이상 position벗어나지 못하게 regularization을 걸어두고 position을 업데이트하는 것을 의미하고 세번째 텀은 opacity대한 업데이트를 의미합니다.(sg는 stop gradient : 해당 term에 position은 update안한다는 의미)
Gaussian이 position에 대한 initial guess가 있으면 성능이 좋기때문에 user guide나 pointcloud를 통해 대략적인 position을 얻고 시작하면 효과가 더 좋다고 합니다.
한계점은 아직 janus현상이 완벽하게 사라지지는 않았다고 합니다. 아래는 qualitative 결과입니다.

