![[paper review] SSDA3D 논문 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb8ikLa%2FbtsrUvLMI7S%2FwfdjcxsAYc0BNrBM9SLng0%2Fimg.png)
안녕하세요. 이번 포스팅은 SSDA3D라는 pointcloud 3D detection 모델의 Domain Adaptation관련 논문을 리뷰하겠습니다. AAAI에 publish된 해당 논문은 이전에 포스팅한 DA과는 다르게 최소의 target data의 label을 필요로 합니다.
[paper review]Density-Insensitive Unsupervised Domain Adaption on 3D Object Detection 논문 리뷰 (model generalization)
이번 포스팅은 3D object detection에서 DA(domain adaptation)에 관련된 DUDA논문의 리뷰입니다. 해당 논문의 문제정의부터 보면 최근 3D Object Detection (좀 더 자세하게는 pointcloud model을 의미합니다) 의 발전
jaehoon-daddy.tistory.com
즉 ST3D, DTS등의 DA방법은 UDA(unsupervised domain adaptation)이라고 할 수 있고, SSDA3D는 SSDA(semi-supervised domain adaptation)이라고 할 수 있습니다. 즉, SSDA는 small labeled set을 이용하여 oracle model의 성능을 기대하는 것을 의미합니다.
overview
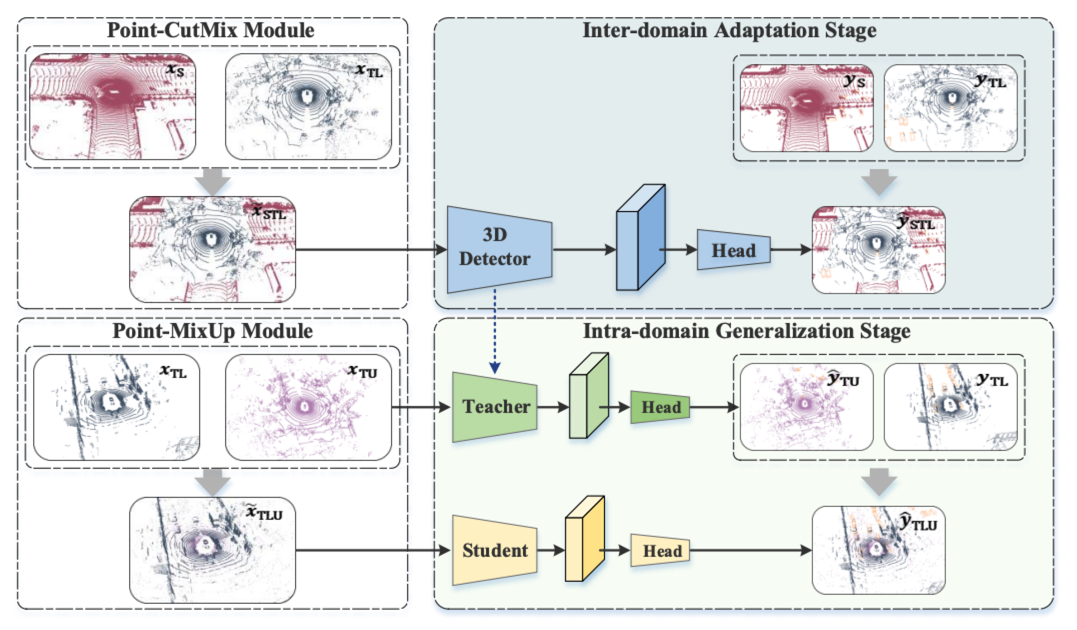
위의 그림은 SSDA3D의 overview입니다. 크게 2번의 step으로 이루어져있습니다. 기본적인 structure는 UDA framework인 ST3D과 동일합니다. 우선 크게 data를 세가지로 분류할 수 있는데 $D_{S}$는 source domain 의 data, $D_{TL}$은 target domain의 labeling된 data, $D_{TU}$은 target domain의 unlabeled data로 분류할 수 있습니다.
그 다음은 크게 두단계로 나눠집니다. 첫번째는 Inter-domain Adaptation단계로 source domain과 target domain간의 간극을 줄여줍니다. $D_{STL}$은 source domain과 $D_{TL}$에 Point-CutMix를 통해 나온 augmented data인데 이를 통해 학습을 진행합니다. 이 단계에서 $D_{S}$과 $D_{TL}$간의 간극을 줄일 수 있다고 합니다.
두번째 단계에서는 첫번째 단계에서 학습된 모델을 teacher로 하여 pseudo labeling을 하고 이를 통해 나머지 $D_{TU}$ 와 $D_{TL}$을 Point-MixUp하여 $D_{TLU}$라는 데이터를 하습하여 student model을 만들게 됩니다. 이렇게 보면 전체적인 구조는 UDA인 ST3D와 비슷한데 그 과정에서 label이 어느정도 쓰이게 된다고 보시면 됩니다.
Inter-domain Point-CutMix
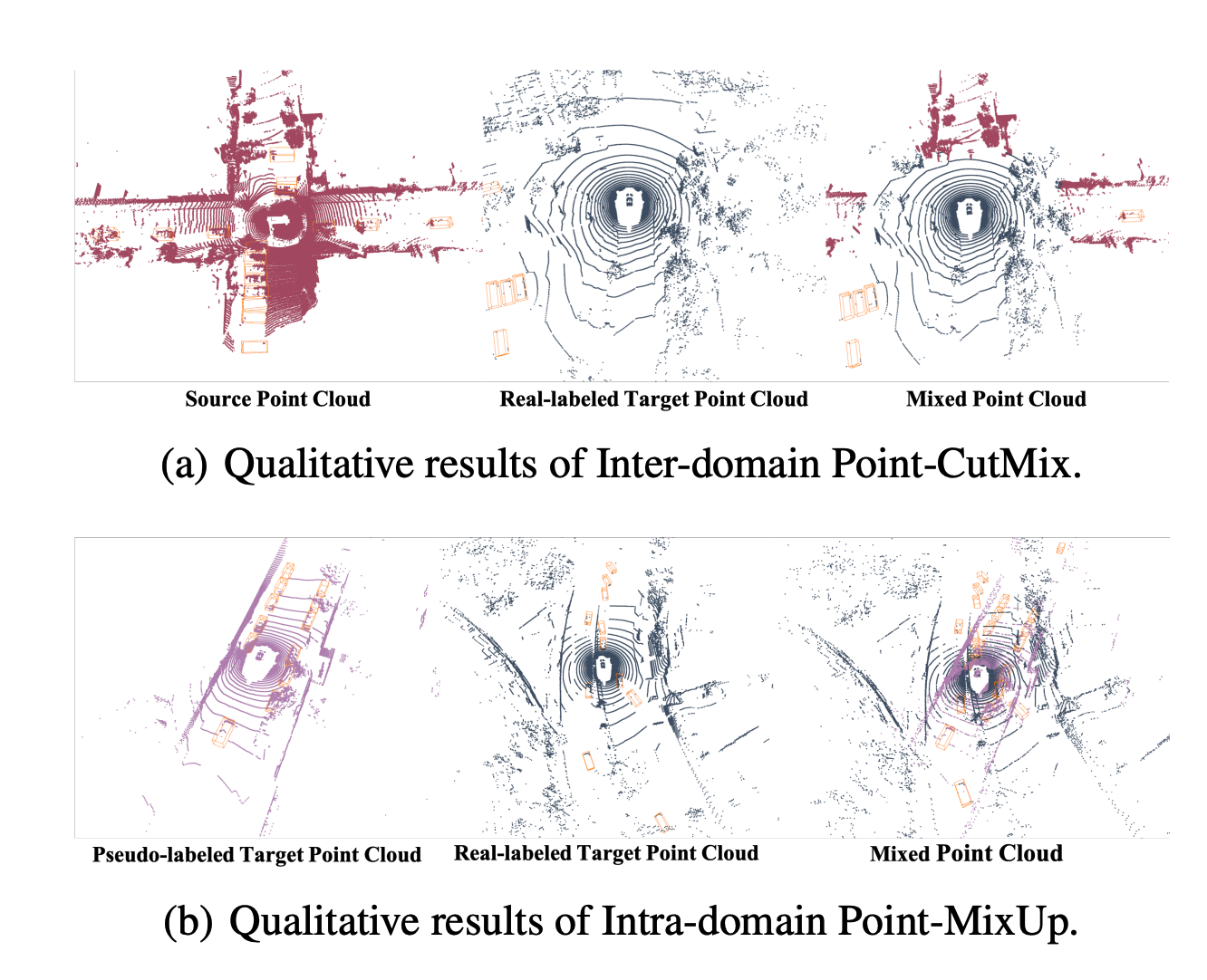
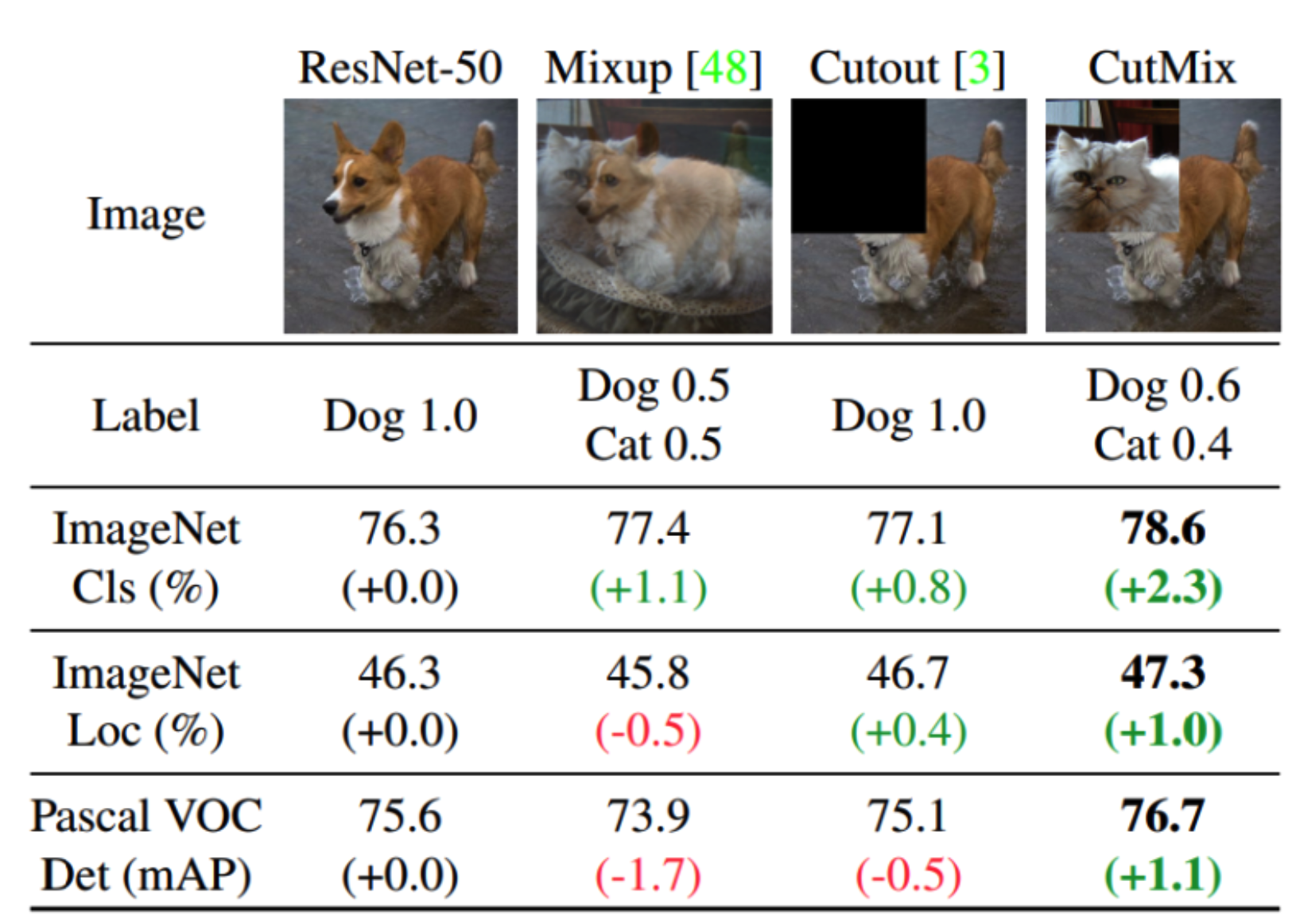
이제 좀 더 구체적으로 첫번째 step에 대해 보겠습니다. 이 단계에 augmentation의 방법으로 쓰이는 point-cutmix는 image의 cutmix에서 아이디어를 착안하였습니다. Point-CutMix모듈을 사용하여 두 domain의 invariant feature를 학습할 수 있도록 합니다.
- Point-CutMix

구체적으로 $D_{TL}$의 point에서 랜덤하게 point를 뽑고 BEV를 기준으로 그 중앙점 $C_{T}$ 근처에 랜덤하게 사각형 region을 선택합니다. 이 후 사각형 바깥의 points은 모두 삭제하고 삭제된 부분은 source point cloud로 대체합니다. 이렇게 얻어진 mix된 data를 $X_{STL}$이라고 하고 그것의 label을 $Y_{STL}$이라고 정의합니다. 이를 수식으로 표현하면 아래와 같습니다. 이렇게 얻어진 데이터와 라벨을 이용하여 학습한 모델을 teacher model로 정의하고 이 teacher model은 두 domain의 feature를 잘 balance하여 학습하게 됩니다.

Intra-Domain Point-MixUp

2번째 단게에서는 intra-domain generalization을 강화하는 단계입니다. 즉, target domain의 데이터에서 라벨링된 데이터와 그렇지 않은 데이터간의 차이를 최소화하여 학습하는 것입니다. 첫번째 단계에서 학습한 teacher model에서 나온 결과를 pseudo label로 사용하지만 이 데이터는 당연히 inaccurate prediction이 있을 것 입니다. 그래서 Point-MixUp을 통해 이를 최소화시킵니다.
teacher model로 prediction한 결과를 pseudo label을 만들고 이를 SSL mehod를 거칩니다.(FixMatch: low confidence는 필터링 ) 이후 TL과 TU데이터간의 point-MixUp을 거치게 됩니다.
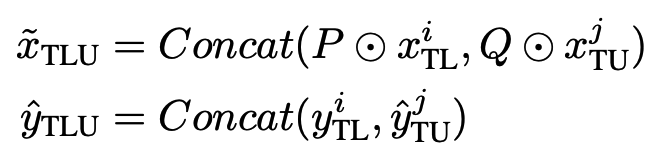
Experiments
데이터셋으로는 채널수가 서로 다른 Waymo(64)와 nuScene(32)를 선택하였습니다. source data로 즉 pretrained모델은 waymo로 학습한 모델이고 이를 nuscene데이터의 1%, 5%, 10%, 20%, 100%의 label 데이터를 이용하여 DA를 실험하였습니다.

10% 라벨데이터만 사용하여도 oracle성능보다도 높은 결과물이 나오는 것을 볼 수 있습니다.