안녕하세요. 이번 ML관련 포스팅에서는 Transformer관련하여 포스팅하겠습니다.
이미 나온지 꽤 오래되었고 많은 분야에서 활용되고 있는 아키텍쳐인데요. NLP분야에서 일찍이 탄생했지만 비전 및 다른 분야에서도 많이 활용되고 있습니다.
Transfomer는 Attention is All You Need 라는 논문을 통해 처음 발표되었습니다. 제목에서도 알 수 있듯이 Transformer를 이해하려면 우선 Attention에 대해서 이해를 이해합니다.
Attention
우선 attention 메커니즘은 sequence-to-sequence 모델에 적용이 됩니다. seq2seq모델은 글자나 이미지의 feature 등을 입력으로 받아 또 다른 시퀀스를 출력합니다.
이 시퀀스 모델은 encoder와 decoder로 이루어져 있습니다. 보통 encode에서는 입력을 처리하여 정보를 추출한 후 하나의 벡터 context로 만들어냅니다. decoder는 이 context로 부터 output을 뽑아냅니다.
아래는 이와 관련 NLP 문제를 시각화한 애니메이션으로 이해하는데 매우 도움이 되어 https://jalammar.github.io/ 에서 퍼왔습니다.
그럼 이제 Attention에 대해 봅시다. seq2seq에서 문제가 되는 부분은 context인데 하나의 고정된 벡터로 전체 맥락을 나타내야하니 쉽지 않은 일입니다. 그래서 제시된 것이 Attention입니다.
시퀀스 모델과 크게 두가지의 차이를 보이는데 첫번째로 encoder에서 decoder로 넘어가는 데이터의 양이 훨씬 많다는 점, 모든 hidden state를 decoder에게 넘김니다.
두 번째는 decoder를 출력할때 하나의 추가 과정이 필요한데 hidden state에 weight를 부여하는 과정입니다. 이 또한 아래의 애니메이션을 통해 쉽게 이해할 수 있습니다.
위의 점수를 매기는 과정은 decoder가 매 단어를 생성할 때 마다 반복합니다. 이 attention을 이용하면 각 decoding 스텝에서 어떤 부분에 집중하고 있는지 알 수 있습니다.
Transformer
이제 위의 NLP 예제 문제를 transformer에 적용해보겠습니다.

위의 그림은 transformer도 seq2seq모델임을 말해주며 전체적인 아키텍쳐를 설명해줍니다.
그렇다면 하나의 토이 예제를 보면서 transformer를 이해해보겠습니다. 예제는 위와 같이 한 문장을 번역하는 예제입니다. 우선 입력된 단어들을 embedding알고리즘을 이용하여 vectorize합니다. 각 단어들은 512크기의 벡터로 각각 임베드 됩니다.
각각의 단어가 임베딩되어 처음의 encoding에 흘러가는 모습입니다. 여기서 self-attention에 대해 집중해보겠습니다. 예를 들면, '나는 프로그래밍을 좋아한다. 그것은 매우 창의적인 활동이기 때문이다' 라는 글을 번역한다고 할때 여기서 그것은 프로그래밍을 뜻하는 것을 사람은 쉽게 알 수 있습니다. 하지만 모델의 입장에서는 쉽지 않은 일이고 그것을 위해 self-attention이 맥락을 살펴주는 역할을 해줍니다.
self-attention
그럼 어떻게 self-attention에서 서로간의 맥락을 파악할 수 있는지 구체적으로 보면 input vector들에게서 Query, Key, Value 벡터를 생성합니다. 여기서는 512크기의 벡터에서 각각 64개의 Q,K,V 벡터를 추출합니다.
임베딩 벡터의 각각의 weight()곱하여 q,k,v벡터를 만들 수 있습니다. W는 학습을 통해 update합니다.
Q,K,V를 통해 각각의 score를 계산하여 중요도를 판별합니다. 아래는 그 예시로 thinking에 대해 다른 단어들 과의 점수를 매기는 과정으로 q와 대상단어의 k를 내적하여 score를 구합니다.
8은 벡터 크기 64를 제곱근한 값이며 이렇게 얻은 score를 softmax합니다. 이는 현재 위치의 단어가 얼마나 다른 단어들의 표현이 들어가 있는지를 의미하게 됩니다. 이렇게 나온 softmax값에 v(value)벡터를 곱하고 이를 모두 합해 버립니다.
Multi-headed Attention
멀티헤드 어텐션은 모델이 다른 위치에 집중하는 능력을 향상 시키며 여러개의 attention layer가 여러개의 representation 공간을 갖게 해줍니다.
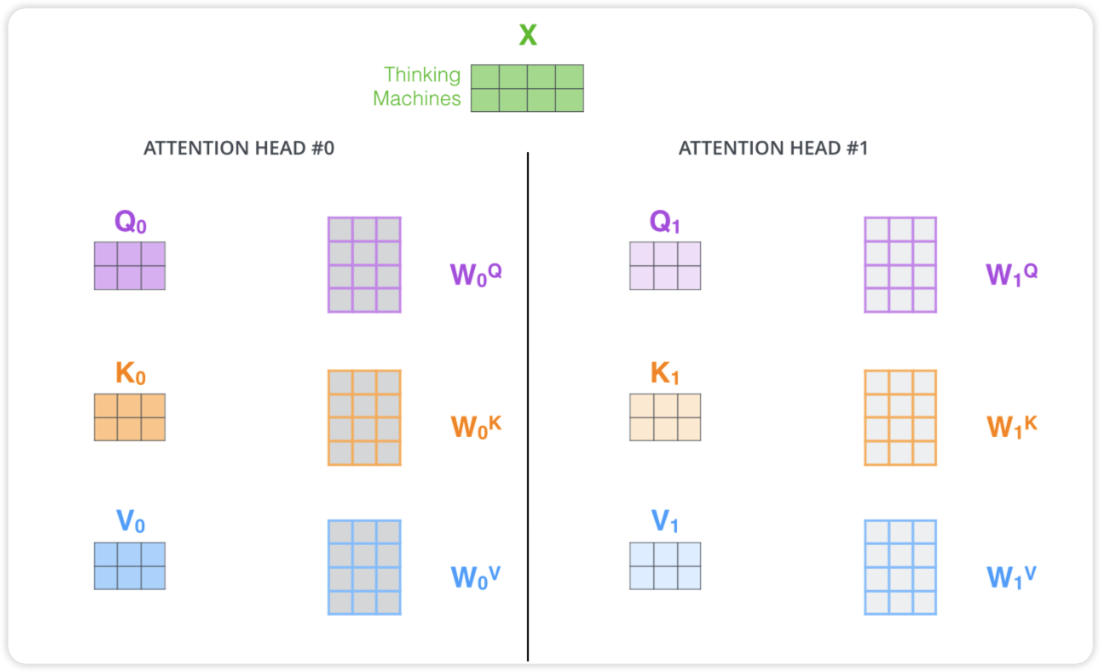
위는 multi-head attention을 2개만 개략적으로 나타낸 그림입니다. 만약 8개의 self-attention layer를 거치면 8개의 서로다른 z행렬을 갖게 됩니다. 이 8개의 행렬은 바로 feed-forward layer로 보낼 수 없습니다. 1개로 압축해야합니다. 그렇게 하기 위해 8개의 z를 concat한 후에 wieght를 곱하여 1개의 z로 표현합니다.
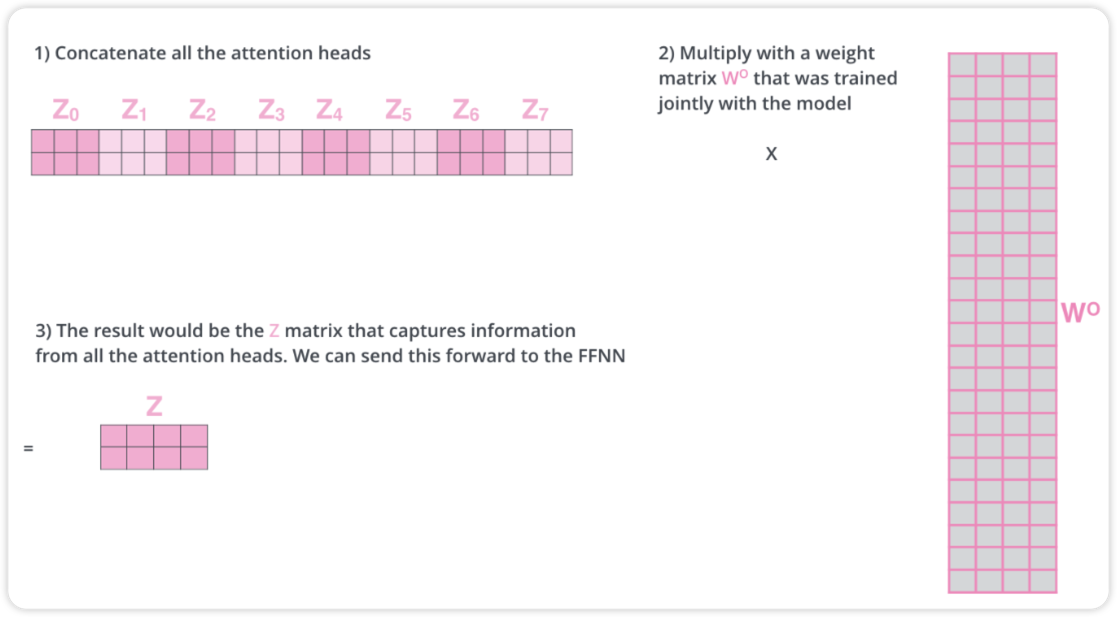
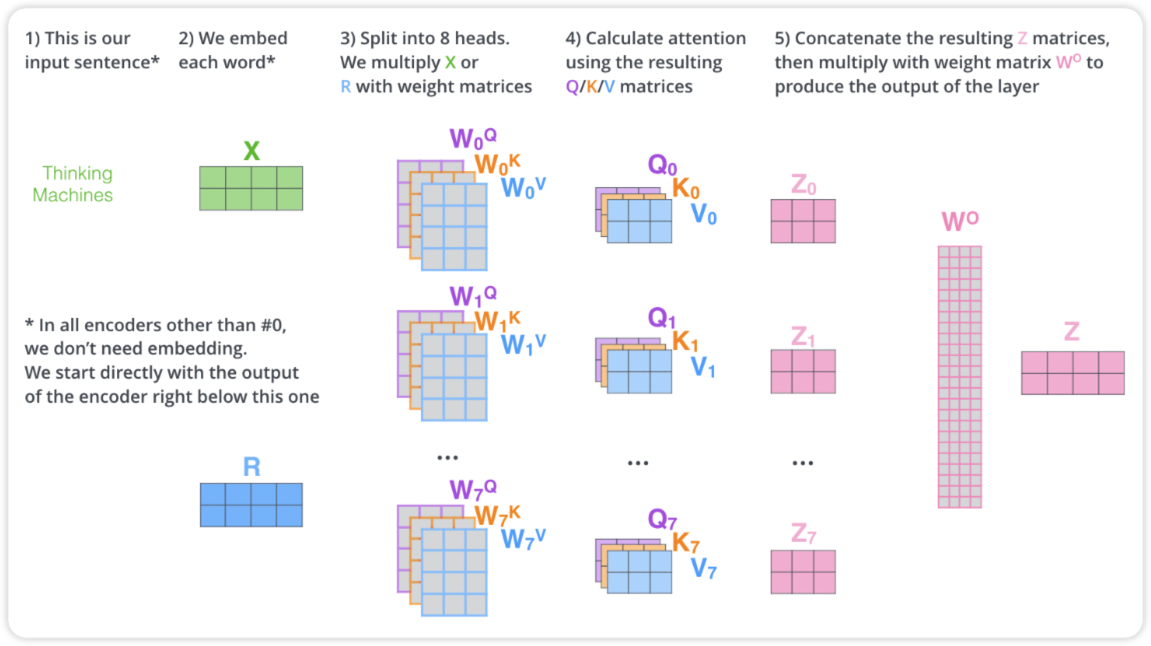
아래는 multi-attention layer를 다시 한번 전체적으로 나타낸 그림입니다.
Positional Encoding
positional encoding은 모델에 들어가는 단어에 순서 혹은 위치를 표현해주는 것입니다. 이 것들이 q,k,v에 투영되었을 때 단어간의 집중할 수 있는 거리를 늘리는 장점이 있습니다.
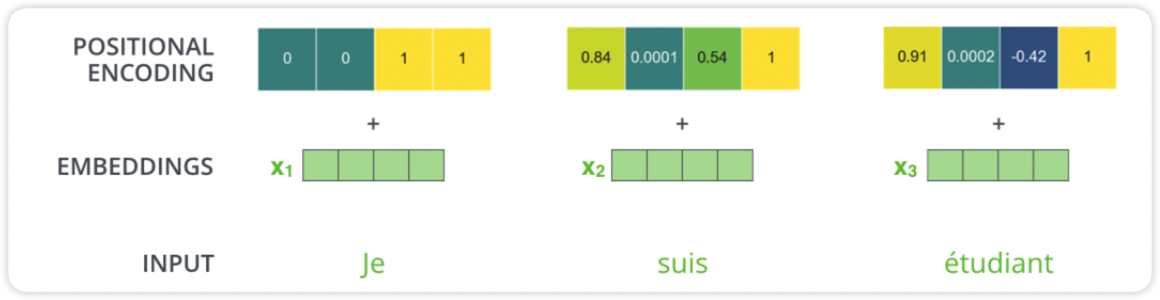
위의 그림은 positional encoding을 임베딩과 결합하는 예시입니다. 512개의 크기에 (그림에서는 4이지만..) -1 과 1사이의 값을 가집니다.
Residuals
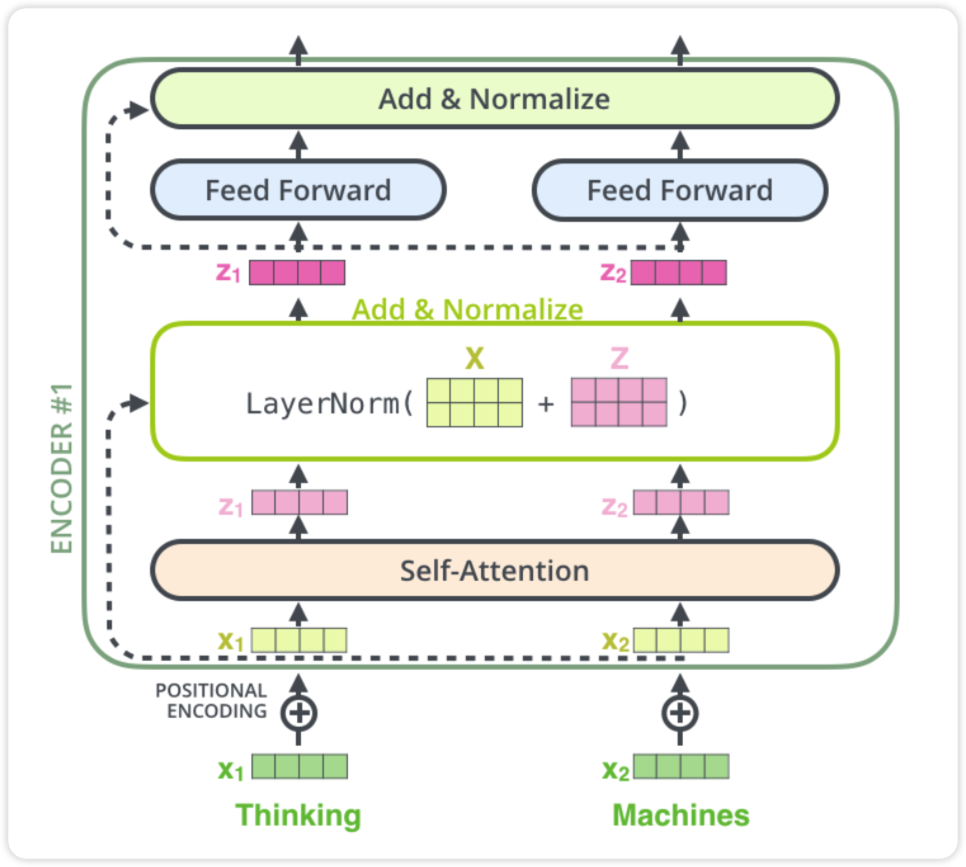
Decoder
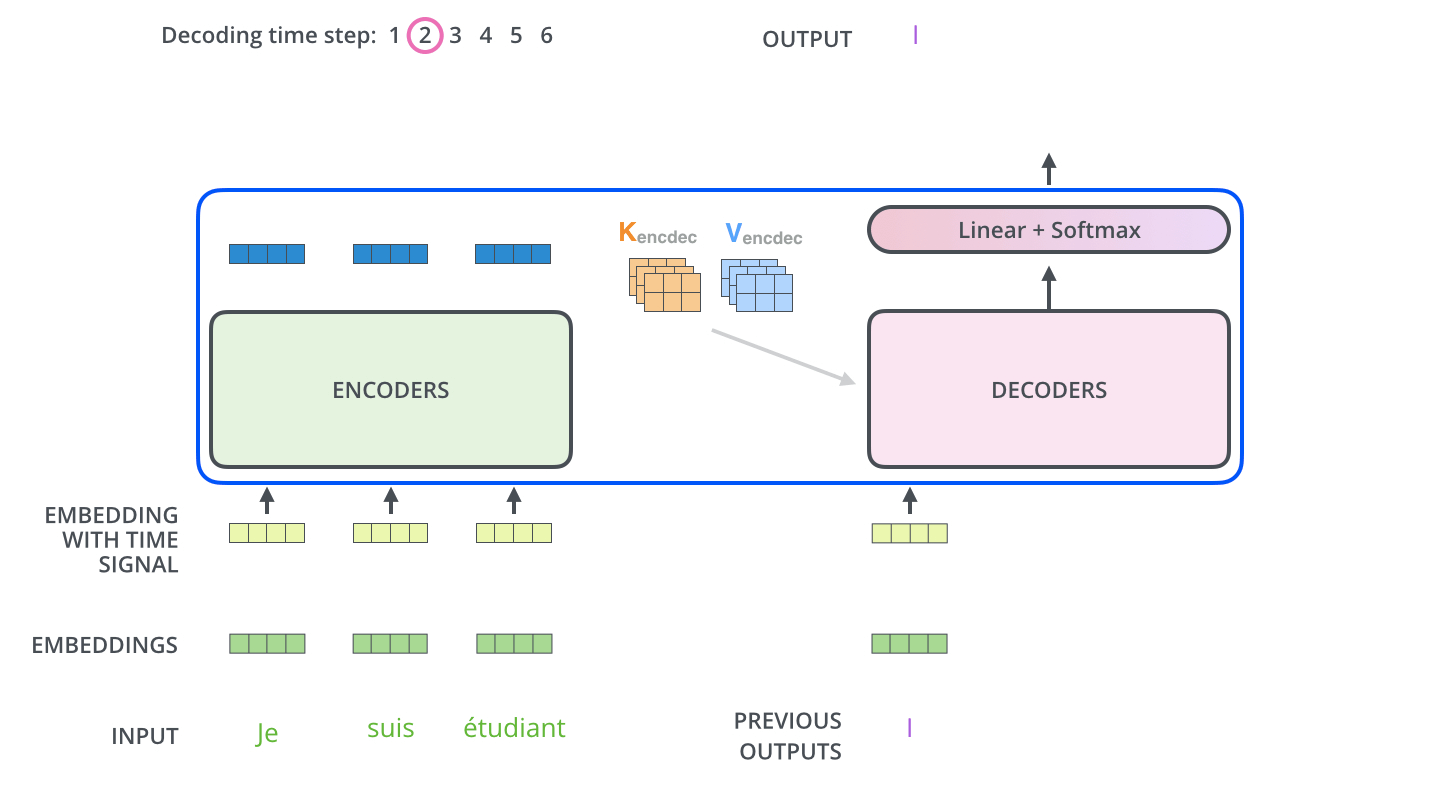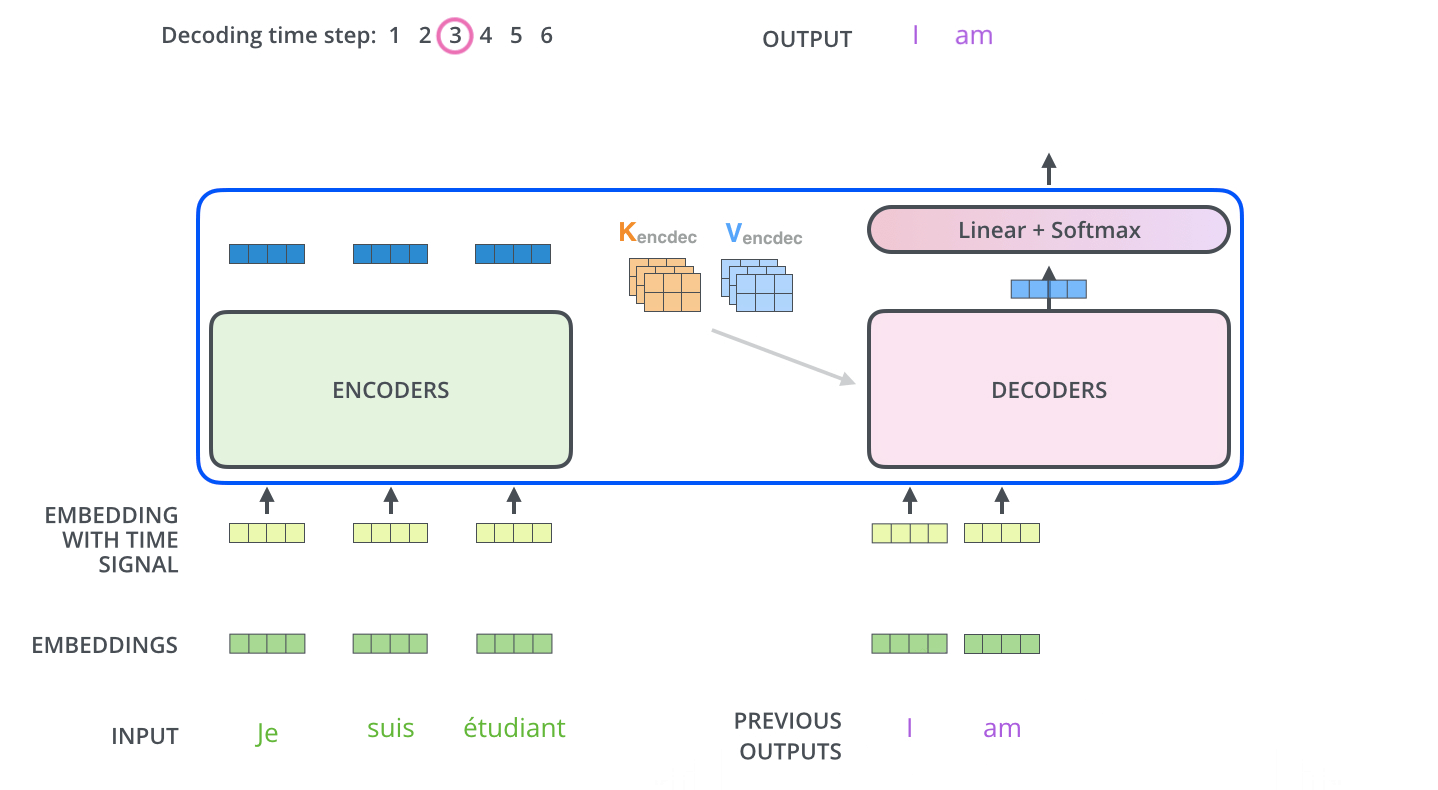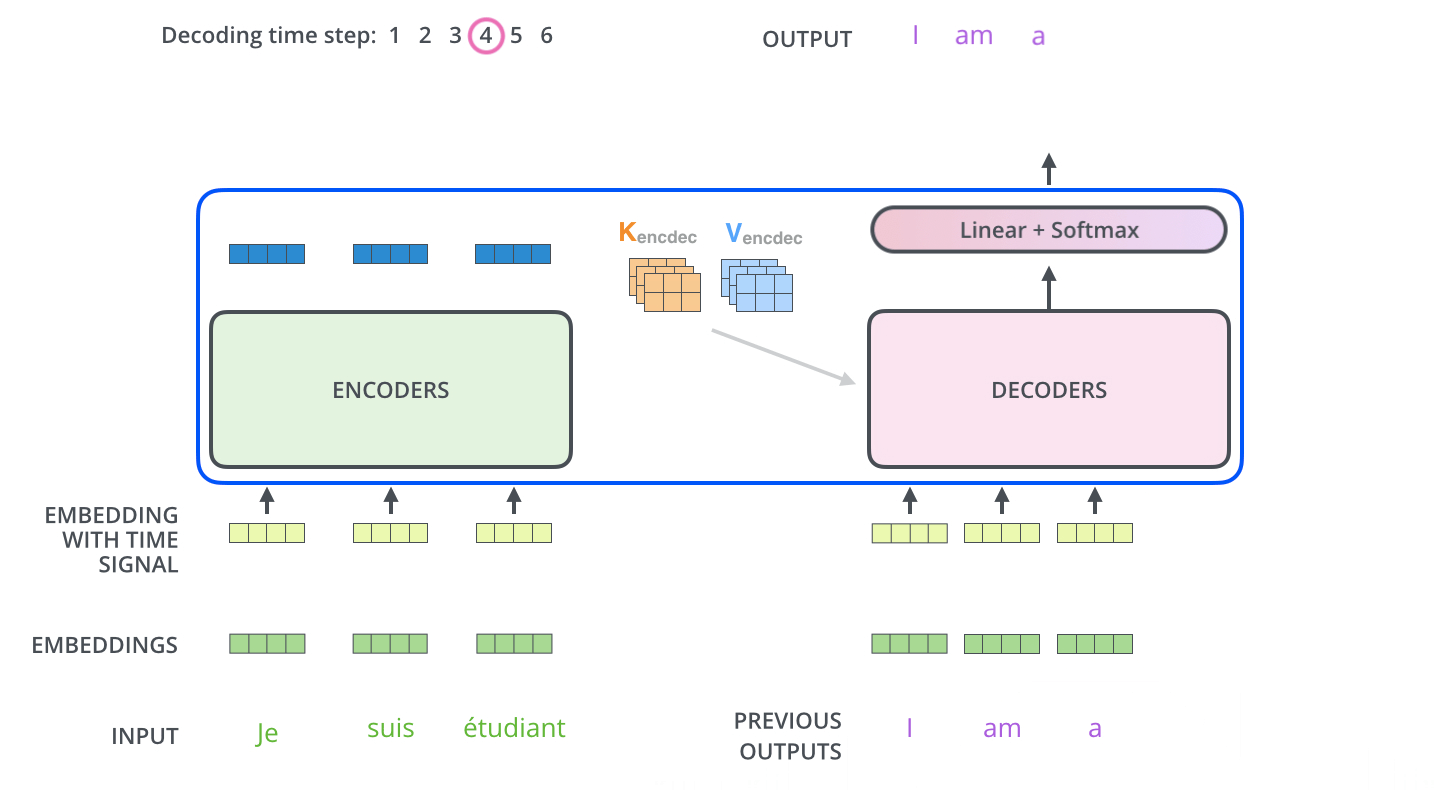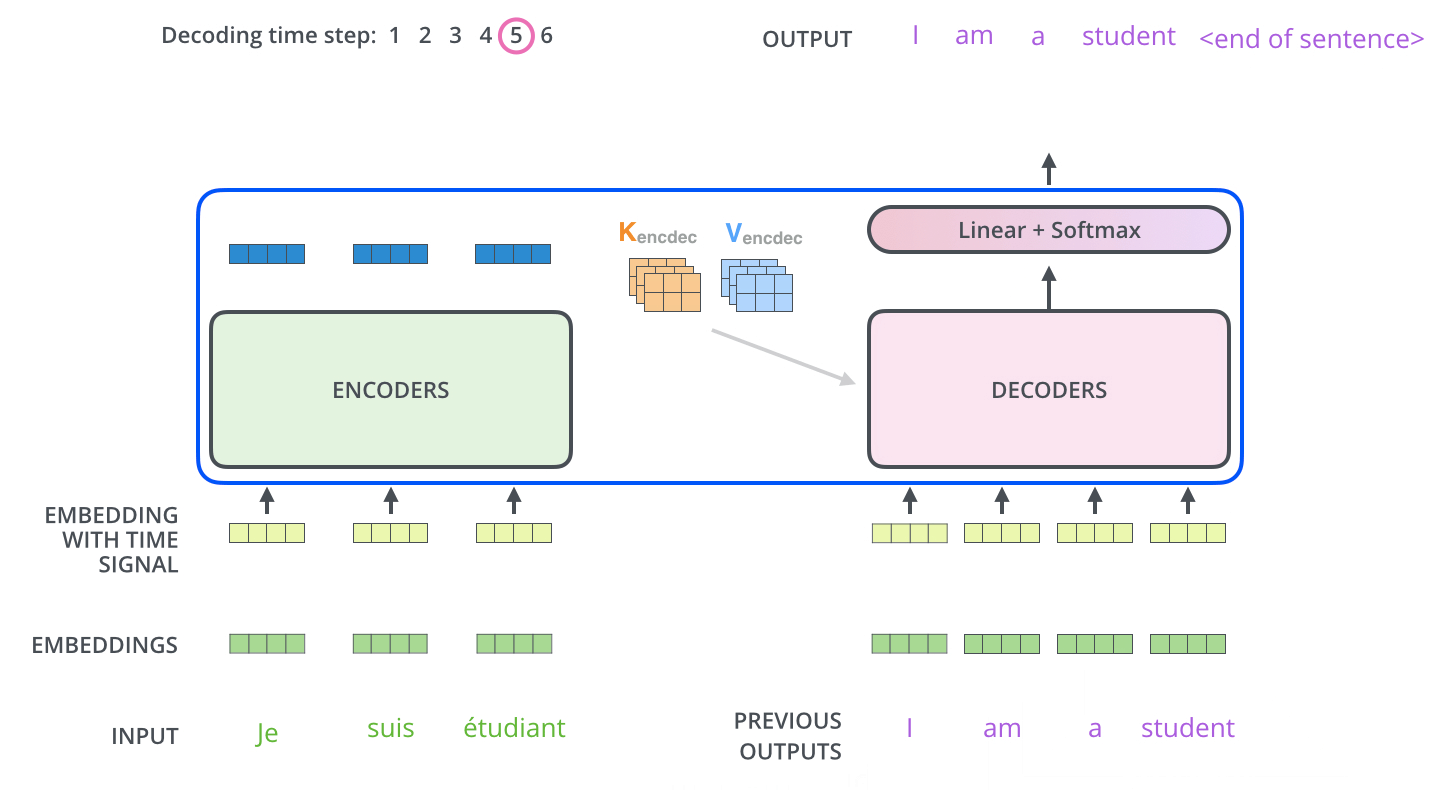
decoder에 들어가기전에 encoder에서 나온 z는 K,V로 변형됩니다. decoder에서는 encoder와는 조금 다릅니다. decoder에서의 self-attention에서는 현재 위치의 이전 위치들에 대해서만 attention할 수 있습니다. 또한 Q행렬은 밑의 layer에서 가져오고 key와 value행렬은 encoder 출력에서 가져옵니다.
이렇게 여러개의 decoder를 거치면 벡터 하나가 남게 되고 fc과정(던어가 10000개라면 10000개의 크기를 갖습니다.)을 거쳐 softmax를 통과하게됩니다.
ViT(Vision Transformer)
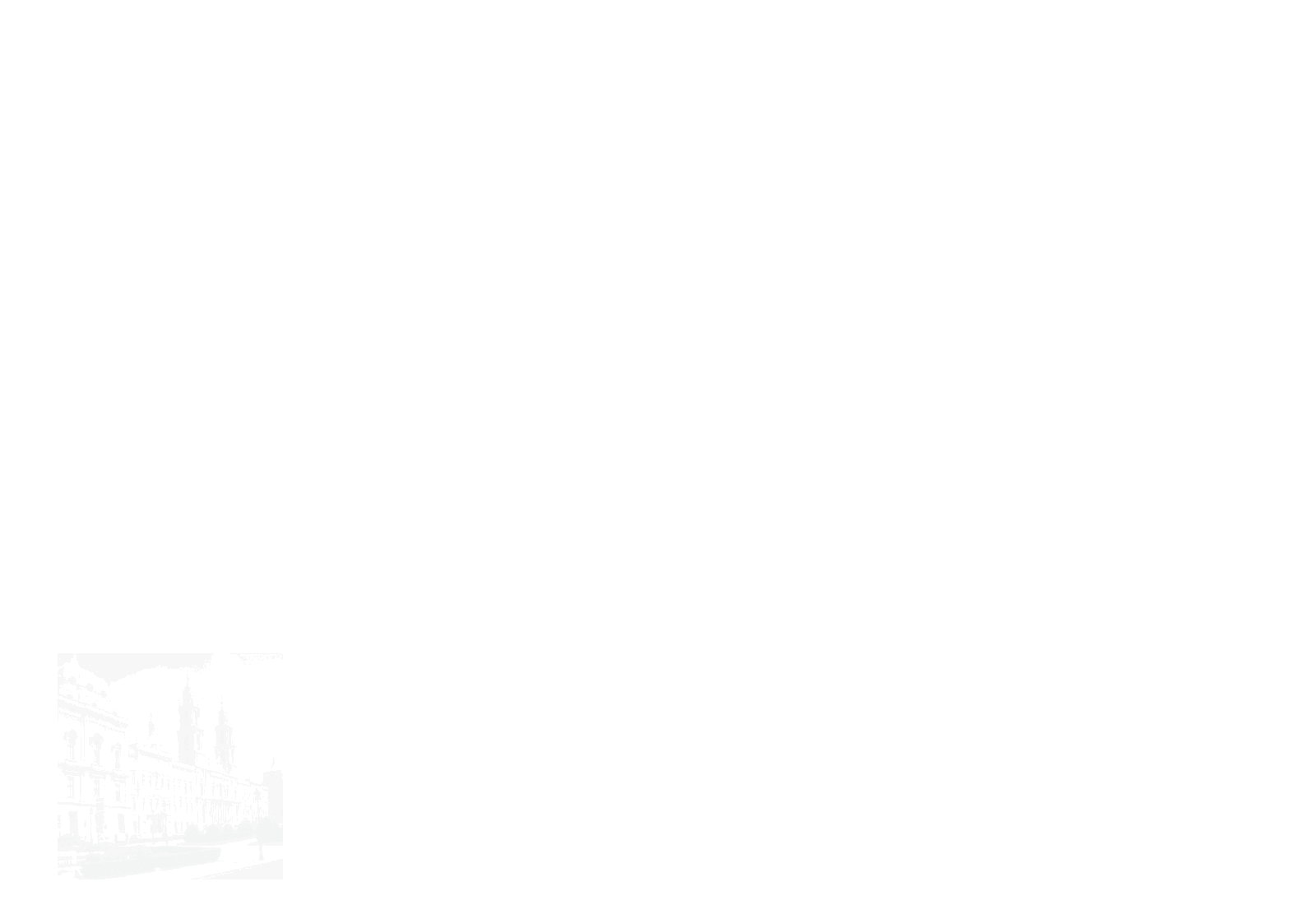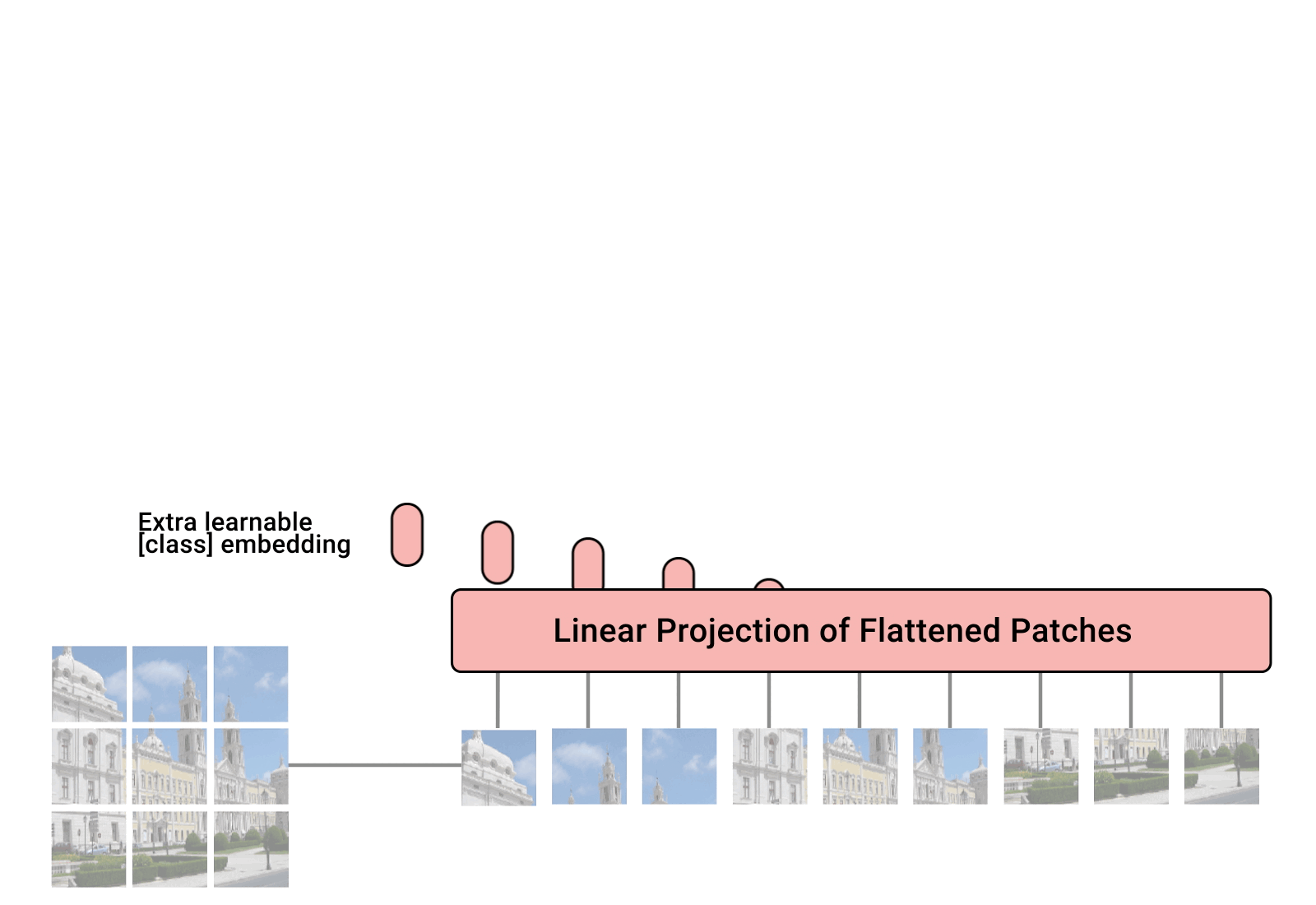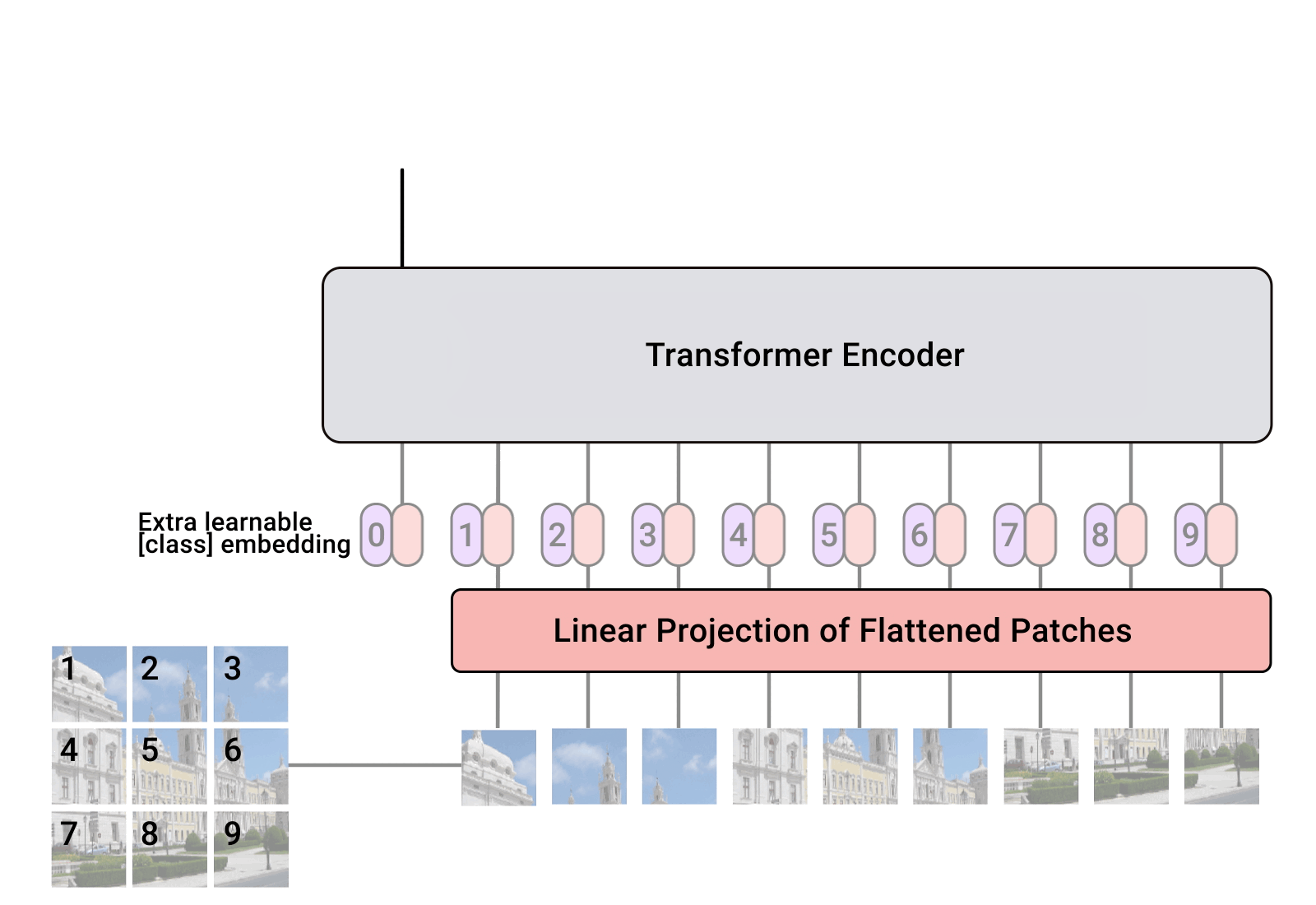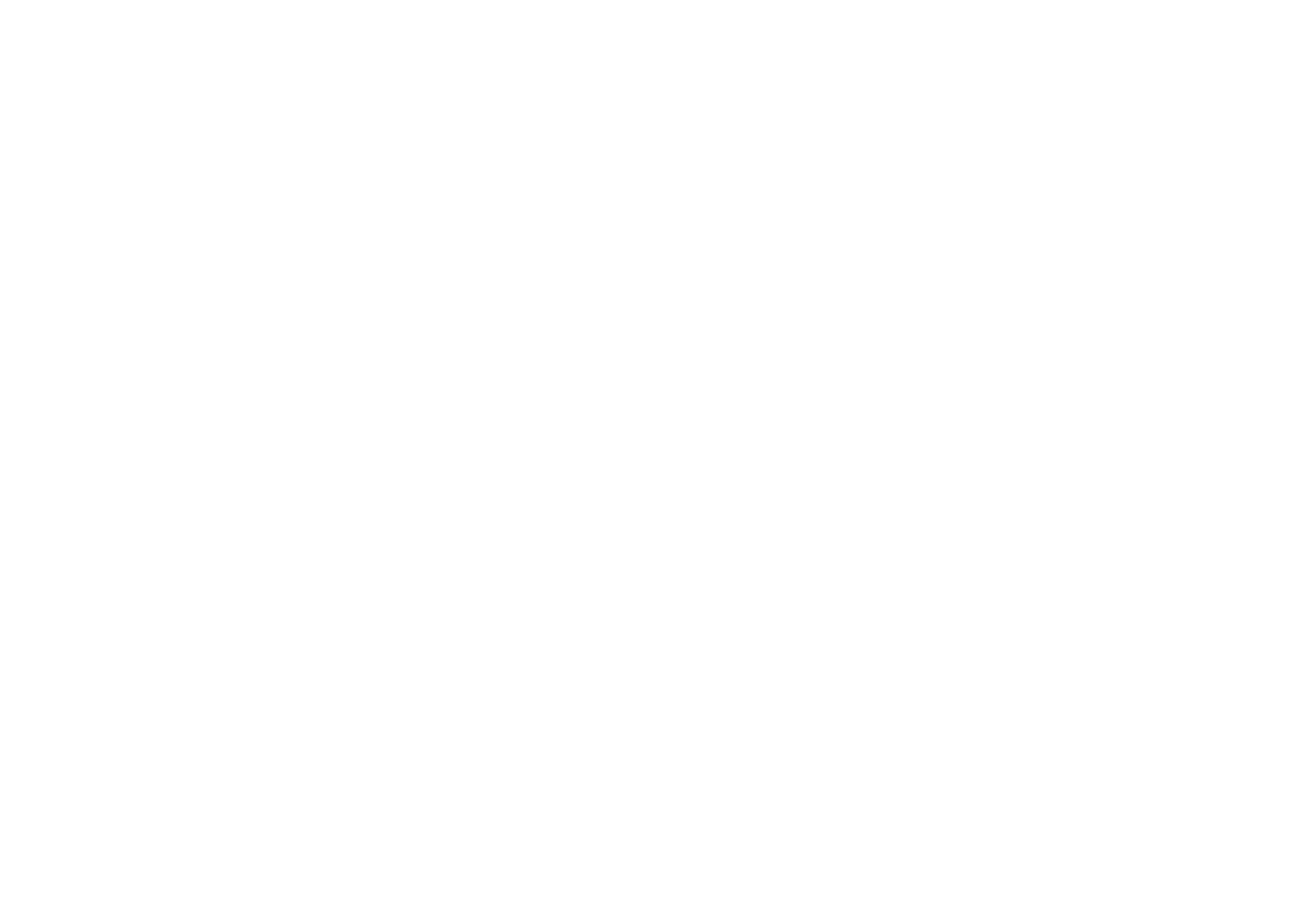
이어서 transformer를 활용한 비전 ViT에 대해 보겠습니다.
왼쪽아래 사진을 보면 input image를 patch로 나눠서 텍스트의 sequence처럼 사용하는 것을 볼 수 있습니다. 즉, patch를 text처럼 생각하면 여기에 embedding과정과 position embedding을 더하여 Transformer의 인풋값으로 넣어줍니다. 여기에 더해서 classification token을 더해줍니다. 어떤 이미지인지 알려주는 과정을 추가한 것 입니다.
patch로 변환하는 과정을 보면 를 patch(로 flatten합니다. 이후 transformer의 encoder를 거쳐 나온 벡터를 다시 MLP head에 넣어 classfication합니다. 전체적으로 매우 직관적이고 간략합니다.
ViT의 특징은 매우 많은 데이터를 필요로 합니다. 따라서 fine-tuning하여 사용하는 것을 권고하고 있습니다.
이상으로 Transformer의 기본적인 설명을 마무리합니다. 이 후 transformer를 사용한 다양한 비전task를 살펴보겠습니다.




