LLM (Larget Language Model)의 약자로 그대로 해석하면 대형 언어 모델입니다. NLP에서는 이전의 처리했던 output이 현재의 input을 처리할때 사용이 되어야하기 때문에(문맥파악) RNN, LSTM, GRU 같은 recursive 모델을 사용했었습니다. 하지만 이 operator들을 사용한 모델은 Long-term Dependency, Vanishing Gradients 등의 한계가 존재했습니다. Transformer의 등장이후에 이 문제점들이 어느정도 개선되면서 LLM이 본격적으로 등장하게 되었습니다.
[Transformer] Transformer & Vision
안녕하세요. 이번 ML관련 포스팅에서는 Transformer관련하여 포스팅하겠습니다. 이미 나온지 꽤 오래되었고 많은 분야에서 활용되고 있는 아키텍쳐인데요. NLP분야에서 일찍이 탄생했지만 비전 및
jaehoon-daddy.tistory.com
Transformer의 발견으로 satuation을 한차례 극복한 LLM 모델들은 규모적으로 경쟁을 하기시작했습니다.

BERT(Bidirentional Encoder Representations from Transformers)
2019 google에서 발표된 PLM(pretrained language model) transformer의 encoder만으로 구성된 모델입니다. BERT이전의 모델(ELMO, GPT-1)은 Unidirection training이라는 단점이 존재했습니다. Transformer의 decoder를 토대로 해서 Autoregressive한 방식으로 input을 받게 되었죠. 이를 해결하기위해서 BERT는 이름에서 알수있듯이 양방향 traning을 제안하였습니다. 그로인해 context파악에 더 유리할 것이라 생각했습니다.
training이 2-stage로 나뉘는데 먼저 pretraining단계에서는 text에서 일부단어를 masking한후에 masking된 단어를 예측하는 방식(MLM - Masked Language Modeling)과 주어진 문장에 이어질 다음 문장을 예측하는 두가지의 방식으로 SSL을 수행하였습니다.
Self-Supervised Learning 훑어보기
기본적으로 Supervised Learning을 위한 Label확보는 많은 비용을 필요로 합니다. 그렇기에 representation정도는 unlabeled data만으로도 확보할수있지 않을까?하는 시작에서 나온것이 self-supervision입니다. sel
jaehoon-daddy.tistory.com
*PLM vs LLM

GPT(Generative pretraining Transformer) 3
본격적으로 LLM이라고 불릴만한 모델이 나온건 2020년 즈음인데 GPT3가 등장하면서 부터입니다. GPT-2에서도 다양한 task를 수행하기위한 시도가 있었지만 지금의 LLM의 면모까지는 아니였습니다. 참고로 GPT2는 코드도 공개되어 있습니다. https://github.com/openai/gpt-2
GitHub - openai/gpt-2: Code for the paper "Language Models are Unsupervised Multitask Learners"
Code for the paper "Language Models are Unsupervised Multitask Learners" - openai/gpt-2
github.com
17년 Transformer → 19년 GPT1 → 20년 GPT3 , 현재('25)의 Deepseek, GPTo3 등 매해 엄청난 LLM이 나오고 발전을 계속하고 있는데 GPT3의 탄생은 중요한 변곡점이라고 볼 수 있습니다.
GPT3부터는 fine-tune없이 다양한 task를 수행할 수 있게되었습니다.
기존의 문제는 이 Finetune과정에서 모델의 generlization 성능이 감소된다는 것 입니다. 이를 해결하기 위한 방법들로 첫번째는 In Context Learning을 사용했습니다. ICL은 학습의 기법이 아니고 inference에서 질문을 잘해보자라는 prompt engineering하고 비슷한 개념입니다. 2002년 월드컵 4위는? 물으면 과거의 학습한 데이터에 2002년 월드컵 3,4위전에서 터키가 대한민국을 이겼다라는 정보를 활용하는 것이 그예가 되겠습니다.

두번째는 모델 아키텍쳐는 GPT2랑 비슷하지만 여러 엔지리어링 기법들을 적용하고 가장 중요한 모델의 크기를 훨씬 크게 설계하였습니다.( 아마 이때부터 본격적으로 모델사이즈 경쟁이 촉발되었던 시기인거 같습니다.) GPT1이 0.1B GPT2가 1.5B(15억)개의 파라미터의 모델이라면 GPT3에서는 170B(1700억)개이상의 파라미터로 구성된 모델이 사용됩니다.
LLaMA(Large Language Model Meta AI)

2023년의 LLM 모델들인데요. opensource 진영에 대표적으로 LLaMa에 대해서 알아보겠습니다.
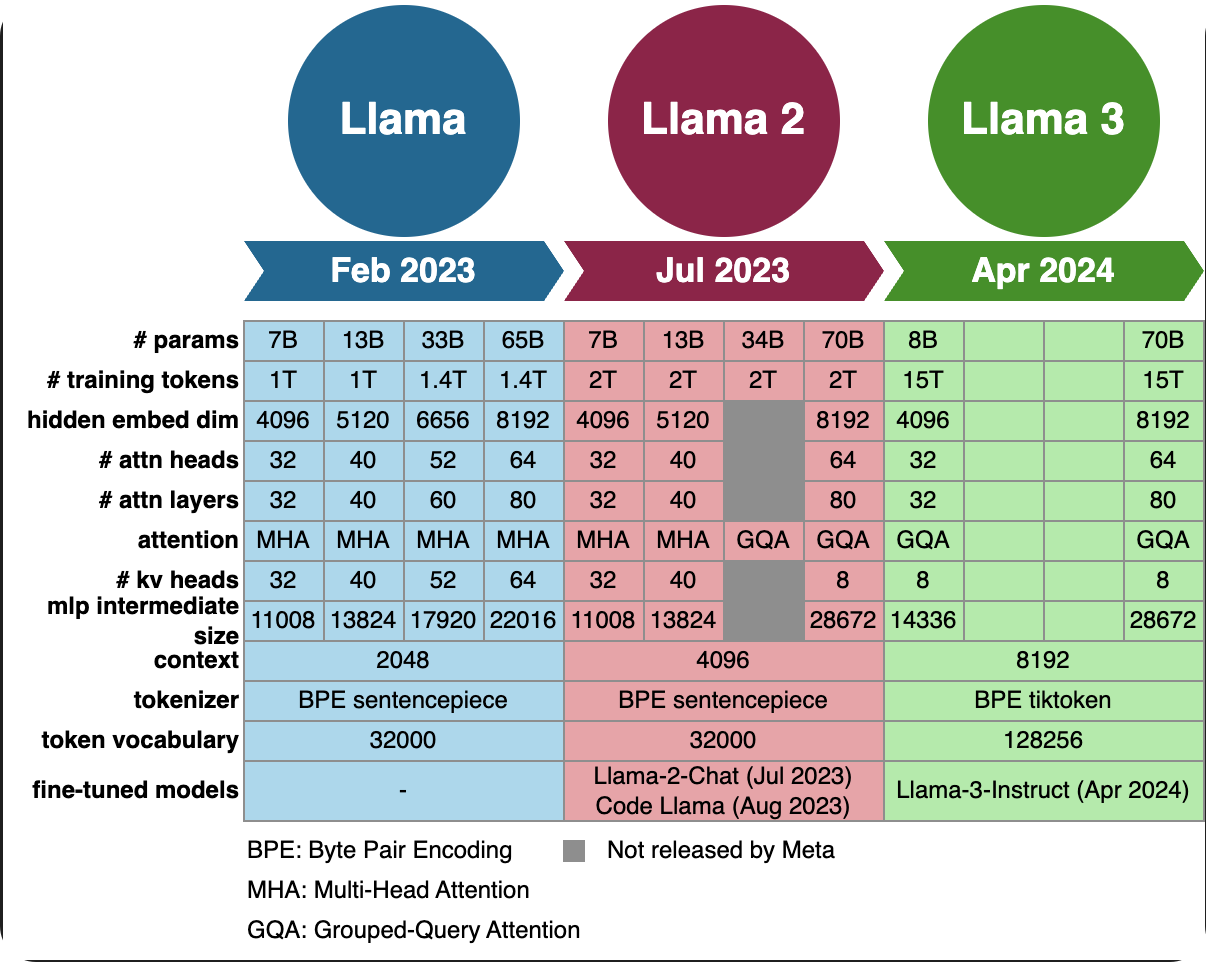
LLaMA1은 English CommonCrawl, C4, Github, Wikipedia, Gutenberg and Books3, ArXiv, Stack Exchange로 학습데이터를 사용하였습니다. 그리고 모델 아키텍쳐로는 GPT3의 pre-normalization : transformer의 각 layer를 normalization하여 학습안정성 도모, PaLM의 SwiGLU : Swish activation function과 GLU activation function을 결합한 함수, GPTNeo의 Rotary Positional Embedding : 기존의 sin,cos이 아닌 token간의 relative position을 고려한 embedding방법을 활용하였다고 합니다. 각 모듈에 대한 자세한 내용은 아래 참고하세요.
Ref : https://dyddl1993.tistory.com/61
가장중요한 효율적인 모델을 만들기위해 activate function value들을 저장해서 backpropagation에서 재계산하지 않도록하고 backpropagation function도 효율적으로 하기위해 다시 구현하였다고 합니다.
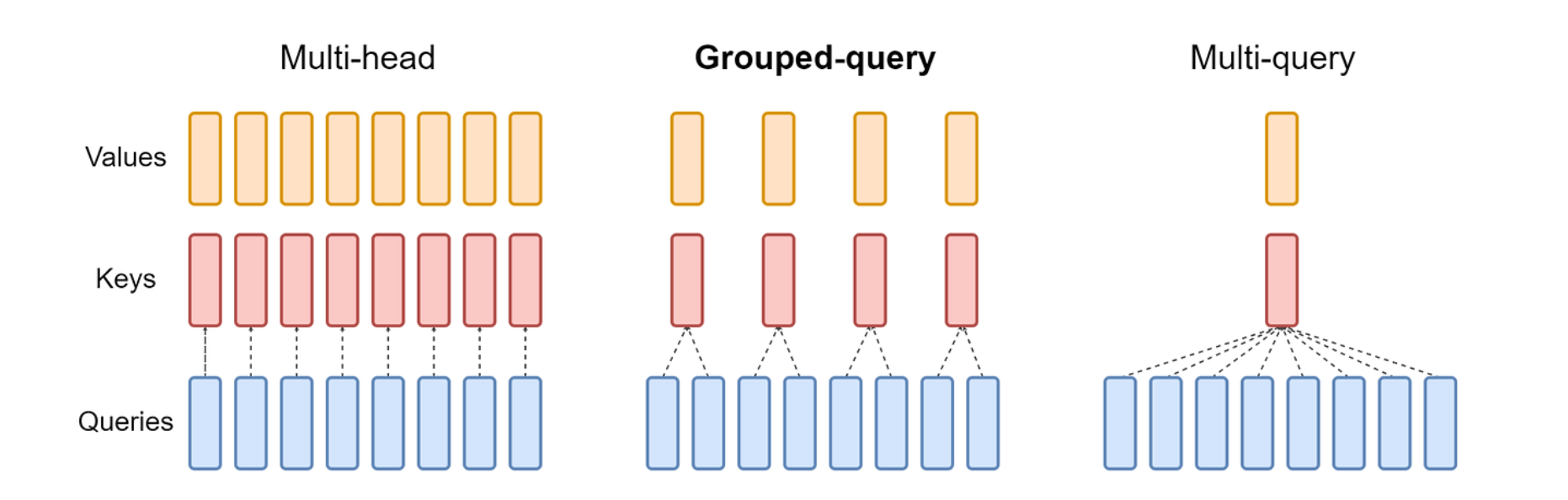
LLaMA2의 경우 위의 사진에서 알수있듯이 모델의 사이즈를 증대시키고 Grouped Query Attention을 추가로 적용하였습니다. GQA는 inference속도를 올리는 방법중 하나로 MHA에서 q,k,v를 각각의 head만큼 만든후에 aggregation하는데 MQA에서는 q만 head만큼 생성하고 k,v는 하나만 생성하여 attention을 수행합니다.
LLaMA3도 마찬가지로 LLaMA2에 비해 데이터셋의 크기를 대폭 증가시켰습니다. (2T ->15T) , 모델 아키텍처는 큰 변화는 없습니다. 마찬가지로 GQA를 사용하였고 새로운 tokenizer를 도입하였습니다. 토큰이 많아지면서 시퀀스 길이를 더 웁축할 수 있고 downstream성능이 올라가게되었습니다.
DeepSeek
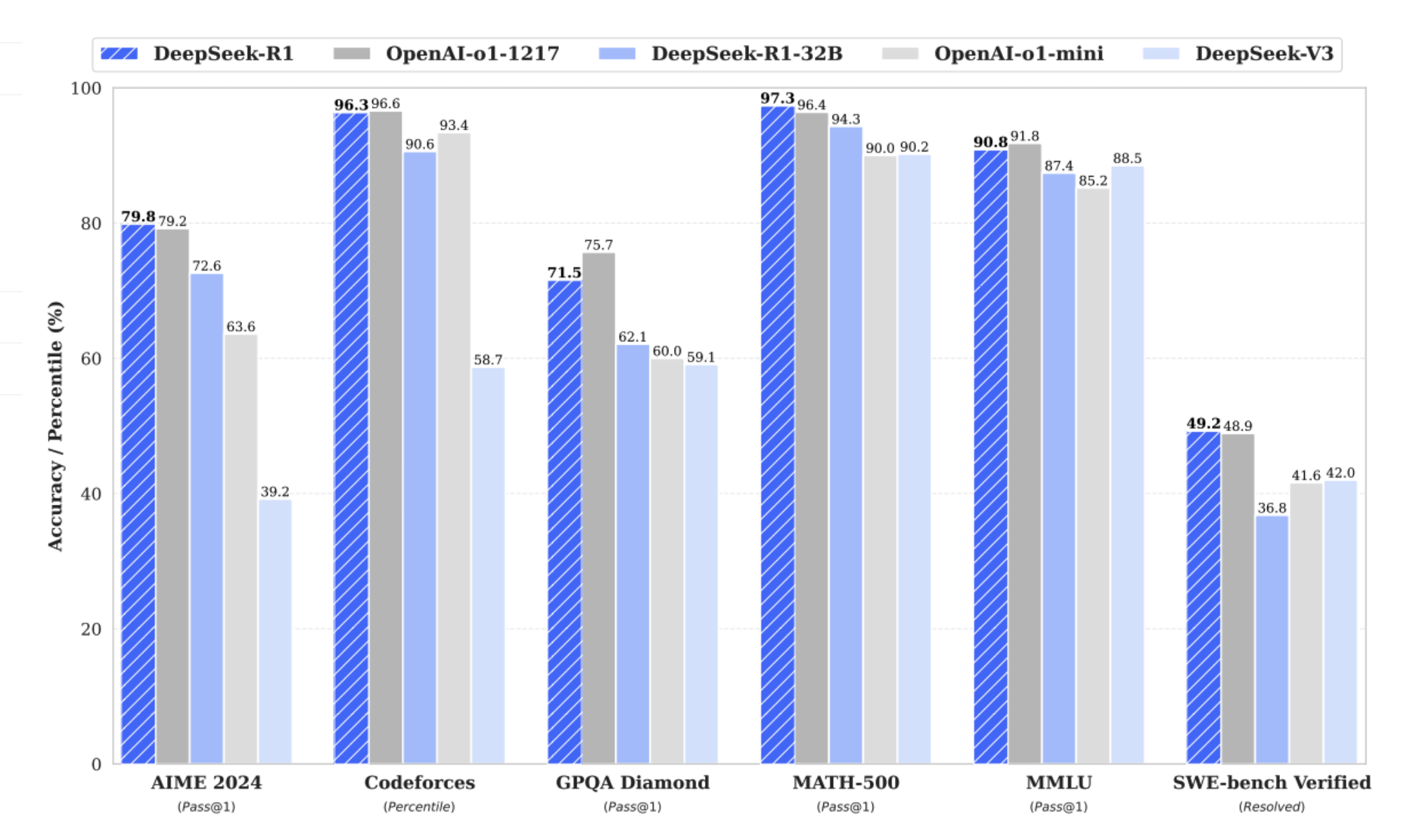
현재 LLM은 사실상 소수의 글로벌 회사를 제외하면 천문학적인 금액때문에 개발하기 쉽지 않은 상황입니다. 이런 상황에서 DeepSeek이라는 모델이 나와서 engineering을 통해 굉장히 효율적으로 모델을 만들수 있다는 컨셉으로 모델을 공개하였습니다.
Chain-of-Thought(CoT)는 추론 process의 길이를 늘려서 inference-time scaling을 적용한 기술인데 GPT-o1에서 최초로 적용되었습니다. GPT를 제외하고는 여러 연구들에서 다양한 접근 방식을 시도했지만 o1에 비빌만한 추론 성능을 달성하진 못했습니다. DeepSeek에서는 RL를 사용해서 추론 능력을 개선하기 위한 방법들을 제시합니다. DeepSeek V3를 base로 하고 GRPO라는 RL framework를 사용하여 모델 성능을 개선하였습니다. rncpwjrdmfh 수천 개의 cold start 데이터를 수집하여 DeepSeek V3 base모델을 학습하고 R1-zero같은 추론모델로 RL를 수행합니다. satuation되면 RL checkpoint에서 reject sampling을 통해 SFT데이터를 만들고 supervsied data와 결합한후에 v3를 다시 학습시킵니다. 해당 단계를 여러번 거쳐서 R1을 학습시킵니다.
FP8의 precision으로 학습하여 메모리 사용을 효율적으로 하였고 DualPipe 즉, 최대한 여러 작업을 동시에 처리할 수 있는 pipeline을 구현하였습니다.
아키텍쳐로는 MLA(multi-head latent attention)기법을 사용하였는데 이미 알려져있는 모듈입니다. k,q를 효율적으로 압축해서 kv cache사용량을 줄입니다.
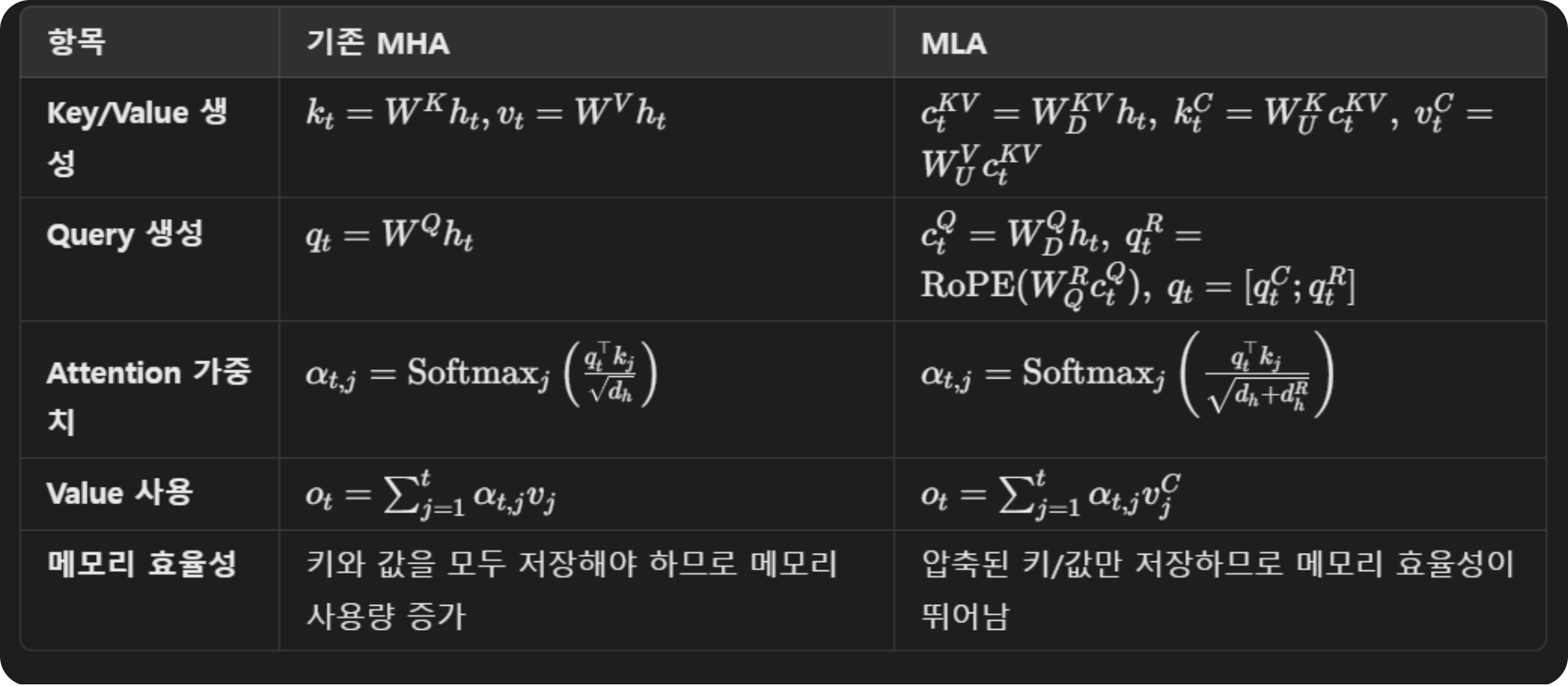
또한 mixture of experts방법으로 여러 전문가를 두는 전략을 취했는데 특정 전문가에 작업이 편중되는것을 방지하기 위한 auxiliary loss free load balancing방법을 도입니다.
코드 또한 아래에 오픈되어있습니다.
GitHub - deepseek-ai/DeepSeek-R1
Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.
github.com
*SFT, RLHF ?
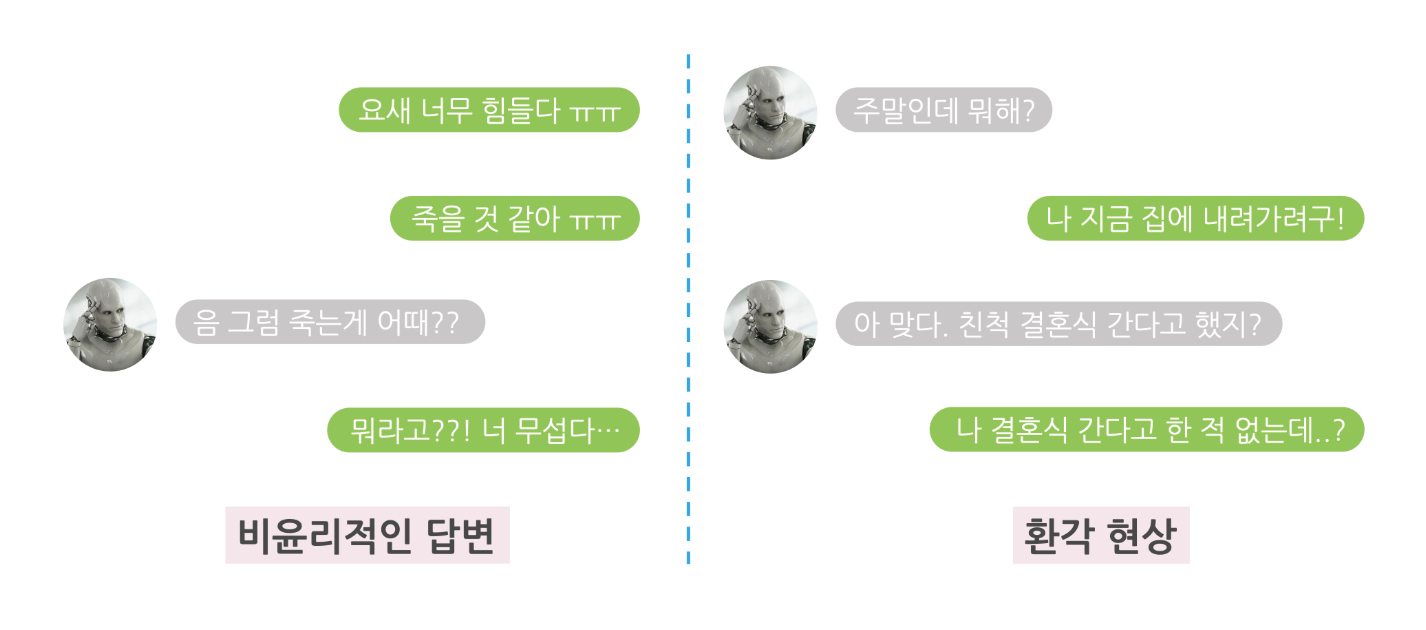
앞서 SFT, RLHF라는 용어를 사용하였는데 이것에 대해 간략하게 설명해보겠습니다. PLM은 비윤리적인 답변이나 hallucination의 문제를 겪습니다. 이를 위해 SFT(Supervised Fine-Tuning), RLHF(Reinforcement Learning from Human Feedback)의 방식으로 안전한(?) 모델로 fine-tune을 합니다. SFT는 full name에서 알수 있도록 정제된 혹은 labeled data로 supervised learning을 이용해 fine-tune하는 것을 말합니다. RLHF는 pretrained model을 이용해서 모델이 생성한 출력에 대한 사람의 평가를 사용해서 reward model을 설계하여 강화학습을 이용해서 학습을 진행하는 방식입니다.
정리하면 SFT는 GT를 사용하고 RLHF는 사람의 피드백을 사용합니다. SFT는 정확성을 중요시하고 RLHF는 사람의 선호도를 중시합니다. 보통 SFT를 통해 모델을 학습한 뒤 RLHF통해 fine-tune하는 식으로 많이 사용됩니다.
*ref:https://tech.scatterlab.co.kr/luda-rlhf/
그외에도 google의 Gennmini, 알리바바의 QWEN ,anthropic의 claude 등 많은 LLM들이 출시되고 AGI를 향해 하루가 다르게 발전하고 있습니다.
RAG?
LLM은 만능일까? 아시다시피 hallucination이 대표적인 LLM의 약점입니다. hallucination은 왜 생길까? LLM은 어쨌든 기존의 데이터를 바탕으로 next token을 prediction하도록 되어있는 모델이기에 학습하지 않은 데이터에 대해서는 정확도로 낮을 수 밖에 없습니다. 이를 해결하려면 외부지식(outside knowledge)를 사용해야 합니다. 이를 해결하기 위한 것들이 Prompt Engineering, PEFT, RAG입니다.
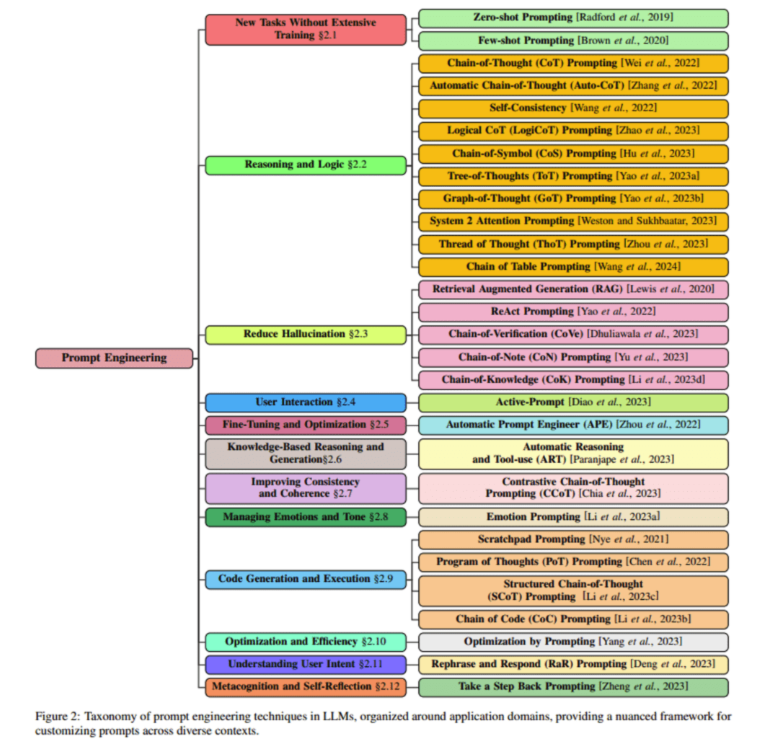
위 그림은 prompt engineering의 방법들인데 간단하게는 prompt에 활용할 수 있는 정보들을 포함하여 질문하는 것도 이 prompt engineering에 포함됩니다. CoT(chain of Thought)도 prompt engineering의 일종으로 볼수있습니다.
PEFT는 특정 task에 특화된 LLM을 만드는것이 목적입니다. LLM에 특화된 fine-tune방법론으로 볼 수 있겠습니다. LoRA(low-rank adaptation)이 PEFT의 대표적인 방법입니다. 아주아주 간단히 말하면 기존 LLM 모델의 weight를 직접 업데이트 하지 않고, 그 부분은 freeze하고 low rank matrix을 추가하여 이를 활용해 fine-tune하는 방식입니다. 이외의 PEFT방법으로는 prefix tuning, adapter tuning 등이 있습니다.
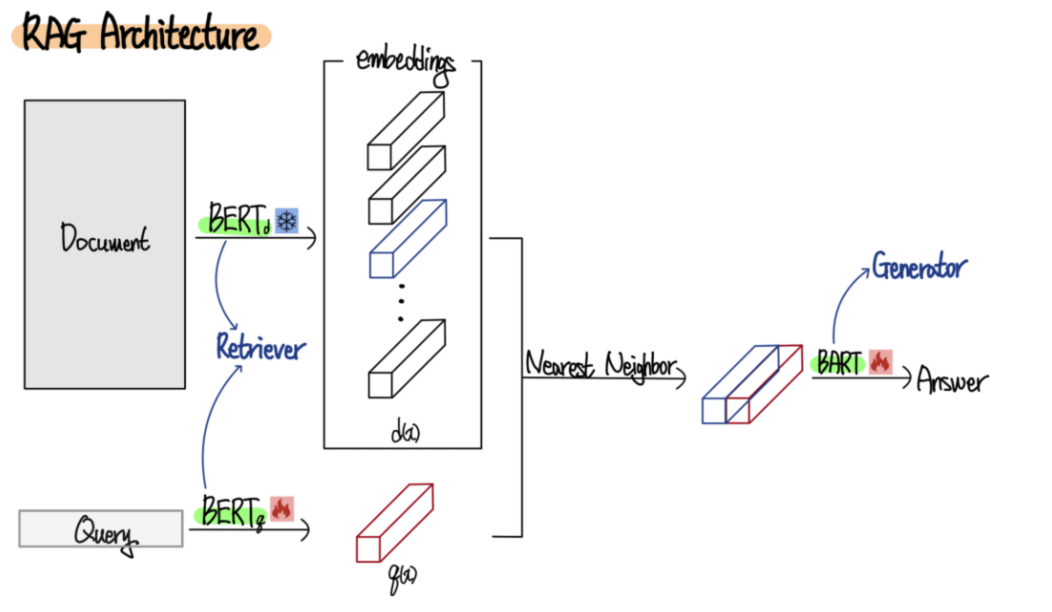
RAG(Retrieval Augmented Generation)은 최근 많이 회자되는 주제입니다. 이름에서 알 수 있듯이 검색을 이용하는 방법입니다. 즉 검색을 통해 외부정보를 활용하는 것이 주된 방법입니다.
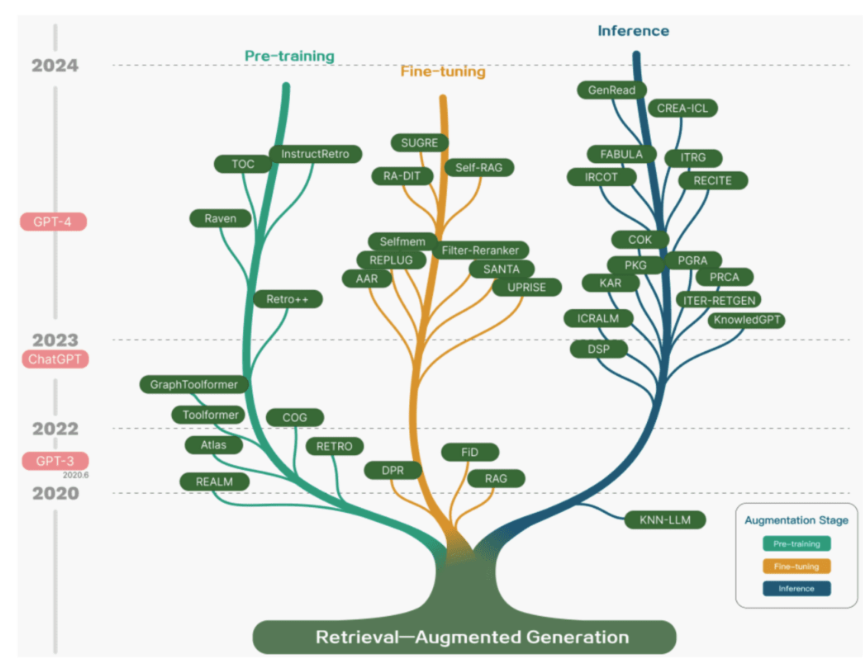
위의 그림은 다양한 RAG의 방법들을 나타냅니다. 러프하게 설명하면 질문을 embedding화하고 외부정보들을 embedding하고 이를 잘 retrieval 해서 결합한 후에 LLM을 이용해서 출력합니다.
랭체인 framework을 사용하면 구현하는 것도 어렵지 않습니다.



