vision에서의 foundation model, diffusion model등의 유래는 사실상 자연어 처리분야(NLP)에서 시작되었습니다. 자연어 처리 모델들이 점점 커지면서 최근에는 BERT, GPT, LLAMA, GERME, SOLAR 등의 여러 LLM모델들이 출시되고 있습니다. LLM의 시작부터 최근이야기까지 포스팅해보겠습니다.
자연어 처리 모델은 보통 document classification, sentence pair classification, named entity recongnition, question answering, sentence generation등의 과제가 있고 입력으로 자연어를 받아 임베딩과정을 거쳐 최종적으로 어떤 범주 혹은 어떤 단어일지 확률을 return하는 방식입니다.
transfer learning
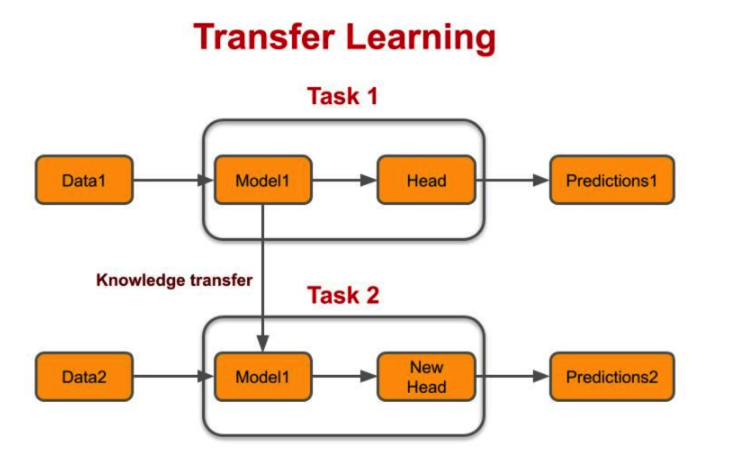
transfer learning은 요즘의 딥러닝모델에서는 거의 기본적으로 사용하는 기법입니다. 개념은 특정 task를 학습한 모델을 다른 task 수행에 재사용하는 기법입니다. 구체적으로 upstream은 대규모 data를 이용해 학습하는 task, downstream은 보통 많이 사용하는 기법으로 upstream을 통해 학습한 모델을 이용해 좀 더 구체적인 task입니다. upstream의 문제를 학습하는 과정을 pretrained model을 만든다고 합니다.
GPT계열의 모델은 upstream중 하나인 다음 단어 맞추기 방법을 이용해 대량의 말뭉치 데이터를 학습하였습니다. 중간중간 빈칸을 넣고 이를 맞추게 하여 문맥을 이해할 수 있도록 모델을 학습하였습니다. 이렇게 다음 단어 맞추기 혹은 빈칸 채우기 방법을 이용해 self-supervised learning을 수행하였습니다.
downstream의 대표적으로 classification, 분류, 추론등 이 있습니다. 최근에는 보통 위에서의 upstream task에서 학습한 pretrained model을 이용해서 fine-tune을 하는 방식으로 학습하고 있습니다.
* fine-tuning : down-stream task의 데이터 전체를 사용
* zero-shot : down-stream task의 데이터를 사용하지 않고 바로 task수행
* one-shot, few-shot: : down-stream task의 데이터 하나 혹은 일부만 사용
Tokenization
토큰화는 문장을 토큰 시퀀스로 나누는 과정입니다. 이를 수행하는 프로그램을 tokenizer라고 합니다. 대표적으로 mecab, kkma등이 있습니다. 토큰화 하는 방법은 단어 단위로 하는 방법, 문자 단위로 하는 방법, subword를 기반으로 하는 방법이 있습니다. subword를 기반으로 하는 방법중 byte pair encoding:BPE이 가장 유명한 방법중 하나로 자주 나오는 문자를 subword로 치환하여 토큰으로 분석하는 방법입니다. GPT는 이 BPE와 비슷하 wordpiece방법으로 Tokenization을 수행합니다.
Language Model

언어 모델은 결국 이전 시퀀스와 input을 고려해서 다음번에 어떤 단어가 나올 확률이 가장 높은지 찾는 모델입니다.
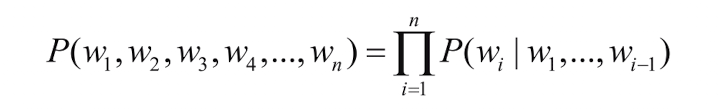
위의 수식은 조건부확률을 나타내는데, 이전 단어들이 주어졌을 때 다음 단어가 등장할 확률의 연쇄를 표현합니다.
순방향의 언어모델은 이전 단어들이 주어졌을 때 다음 단어 맞히기를 의미하고 GPT, ELMo의 모델이 대표적인 예입니다. 역방향 언어 모델은 뒤부터 앞으로 계산하는 방식으로 ELMo는 순방향과 역방향 방식을 다 사용합니다.
mask language model은 빈간에 단어를 추론하는 과정으로 학습합니다. BERT가 대표적인 예입니다. mask방식은 전체 문장의 맥락을 참고할 수 있다는 장점이 있습니다. skip-gram model은 특정 단어 앞뒤에 범위를 정하고 이 범위 내에서 어떤 단어가 올지 추론하는 방식으로 학습합니다. word2vec 임베딩 방법이 이 방식으로 학습하였습니다.

이를 딥러닝 모델에 적용시켜보면 방식에 따른 주변의 context가 조건으로 정해진 상태에서 특정 단어(w)가 나타날 확률을 구하는 것으로 대표할 수 있고 대표적인 모델 아키텍쳐로 transformer를 사용합니다.
[Transformer] Transformer & Vision
안녕하세요. 이번 ML관련 포스팅에서는 Transformer관련하여 포스팅하겠습니다. 이미 나온지 꽤 오래되었고 많은 분야에서 활용되고 있는 아키텍쳐인데요. NLP분야에서 일찍이 탄생했지만 비전 및
jaehoon-daddy.tistory.com
자세한 transformer의 원래는 위의 포스팅을 참고하면 되겠습니다.
BERT & GPT
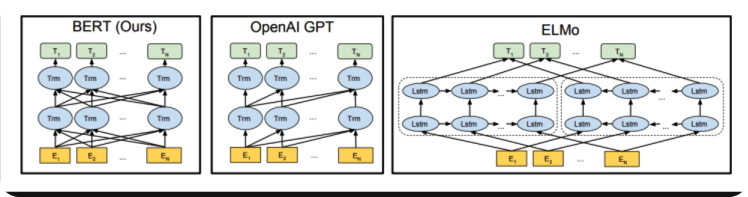
대표적인 Transformer기반의 LLM인 BERT와 GPT를 보겠습니다.
GPT는 문장 생성에 BERT는 문장의 의미를 추출하는데 강점을 가집니다. 그 이유는 (1)에 소개했다시피 GPT는 순방향으로 학습하고 BERT는 mask방법으로 양방향으로 학습하는 성격을 띄기 때문입니다. 또한 BERT는 transformer에서 인코더 GPT는 디코더를 사용합니다.
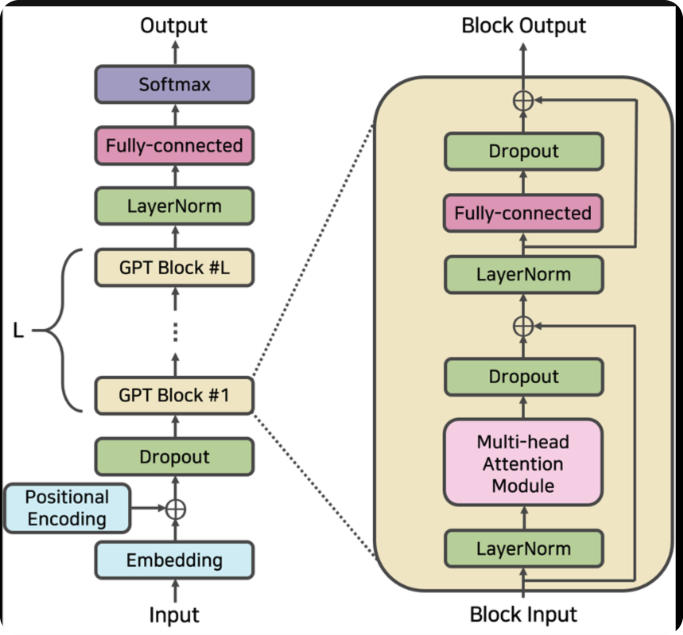
GPT는 transformer에서 디코더만 사용합니다. 예를 들어 "나는 어제 학교에 갔어" 라는 단어에서 나는 학교에 라는 단어를 맞춰야하는 상황에서 GPT는 나는, 어제 라는 단어만 참고할 수 있습니다. 나머지는 masking처리합니다.
BERT의 경우는 transformer에서 인코더만 사용합니다.

예를 들어 "나는 어제 학교에 갔어" 에서 학교에를 MASK하고 앞뒤 문맥을 참고하여 training합니다. 최근에는 점점더 LLM모델의 크기가 커지고 있고 GPT3의 경우는 175B까지 크기가 커졌습니다. 이를 finetune하기위해 quantization, pruning, wieght sharing, distillation등의 기법이 있고 대표적으로 lora가 있습니다.



