안녕하세요. 이번에는 모델 경량화 관련하여 포스팅하도록 하겠습니다.
경량화의 목적
경량화를 하는 이유는 보통 edge device에서 딥러닝 모델을 inference하고 싶은데 보통의 edge device의 리소스가 매우 제한된 환경일 경우 경량화를 생각합니다.
즉, 제한된 리소스에서 latency를 줄이고 throughtput을 높이기 위해 사용합니다.
속도를 높이기위해서는 quantinization을 하게 되는데 그 과정에서 정확도를 줄어들게 됩니다. 최대한 정확도를 유지하면서 속도를 높이는 것이 경량화의 목적이라고 할 수 있습니다.
[참고]
FLOPs?
FLOPs는 "Floating Point Operations per Second"의 약어로, 한 번의 연산에 필요한 부동 소수점 연산의 수를 나타내는 지표입니다. 이는 컴퓨터 시스템이 부동 소수점 연산을 처리하는 속도를 측정하는 데 사용됩니다.
딥러닝 모델의 복잡성은 일반적으로 FLOPs로 표현됩니다. 모델의 FLOPs는 모델의 크기와 구조에 따라 결정되며, 모델이 얼마나 많은 연산을 수행해야 하는지를 나타냅니다. 따라서 FLOPs가 높을수록 모델이 더 복잡하고 계산량이 많은 것을 의미합니다.
경량화의 방법들
- Network Architecture
첫번째로는 모델의 아키텍쳐를 좀 더 compact하게 하는 방법이 있습니다. 하지만 최근 zero-shot, generalized model이 대두되면서 해당 방법은 트렌디하지는 않습니다.
- Network Pruning

중요도가 낲은 channel, filter, layer 들을 pruning하는 방법과 matrix를 직접적으로 pruning하여 sparse computation을 하는 방법이 있습니다.
- Knowledge Distillation
Distillation방법도 매우 유명합니다. 보통 large model을 teacher network라고 하고 teacher model을 이용하여 strudent network를 학습하는 방법입니다.
- Matrix Decomposition
matrix를 decomposition해서 작은 tensor(vector)의 조합으로 표현합니다. 최근 LLM모델의 finetune에서 많이 사용하는 Lora가 대표적인 방법입니다.
- Network Quantization
float32로 이뤄진 parameter를 float16 혹은 int8로 변환하는 방법입니다. 보통 weight나 activation function이 어느 일정 범위에 있다는 것을 가정하고 보통 bit수를 N배 줄이면 복잡도는 N*N이 줄어듭니다.
Quantization은 inference시에만 사용하며 module fusion(layer들을 그룹핑) -> calibration(H/W에 디펜던시함) -> weight conversion순으로 진행됩니다.
위의 그림은 calibration의 예로 float32의 일정 범위에 있는 값들을 int8사이에 calibration해서 매핑하는 과정입니다.
Framework
경량화의 대표적인 framework로는 tensorRT, ONNX, apex등이 있습니다. 하나씩 살펴보겠습니다.
-Apex
Apex란 A Pytorch Extension으로 pytorch에서 mixed precision을 쉽게 사용할 수 있도록 해줍니다. Apex에 amp라는 library가 있는데 이는 방금 언급하였던 mixed precision으로 학습할 수 있도록 하는 툴입니다. 사실 Apex는 아래 설명할 ONNX, TensorRT와는 다르게 training 타입에 사용하는 툴입니다.
mixed precision이란 FP16(float16)과 FP32(float32)를 mix해서 사용하는 방법으로 처리 속도를 높일 수 있습니다.
-ONNX
ONNX는 사실 inference속도 높이는 장점 외에도 여러 장점들이 존재합니다. ONNX의 full name은 Open Neural Network Exchange로 다른 딥러닝 framework에서 만들어진 model들이 호환될 수 있도록 만들어진 framework입니다.
예를 들면 pytorch에서 만든 모델을 web에서 돌린다거나 mobile환경에서 돌리는데 onnx를 사용합니다.
그렇기 때문에 보통TensorRT engine을 뽑아낼때 pytorch로 딥러닝 model 아키텍쳐를 만들고 ONNX를 사용해서 ONNX model변경한 후에 TensorRT로 변경합니다. (최근에는 pytorch에서 바로 TensorRT로 추론하는 방법도 있습니다. torch-tensorrt)

위 그림은 pytorch로 만든 model를 ONNX로 변환하는 과정을 도식화한 것입니다. export를 하게 되면 JIT compiler인 TorchScript를 통해 trace or script를 생성합니다. 이 과정에서 optimized graph가 만들어지게 됩니다.
위에서 언급한 Tracing방법과 script방법을 보면, tracking방법은 example input을 model에 넘겨 forward propagation이 한 번 수행 됩니다. 이 때 execution path에 존해한 연산들이 IR(중간언어)로 기록이 됩니다. 문제는 만약 dynamic control flow가 존재한다면(i.e. if문) forward propagation에서 거쳐가지 않은 부분은 tracing하지 않습니다. 또한 example input의 shape에 따라서 graph가 고정되어 버리기 때문에 example input과 동일한 형태의 input을 넣어야합니다.
반면에 scrip는 전체 코드를 컴파일해서 scriptmodule instance를 생성합니다. 그렇기 때문에 tracing의 단점을 커버할 수 있지만 지원하지 않는 python API들이 많습니다.
-TensorRT
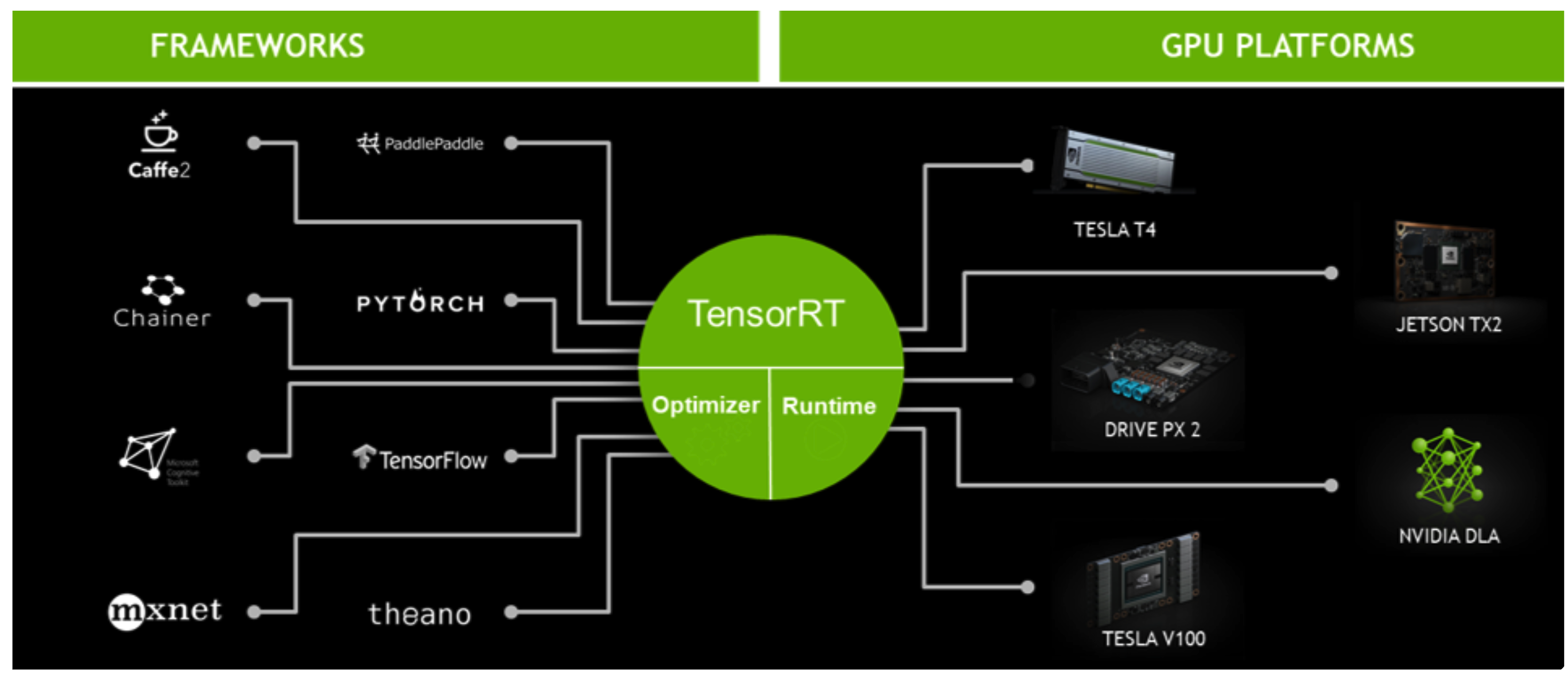
TensorRT는 Nvidia에서 만든 연산 최적화 framework입니다. 따라서 Nvidia GPU에서만 사용할 수 있는 기술입니다.
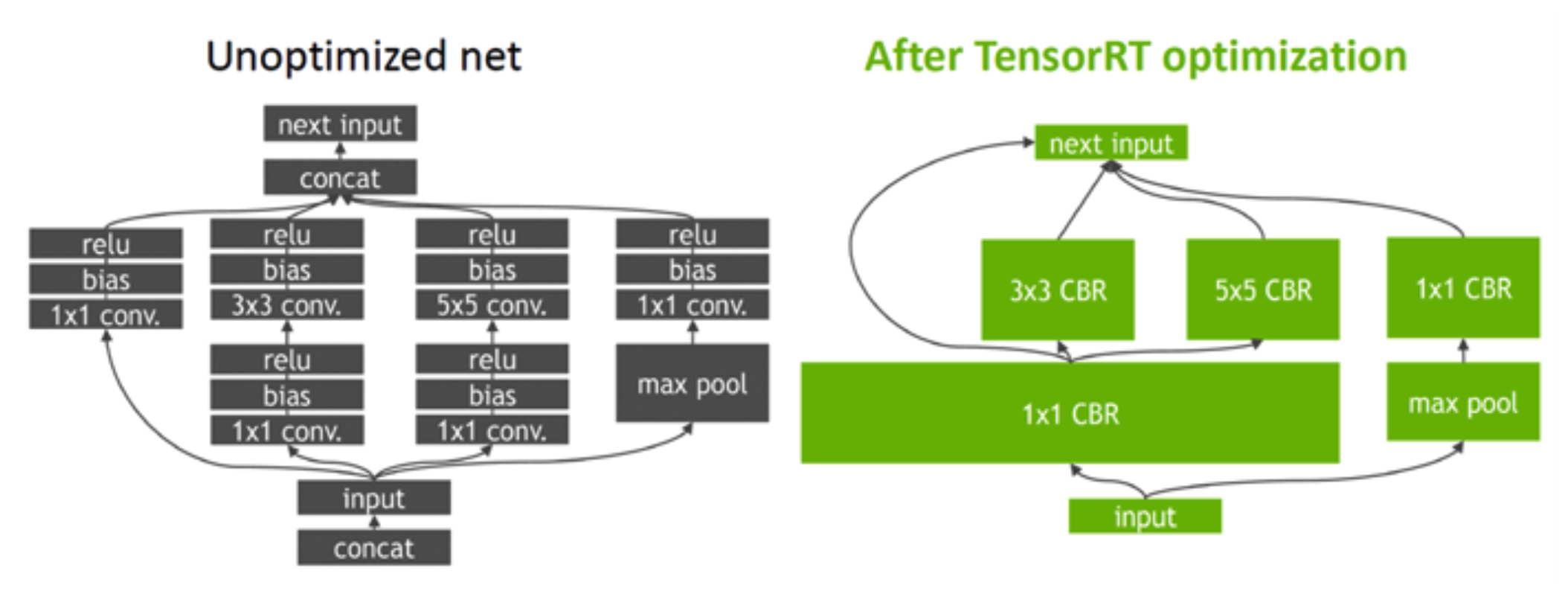
graph optimization을 사용해서 여러단계로 설정되어 있는 layer들을 fusion하거나 동시에 연산해서 속도를 향상 시킵니다.
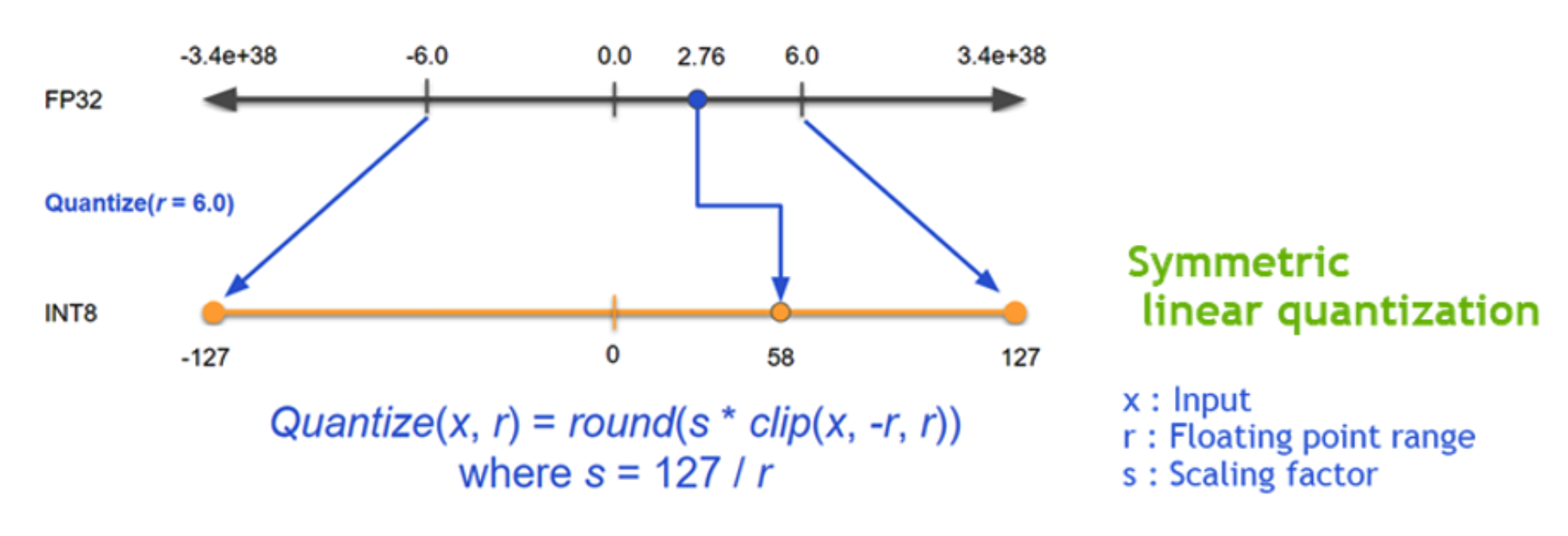
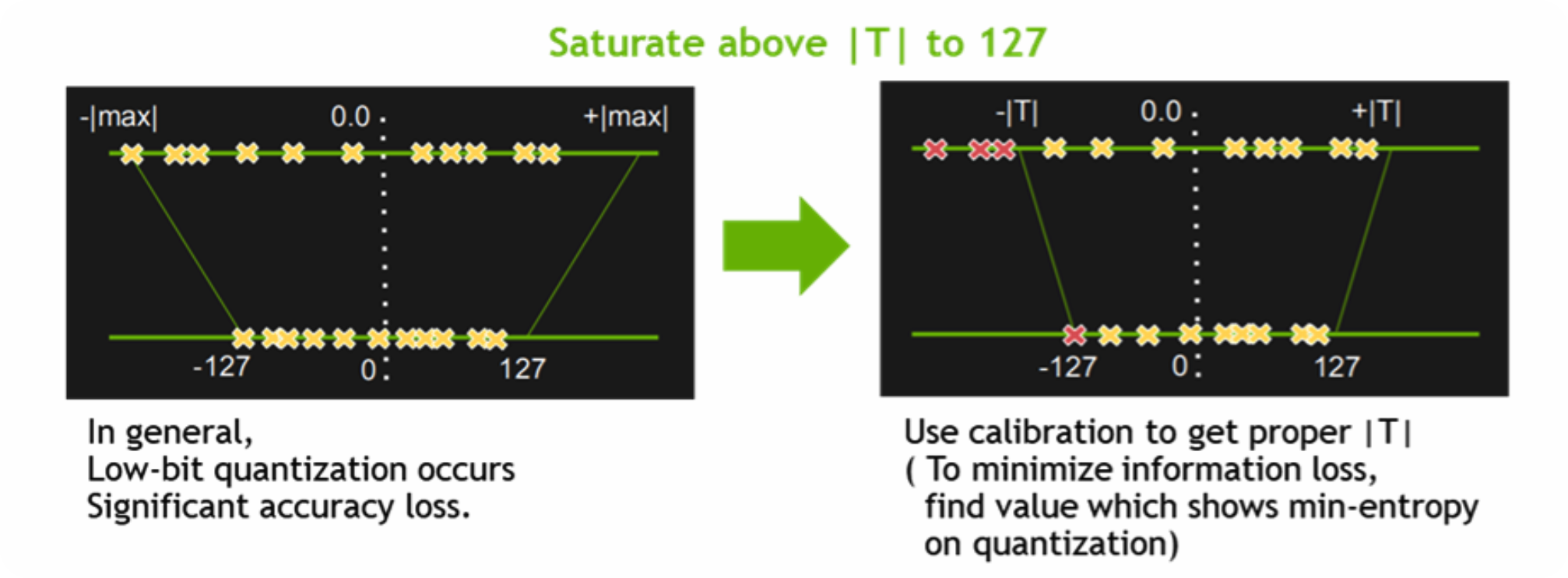
다음으로는 quantization & precision calibration입니다. FP16, INT8 타입까지 quantization 기술을 지원합니다. DRAM에서 로드할 데이터의 크기가 줄면 연산시간은 당연히 줄어듭니다. reduced precision은 accuracy-drop이 문제가 되는데 precision calibration을 통해 극복합니다.
TensorRT를 사용하면 사용하는 GPU플랫폼마다 engine파일을 각각 생성해줘야 합니다. GPU플랫폼마다 해당 아키텍쳐에 최적화된 runtime을 따로 생성해주기 때문입니다.
[참고]
engine파일은 blob형식으로 저장되는데 이진수 형태로 저장하는데 사용되는 방법입니다. 저장할때는 이진수로 serialize하고 runtime으로 불러올때 이를 deserialize합니다.
* reference
- apex
- onnx



