안녕하세요. 이번 포스팅은 image detection 시리즈 3편을 포스팅하겠습니다. 사실 단일 task의 detection은 DL computer vision에서 사실상 의미가 없는 수준이 되었습니다. 그러면서 multi-modal, foundation model을 통해 zero-shot, few-shot learning이라는 흐름으로 넘어간 상황입니다. 그렇기 때문에 제목을 detection history에서 cv history로 변경하였습니다.
최근 LLM분야에서는 huge foundation model들이 각광을 받고 있습니다. 글로벌 회사들에서 하루가 멀다하고 이런 foundation model들을 배포하고 있는대요. foundation model이란 간단하게 말하면 엄청난 huge data로 학습한 model을 의미합니다. 그렇다면 이런 foundation model을 왜 만들었을까요? 물론 성능적인 관점도 있지만 엄청난 generalizability때문입니다. 즉, zero-shot, few-shot learning이라는 단어에서 알 수 있듯이 몇장의 input data만으로도, 심지어는 input data없이도 user의 task에 down-stream하여 사용할 수 있다는 의미입니다.
Text 분야에서는 일찍이 이런 foundation model들이 존재했지만 image분야에서는 여러 허들이 존재하여 어려움이 있었는데, meta에서 segment anything이라는 비전영역(segmentation)의 foundation model을 오픈소스로 배포하였습니다. 그 이후로 엄청난 data를 기반으로 각각의 도메인에서 sota성능을 찍는 모델들이 우후죽순으로 나오고 있습니다.(depth anythin, 4M ...)
각각의 도메인에 이런 foundation model들이 어떤 것들이 있는지 보겠습니다.
SAM(segment anythin)
SAM모델은 segmentation 분야의 foundation 모델입니다. prompt(text, point, box)를 이용하여 segmentation을 수행합니다.
prompt를 이용한 튜닝은 VPT(Visual Prompt Tuning)라는 논문을 참고하였다고 합니다. 보통 fine-tune을 한다고 할때 pretrained model에서 learning rate를 작게하여 재학습시키거나 head부분만 backpropagation시키고 나머지 layer는 freeze하는 방법을 사용합니다.

Prompt의 종류는 point, box, text를 input으로 받을 수 있도록 디자인하였습니다.
전체적인 아키텍쳐의 위의 그림과 같습니다.
encoder같은 경우 pretrained ViT를 사용하여 image embedding을 얻게 됩니다. prompt encoder는 입력을 종류마다 다른데 text의 경우 CLIP을 사용하고 sparse(point,box)는 positional encoding, dense(mask)는 conv를 태워서 이미지 embedding과 element-wise summation하여 추출합니다.
mask decoder에서는 image embedding과 prompt embedding을 받아서 마스크를 예측하는 부분입니다. self-attention과 cross-attention을 양방향으로 사용하였습니다.
문제는 Dataset인데 text기반의 LLM모델들은 비교적 쉽게 데이터를 구할 수 있고 문장 중간에 masking을 해서 self-supervised learning으로 비교적 쉽게(?) 설계할 수 있지만 segmentation은 마스킹 정보를 구하거나 작업을 하는게 많은 수고를 필요로 합니다. SAM에서는 우선 작업자가 점을 찍어 대략적인 마스킹을 하고 마스킹이 있는 데이터로 학습한 모델로 대략적인 레이블링을 합니다. 이 후 작업자와 model이 동시에 작업을 하고 수정을 하면서 model을 발전시켜 나가는 방식으로 학습을 하였습니다.
마지막으로 예를 들면 point로 prompt를 할때 어떤 object의 mask를 얻고싶은건지 확실하지 않아서 마스크후보 3가지를 전달하게 됩니다.
아래와 같은 awesome sam이라는 github 에서는 이러한 foundation model sam을 활용하여 다양한 도메인에 downstream한 모델들을 소개해줍니다.
GitHub - Vision-Intelligence-and-Robots-Group/Awesome-Segment-Anything: A collection of project, papers, and source code for Met
A collection of project, papers, and source code for Meta AI's Segment Anything Model (SAM) and related studies. - GitHub - Vision-Intelligence-and-Robots-Group/Awesome-Segment-Anything: A coll...
github.com
Depth Anything
다음으로는 depth분야에서의 zero-shot learning을 수행할 수 있는 모델인 depth anything을 보겠습니다. SAM에서 보면 알 수 있듯이 더 이상 모델의 아키텍쳐를 이리저리 바꾸는건 중요하지 않습니다. 오히려 huge data를 구하고 preprocessing을 잘해서 transformer기반의 모델이 학습할 수 있도록 해주는 pipeline이 더 중요합니다.
표를 보면 알 수 있듯이 Depth도 segmenation과 마찬가지로 labeling을 하기 쉽지않고 GT가 있는 데이터가 많지 않습니다. 그래서 우선 Label이 있는 데이터를 이용해서 모델을 학습시킵니다. 모델아키텍쳐는 ViT를 기반으로하는 DINO v2의 백본을 사용하였다고 합니다.

Domain adaptation기법과 비슷한 양상의 띄고 있는데, label이 있는 데이터를 활용해서 teacher model을 만듭니다. 이후 unlabeled data는 teacher model를 이용하여 pseudo GT를 이용해서 학습을 진행합니다. 하지만 pseudo GT이기 때문에 정확하지 않습니다. 이를 보완하기 위해 encoder가 너무 많이 변하지 않도록 constraint term을 추가하고 또한 CutMix나 Gaussian blurring을 통해 augmentation을 추가하여 이를 극복하였다고 합니다.
실험결과 한번도 학습하지 않은 KITTI dataset도 zero-shot 으로 sota를 찍는 성능을 이끌어냅니다.
M4
마지막으로 M4모델은 huge data를 이용해서 다양한 task에 활용할 수 있는 transformer기반의 versatile model입니다.
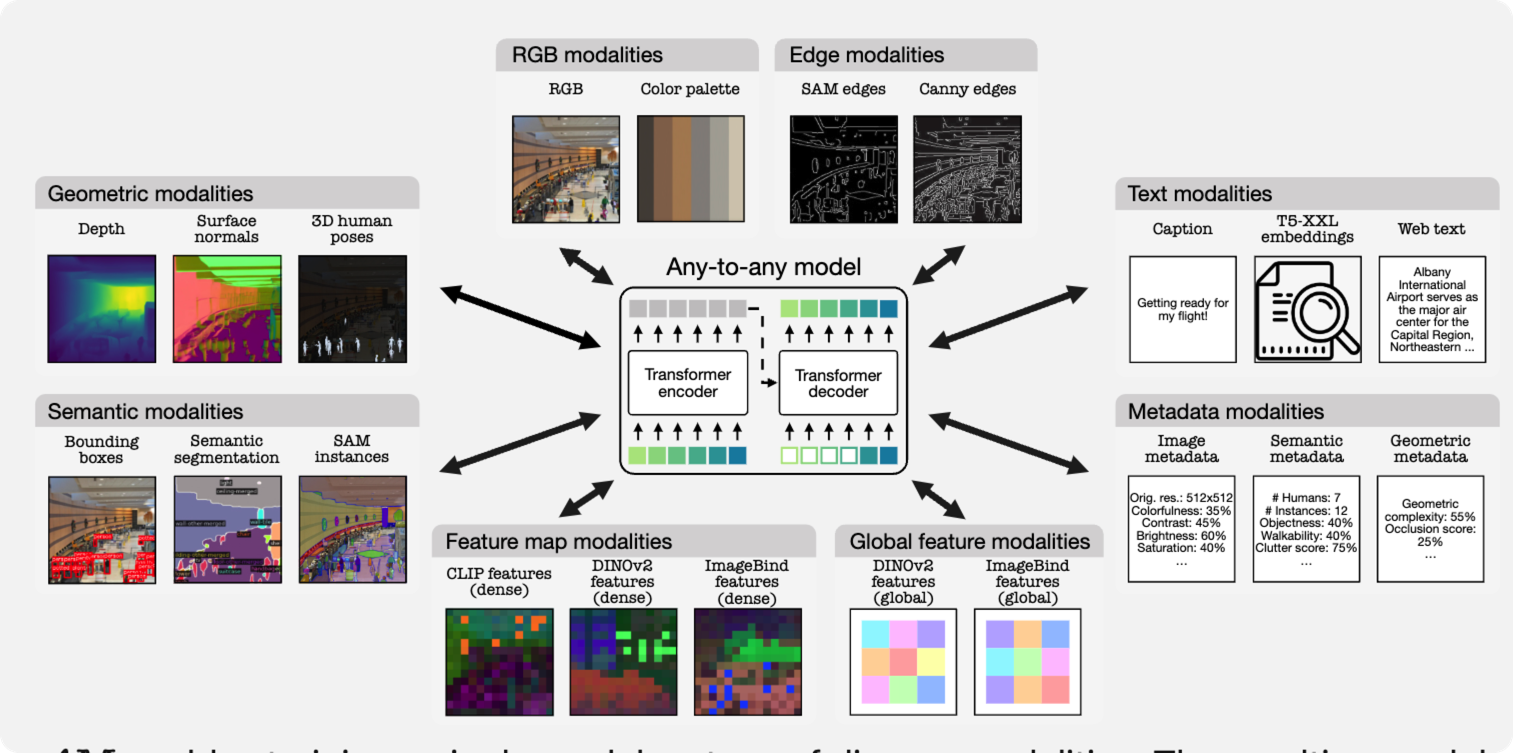
그림에서 보는 것처럼 하나의 transformer기반의 encoder decoder를 이용해서 다양한 task에 적용할 수 있는 모델입니다.
위의 비디오는 어떻게 학습하는지를 매우 쉽게 알려주고 있습니다. 즉, RGB, Depth, Segmentation, Surface, Caption.. 을 각각 embedding을 구하고 그것들의 연관관계를 transformer의 encoder와 decoder를 통해 구하는 것이 전부입니다.
이보다 더 큰 문제는 이런 백데이터를 어떻게 구하고 처리하느냐인데 dataset 사이트를 보면 어떻게 데이터를 구성하였는지 나와있습니다.
이렇듯 최근의 Computer Vision의 흐름이 transformer가 vision에 적용되면서 LLM에서의 foundation model들과 비슷하게 엄청난 데이터를 이용해 transformer base model을 학습시켜서 downstream하여 다양한 task에 적용시키거나 zero-shot으로 문제를 풀어버리는 것이 대세라고 볼 수 있겠습니다.




