안녕하세요. 이번포스팅은 YOLOE라는 논문에 대해서 다루겠습니다.
기존의 object detection들은 이제 수준이 많이 올라와서 꽤 정확하고 빠르기까지합니다. 하지만 여전히 한계가 존재하는데요, predefined categories 는 inference할수없는 부분입니다. 그러니깐 학습과정에서 정의한 class이외에는 예측할 수 없다는 점입니다.
YOLOE는 아래의 방법들을 사용하여 open-set의 문제도 풀수있는 model이라고 할 수 있겠습니다.
기존의 open-vocabulary object detection/segmentation method들을 살펴보면 Text Prompt기반의 방법은 보통 vision-language pretraining방법을 사용합니다. image features와 text embedding을 contrastive learning (self-supervision의 한종류) 로 정렬시켜서 미학습된 class도 인식하게 합니다. (GLIP, Grounding DINO, DetCLIP, YOLO-World) 하지만 corss-modal fusion의 computation cost가 큰 단점이있습니다.
다음으로는 visual prompt기반의 방법이있습니다. 특정 obejct의 시각정보(box, mask..)를 prompt로 사용하는 방법인데 T-Rex2, DINOv가 대표적입니다.
마지막으로 prompt-free방법인데 prompt없이 모든 객체를 탐지하고 해당 region에서 language모델을 이용해 이름을 생성하는 방식으로 detection -> describe방식입니다.
* open-vocabulary란 class name이 고정되지 않고 text embedding space로 표현됩니다. 사실 완벽하게 open space는 아니고 embedding vector의 space인 open-ended retrieval에 가깝습니다.

YOLOE에서는 이러한 방법들을 효과적하게 통합하여 open OD, OS 모델을 만드는것에 집중하였습니다.
Model architecture

기존의 YOLO의 아키텍쳐와 유사합니다. backbone, pan(neck - FPN을 보완한 feature 통합)에서는 multi-scale feature를 추출해서 feature map을 만듭니다. regression head에서는 anchor point에서 bbox를 regression하고 segmentation head는 YOLACT 스타일을 따랐습니다. 빠른 segmentation을 구현할때 흔하게 사용되는 방법입니다.
embedding head가 번경포인트인데 기존 YOLO에서는 classification head로 마지막 layer는 class의 개수에 맞춥니다. [N, C]
YOLOE에서는 open-set을 대응하기 위해 embedding 기반의 classification head로 변경했는데 출력 채널이 class개수가 아니라 임베딩 차원 D로 변경되었습니다. [N, D]

즉 anchor point의 embedding(NxD), prompt embedding (DxC) -> NxC [ N개의 anchor와 C개의 prompt간의 similarity score]
Re-parameterizable region-text alignment
open vocabulary 에서는 image feature와 text embedding의 alignment의 정확성이 매우 중요한데 기본의 방식들은 cross modal fusion방법을 사용하지만 매우 복잡하고 연산량이 많습니다. 그래서 YOLOE에서는 RepRTA전략을 제안하는데 복잡한 fusion대신에 light network로 finetune한 다음 YOLO의 classification head와 통합하는 전략을 사용합니다.
위의 그림에서 보다시피 training time에서는 auxiliary network에 text embedding결과를 input으로해서 finetune시킵니다. inference time에서는 YOLO의 classiciation layer로 re-parameterization해서 classification하게 됩니다.

training time에는 구체적으로 임베딩을 캐싱해서 학습중에 반복적으로 등장하는 고정된 단어들은 미리 계산해서 캐싱하게 합니다. YOLO에서 classification head는 일반적으로 1x1 conv layer로 각 class에 대한 score를 출력하는데 이를 kernel weight라고 합니다. 따라서 위의 수식을 풀어서 설명하면 I는 input image feature [D,H,W]이고 K는 마지막 conv layer로 DxDx1x1 shape입니다(kernel weight).그러면 I는 conv(K)를 거쳐 DxHxW가 되고 이를 reshape후에 HWxD로 만듭니다. f(p)부분은 CxD의 형태인데 transpose하게 되어 DxC의 형태가 됩니다. 이렇게 두개의 matrix를 곱하여 최종 HWxC가 나옵니다. (R은 reshape을 뜻하는것같습니다)

inference time에서는 auxiliary network이 앞서 언급한대로 re-parameterization합니다(YOLO classfication head). 이를 수식으로 나타낸건데 f(p)는 기존 학습된 text embedding이고 [C,D] 이를 reshape해서 conv커널처럼 CxDx1x1형태로 만듭니다(클래스 마다 1x1 conv를 생성하는 셈). 여기서 기존 kernel weight를 transpose 한후에 결합해서 최종 [C,D,1,1]을 만듭니다.
Semantic-activated visual prompt encoder
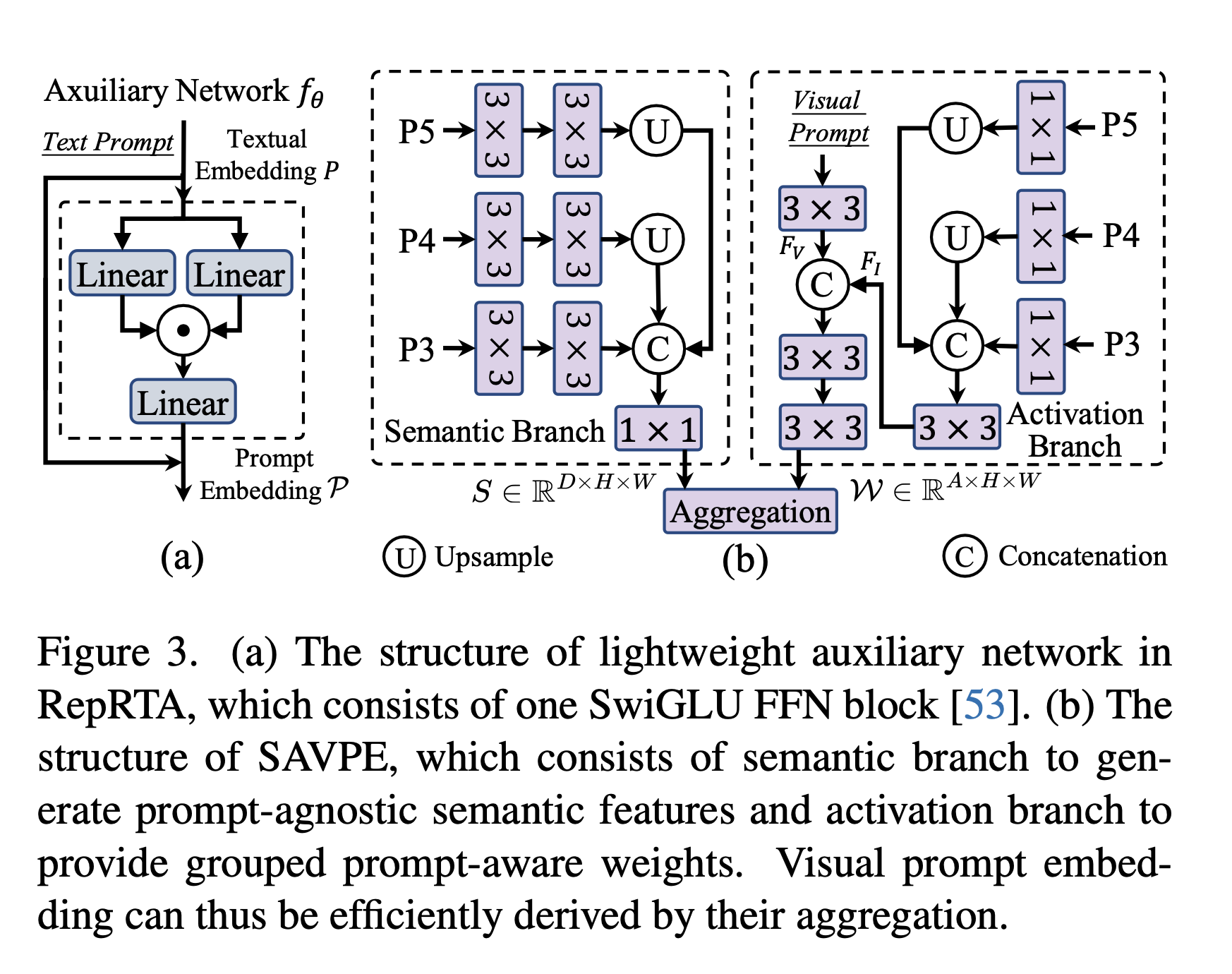
이번엔 visual prompt를 이용한 방법으로 기존의 transformer기반의 무거운 방법들(deformable attention, CLIP vision encoder..)비해 효과적인 방법을 제시합니다.
SAVPE는 분리된 가벼운 두개의 branch를 가지고 있습니다. 1번 branch는 semantic branch는 visual prompt와 fusion하지 않는 D채널의 브랜치로 semantic정보만 extracition합니다. 2번 branch는 activation branch로 매우 적은 channel에서 prompt 와 image feature를 interaction시켜서 prompt acitvation map을 생성합니다. 이 두개의 브랜치 출력을 합치면 풍부한 prompt embedding을 얻을 수 있다고 말하고있습니다.
Lazy region-prompt contrast
prompt-free방법은 기존에는 language model같은걸 붙여서 해결했습니다. 논문에서는 LRPC 전력을 사용하는데(아마 anchor마다 generative하게 language model에 무엇인지 물어보고 text를 생성하는방식) 이 방법은 language model에 대한 의존도가 없습니다.
object가 존재하는지 먼저 filtering하고 이후에 label을 retrieval하는 방식입니다.

specialized prompt embedding P하나만 학습을 해서 무엇이든 객체 탐지용 token처럼 동작하고 anchor embedding 집합(o)와 곱해서 일정 threshold이상의 것만 남깁니다. 두번째 검색에서 label voca를 text embedding으로 캐싱합니다.
요약하면
기존의 generative방식은 LLM에 이 이미지에 있는 object가 먼지 질문을 하기 때문에 느리고 무겁습니다. 반면 retrieval 방식은 filtered된 bbox내에 있는 물체를 찾기위해 text embedding 과 similiary를 비교해서 제일 유사한것을 선택하는 방식입니다.
그래도 4500개의 class와 filtered box간의 비교를 하면 꽤 computation cost가 들것같아 GPT에 질문을 하였습니다.

Experiments
*loss는 classification은 Binary Cross-Entropy Loss, Regression은 IoU loss, Distributed Focal Loss, Segmentation은 YOLACT방식의 Binary Cross-Entropy Loss사용
공정한 평가를 위해 YOLOv8,11과 동일한 아키텍쳐를 사용했다고 합니다. dataset으로는 Object365, GoldG, Flockr30k사용하였고 sam모델로 pseudo mask를 생성했다고합니다. training은 text prompt는 30epoch, SAVPE 2epoch, specialized prompt 1epoch만 진행하였다고 합니다. 주목할건 8개의 RTX4090에서 학습였다고 하네요.
text prompt평가는 벤치마크의 모든 카테고리 이름을 text promt입력으로 사용하였고 visual prompt는 T-Rex2방식을 따라서 각 카테고리별로 훈련 이미지 N장을 무작위로 뽑았다고합니다. prompt-free는 GenerateU와 동일한 protocol를 ㅅ용합니다.