안녕하세요. 이번 포스팅은 StreamPETR이라는 Multi-cam 3D detector에 대해서 포스팅하겠습니다.
StreamPETR은 PETR이라는 single frame multi-cam 3D detector에서 sparse query를 기반으로 하여 object-centric temporal mechanism을 적용한 모델입니다. online 방식으로 long-term historical 정보틀ㄹ object query를 통해 프레임단위로 전파하는 전략을 취합니다.
PETR모델은 이전 포스팅을 참고하고 이번 포스팅은 memory bank위주로 살펴볼예정입니다.

[paper review] PETR 논문리뷰 (3D detection w Cam)
안녕하세요 이번에는 PETR 이라는 camera기반의 3D detection 논문을 살펴보겠습니다.최근 camera를 기반으로하는 3D detection 논문들이 많이 나오고 있습니다. 현재 multi-cam 3D detection분야는 BEV 방법론과 p
jaehoon-daddy.tistory.com
Prior Knowledge
대표적인 temporal fusion의 방식을 먼저 소개합니다.

첫번째는 BEV 기반의 Temporal Modeling으로 이전 프레임의 BEV Feature를 현재 프레임에 align하여 temporal fusion을 수행하는 방식입니다.

여러 과거 BEV Feature를 정렬 후 concat 혹은 attention으로 정합합니다.
이 방법은 grid구조라서 object motion반영이어렵고 spatial dislocation이 발생할 수 있습니다.
두번째는 Perspective-based temporal modeling으로 object query가 여러 프레임의 image feature와 cross-attention을 수행합니다. 정확하지만 multi-frame attention으로 계산량이 증가하고 long-term 확장시 한계가 존재합니다.

세번째는 object-centric Temporal modeling방식으로 논문에서 제안하는 방식입니다. query를 시간의 carrier로 활용하여 이전의 query 상태를 기반으로 motion-aware 보정을 수행합니다.


이전 query상태와 현재 프레임의 query상태를 결합하여 시간 정보를 propagation합니다.

Method

크게 image encoder, memory queue, propagation transformer로 이뤄져있습니다. 이미지 인코더는 전형적인 2D백본으로 multi-view각각의 이미지에서 sematic feature를 extraction합니다. 그 후 feature들, 메모리 큐의 정보, object query가 propagation transformer 모듈로 입력됩니다. single frame하고 가장 큰 차이점은 memory queue에서 recursive하게 업데이트 된다는 점입니다.
Memory Queue
메모리 큐는 NxK(N : frame number, K : objects number/frame)로 설계하고 실험에 따르면 N=4, K=256이 적당하다고 합니다. 정해진 시간 간격마다 $\delta t$, context embedding, object center, velocity, ego pose 를 collection해서 메모리 큐에 저장합니다. Top-K의 object query만 저장되며 당연하게 FIFO방식으로 메모리 큐는 관리됩니다.
Propagation Transformer
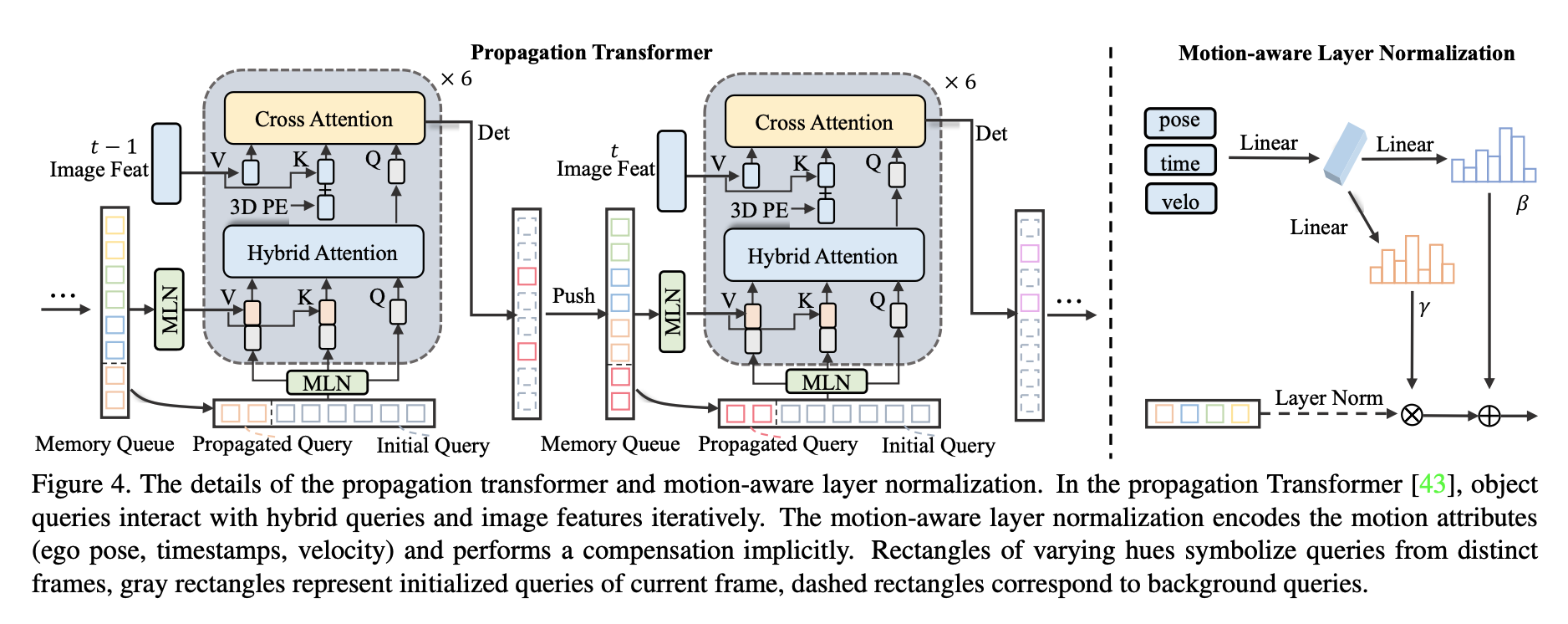
propagation Transformer부분은 크게 3가지 component로 이뤄져 있습니다.
MLN(motion-aware layer normalization)으로 메모리 큐에 저장된 context embedding + motion 정보를 이용해서 object query상태를 implicit하게 update합니다. MLN은 시간 흐름에 따른 motion을 반영하게 되는 부분입니다. Hybrid Attention은 기존 DETR의 self-attention대신 사용하였는데 현재 query + 과거 메모리뷰의 query를 결합한 attention입니다. 마지막으로 cross attention부분에서 image token과 object query간의 관계를 학습니다.
Experiments







