What is Graph?
그래프는 자료구조에서도 많이 나오는 키워드입니다. Node, edge로 구성되어 추상적인 개념을 다루기에 유리합니다. 소셜 네트워크, 바이러스 확산 등등의 모델링할 수 있습니다.

그래프를 나타내는 matrix로는 Adjacency matrix, Degree matrix, laplacian matrix등이 있습니다.
adjacency matrix는 노드 개수가 N일때 NxN의 크기를 갖습니다. i,j가 연결되어있다면 1, 아니면 0의 값을 같습니다. 따라서 symmetric한 성질을 가집니다. Degree matrix의 경우 마찬가지로 NxN의 크기를 갖고 node와 연결된 edge의 개수를 저장합니다.
대각행렬의 특징을 갖습니다. Laplacian matrix의 경우 node 자신의 정보까지 포함된 matrix입니다. degree matrix에서 adjacency matrix을 뺀 행렬입니다.
GNN(Graph Neural Network)?
그래프로 표현할 수 있는 데이터를 처리하기 위한 신경망의 한 종류입니다. 보통 CNN는 이미지에서 feature를 추출하고 RNN(LSTM)은 시계열데이터에서 feature를 추출하는데 사용됩니다.
위의 그림을 보면 CNN과 GNN의 유사하게 이웃간의 관계를 학습하지만 CNN의 대표적인 도메인인 image에서 알수있듯이 vertex들이 모두 정렬되어 있지만, GNN의 경우에는 vertex들이 무질서합니다.
How to apply GNN?
결국 정리해보면 GNN의 핵심 아이디어는 graph상의 node는 연결된(edge) node의 정보를 받아서 message를 업데이트 하고(message passing), 업데이트할때 adjacency Matrix를 활용하여 정보가 propagation됩니다. (adjacency matrix는 learnable matrix가 아닙니다.)
GNN 종류
GCN(graph convolution networks)은 spectral graph theory관점에서의 방법론으로 graph signal processing에서 푸리에 변환등을 통해 스펙트럼 해석이 가능한데 GCN은 이러한 스펙트럼 그래프 이론을 바탕으로 convolution 정의를 제안한 방법입니다.
수식으로는 Hl+1=σ(AHlWl라고 표현할 수 있습니다. (H : l번째에서의 노드 임베딩 행렬, W: 가중치 행렬, A: 정규화된 인접행렬, sigma : activation function)
위를 그림으로 직관적으로 표현한 것입니다.
GAT(Graph Attention Network)은 spatial 방법론 중의 하나입니다. 따라서 Adjacency matrix를 사용하지 않습니다. Attention을 활용하여 노드 간 연결 강도를 학습적으로 조절하는 방법입니다. 기존 GCN이 Adjacency matrix를 활용해 고정된 방식으로 이웃의 정보를 평균하는 것에 비해 GAT는 attention을 가중치로 학습하게 됩니다. 즉, 이웃 노드 간 중요도의 차별화가 가능합니다.
Aggregation & Combine
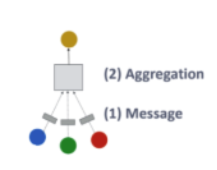
Aggregation, Combine은 GNN에서 message passing이라는 일반적인 틀안에서 두 단계로 구분됩니다.
- Aggregation은 특정 노드의 이웃 노드들로부터 메시지(embedding, feature ..)를 모아 하나의 정보로 aggregation하는 단계로 sum, mean, mlp, attention(GAT) 등을 활용합니다.
- Combine은 aggregation을 현재 노드의 기존 embedding과 combine해서 일종의 embedding을 udpate하는 단계입니다.
예제코드)
import torch
import torch.nn.functional as F
from torch_geometric.nn import GATConv
from torch_geometric.data import Data
class MyGATModel(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, heads=4):
super(MyGATModel, self).__init__()
# 첫 번째 GAT 레이어
self.gat1 = GATConv(in_channels, hidden_channels, heads=heads, concat=True)
# 두 번째 GAT 레이어 (최종 예측 채널 out_channels)
# heads가 4라면, concat=True 시 hidden_channels*4 -> 입력 차원이 됩니다.
self.gat2 = GATConv(hidden_channels * heads, out_channels, heads=1, concat=False)
def forward(self, x, edge_index):
"""
x: 노드 피처 (Tensor) [num_nodes, in_channels]
edge_index: [2, num_edges], 각 열이 (출발노드, 도착노드)를 나타냄
"""
x = self.gat1(x, edge_index) # shape: [num_nodes, hidden_channels * heads]
x = F.elu(x)
x = self.gat2(x, edge_index) # shape: [num_nodes, out_channels]
return x
# ------------------------------------------
# 사용 예시
# ------------------------------------------
if __name__ == "__main__":
# 간단한 예시 그래프 만들기
x = torch.rand((4, 3)) # 4개 노드, in_channels=3
edge_index = torch.tensor([
[0, 1, 1, 2, 2], # source nodes
[1, 0, 2, 1, 3] # target nodes
], dtype=torch.long)
data = Data(x=x, edge_index=edge_index)
model = MyGATModel(in_channels=3, hidden_channels=8, out_channels=2, heads=4)
out = model(data.x, data.edge_index)
print("GAT output:\n", out)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_scatter import scatter_softmax, scatter_add
class CustomGATLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super(CustomGATLayer, self).__init__()
self.W = nn.Linear(in_channels, out_channels, bias=False)
# attention parameter: a^T [Wh_i || Wh_j] => here we implement as a small MLP or a single linear
self.attn = nn.Linear(2 * out_channels, 1, bias=False)
def forward(self, x, edge_index):
"""
x: [N, in_channels]
edge_index: [2, E], 각 col이 (src, dst)
"""
# 1) Node-wise transform W
Wh = self.W(x) # [N, out_channels]
# 2) Edge별 (i->j) attention score 계산
# src = i, dst = j
src_nodes = edge_index[0, :] # [E]
dst_nodes = edge_index[1, :] # [E]
Wh_i = Wh[src_nodes] # [E, out_channels]
Wh_j = Wh[dst_nodes] # [E, out_channels]
# concat(Wh_i, Wh_j) -> [E, 2*out_channels]
Wh_cat = torch.cat([Wh_i, Wh_j], dim=-1)
e_ij = self.attn(Wh_cat).squeeze(-1) # => [E], 각 엣지별 스칼라 score
# 3) scatter_softmax로 edge별 α_ij = softmax_j(e_ij)
# 여기서 softmax는 "dst 노드"를 기준으로 정규화
alpha = scatter_softmax(e_ij, dst_nodes) # shape [E]
# 4) Now aggregate: h'_j = Σ ( alpha_{ij} * Wh_i ) over i in N(j)
out = scatter_add(alpha.unsqueeze(-1) * Wh_i, dst_nodes, dim=0, dim_size=x.size(0))
# 최종 결과 out[j] = ∑_{i in N(j)} alpha_{ij} * Wh_i
# 5) 비선형 활성화
out = F.elu(out)
return out
# ---------------------------------------------------
# 사용 예시
# ---------------------------------------------------
if __name__ == "__main__":
x = torch.rand(5, 4) # 5개 노드, 피처차원=4
edge_index = torch.tensor([[0,0,1,2,2,3],
[1,2,2,3,4,4]], dtype=torch.long)
layer = CustomGATLayer(in_channels=4, out_channels=8)
out = layer(x, edge_index)
print("Custom GAT output:\n", out)
Tracking에 사용하는 GNN
1. GCN
노드로 detection, edge로 노드간의 연결 가능성을 나타냅니다. message passing을 통해 인접노드 (같은 객체일 가능성이 높은 detection)들로부터 정보를 받아서 노드 임베딩을 업데이트합니다.
비교적 간단하고 attention계산이 없기에 가볍습니다.
2. GAT계열
진짜 같은 객체를 추적하는 노드와 헷갈리는 가짜 후보를 attention 메커니즘을 통해 학습할 수 있지만 edge수가 많으면 연산량이 커져 규칙이 어느정도 존재하거나 근거리 연결에는 큰 이점이 없을 수 있습니다.
3. Graph Matching Network - bipartite matching
프레임 t와 t+1에서 검출된 객체들을 bipartite로 연결 후 edge 레벨에서 매칭 스코어를 학습해 최적 매칭을 수행합니다. GCN이나 GAT처럼 message passing을 사용할 수 있지만 Hungarian Algorighm등을 활용해 매칭 최적화와 결합하는 경우가 많습니다.



