안녕하세요. 이번 포스팅은 META에서 발표한 EFM3D라는 논문에 대해 리뷰하겠습니다.
최근 language model, image model은 인터넷의 방대한 data를 활용해서 self-supervised learning을 통해 백본을 학습합니다. 그리고 다양한 downstream task에 활용하는 것이 현재 주류의 approach인데요. 3D의 경우 데이터를 확보하기가 쉽지 않습니다. EFM은 wearable device를 활용해서 egocetric high quality dataset를 수집하고 이를 처리하는 모델을 EFM3D(3D Egocetric Foundation Model이라고 하였습니다.(output으로 mesh또한 제공합니다.) Meta에서 AR classes등에 디바이스(Project Aria)를 개발하면서 당연히 EFM3D같은 모델들을 개발하는 것 또한 어찌보면 당연한 것 같습니다.
Announcing Project Aria: A Research Project on the Future of Wearable AR | Meta
We built a research device that will help us understand how to build the software and hardware necessary for augmented reality glasses.
about.fb.com

기존 데이터셋은 RGB-D 혹은 시뮬레이션에 기반지만 EFM3D의 경우 RGB stream과 gray scale, SLAM을 통해 얻어진 sparse points들을 이용합니다.
기존의 3D object Detector를 살펴보면 ImVoxelNet이 있습니다. indoor 3D detector로 꽤 많이 쓰이고 있는 모델이며, 2D feature를 3D feature volume으로 inverse projection후에 3D CNN을 이용하여 3D bbox를 regression하는 방법입니다. Raytran의 경우 마찬가지로 2D feature를 3D feature로 lifting해서 문제를 푸는데 이과정에서 sparse attention 메커니즘을 사용합니다.
multi-view를 사용하는 DETR3D계열도 있고, Cube RCNN은 mask RCNN 패러다임을 이용해서 direct로 3D OBB를 regression합니다. 논문에는 소개되지 않았지만 DETR3D와 같은 query base의 mono 3D detector인 monoDETR도 존재합니다.
Egocentric Voxel Lifting(EVL)

기본적인 메커니즘은 ImVoxelNet과 같이 2D feature를 3D feature volume으로 lifting해서 문제를 해결하는 방식으로 접근합니다. input image는 frozen 2D foundation model(dino v2)를 통해 feature를 뽑고 이후 CNN & upsampling과정을 통해 input image shape과 동일한 크기의 feature size를 만듭니다. 그리고 sensor(project Aria)에서 나온 gravity-align, pose값을 이용해서 voxel grid를 중력방향으로 정렬시킵니다.
camera pose와 calibration값을 알고있기때문에 3D voxel grid의 중심값을 2D feature map으로 projection할 수 있습니다. (bi-liear interpolation을 이용)
이렇게 하면 각 image에 대해서 T(시간: 개수?)xF(2D feature에 projection해서 nterpolation후에 얻은 feature값)xDxHxW의 3D feature volume이 생성됩니다.
모든 스트림(시간)에서 aggregation된 feature를 mean기반으로 계산한 F와 standard deviation으로 구한 F 를 더해서 최종 2FxDxHxW가 됩니다.
Semi-Dense Point Encoder
project Aria toolkit을 통해 sparse 3D points를 추가로 input으로 사용해서 feature volume에 geometry prior로 쓰입니다. mask를 생성하는데 point를 discretizing하여 point가 voxel에 존재하면 1을 할당합니다. 그 외의 포인트는 0을 할당합니다. (point mask)
freespace mask는 카메라 center와 surface사이의 공간을 나타냅니다. nerf처럼 ray를 쏴서 surface가 도달하기 전까지의 지나온 voxel들을 masking(1)합니다. 이렇게 구한 voxel mask두개를 concat하여 (F+2) x D x H x W를 만듭니다.
여기서 의문은 SLAM에서 나온 sparse point이기 때문에 모든 surface를 point가 커버하지 못할거라는 생각이 듭니다. 아마도 feature volume에 보완적인 encoder이기때문에 가능한 방법이라 생각됩니다.
3D U-Net
앞서구한 Encoder두개를 concat하여 3D U-Net을 통과시킵니다. (x8)
3D bounding box detection
해당 논문에서는 anchor-free head를 설계하였습니다. U-NET을 통과후의 기존의 voxel과 같은 shape을 갖고 이후 3D CNN을 태우고 head를 거칩니다. (output 크기는 voxel과 동일하고 채널은 regression해야하는 수 8만큼 + cls 예측 1)
각각의 voxel마다 center일 확률을 예측합니다. 그리고 7개의 파라미터는 height, width, depth, offset(x,y,z) from center,yaw 를 나타냅니다. 이 후 NMS사용해 postprocessing을 거칩니다.

?그럼 inference할때도 slam돌려서 sparse point도 넣어야하나 -> slam과정 혹은 depth model이 필요할듯 일반 RGB면
? 3DGS도 같이 할 수있음? 그럼 장점일듯, dynamic object처리는?
3D surface Regression
앞서 언급했는데 EFM3D는 Occupancy map도 생성합니다. GT depth map을 이용해서 surface point, free-space point, occupied point로 구별하고 voxel space로 projection해서 supervision을 수행합니다. 아래는 loss function입니다.
FL은 focal loss를 뜻합니다.

Implement Details
논문에서 2D foundation model은 Dino V2.5를 사용하였고 Feature volume은 4m^3의 voxel grid를 선택해서 하나의 voxel사이즈가 6.25cm가 되도록 D,H,W를 64로 설정하는 case와 4cm (D,H,W =96)으로 설정하는 case로 테스트했다고 합니다.
Experiments
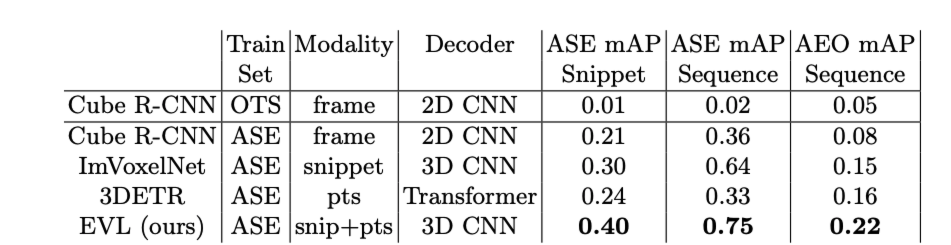
아래는 3D detection에 대한 실험결과 표입니다. 다양한 모델과 벤치마크가 없는게 조금 아쉽습니다. ASE는 시뮬레이션 데이터셋 AEO는 real world의 데이터셋입니다. OTS는 off-the-shelf의 줄임말입니다.

아래는 ablation study로 augmentation을 적용했을때, mean std를 사용할때, pts를 사용유무에 따른 mAP의 변화입니다.

다음으로는 surface rendering에 관련 실험결과입니다.


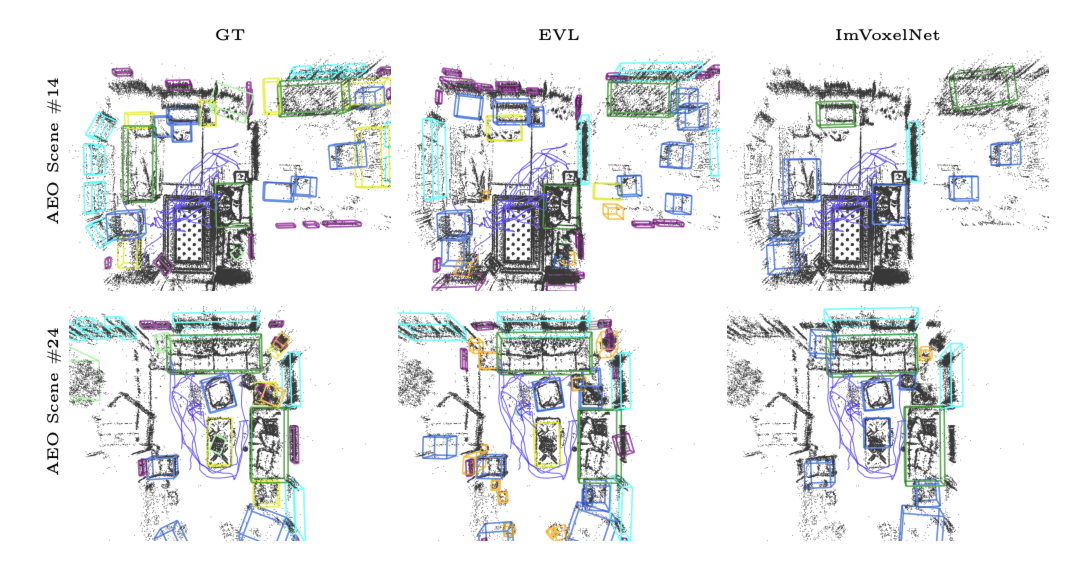
failure case

appendix에서 3GS로 렌더링을 실험한 내용도 나와있어 흥미롭습니다. nerf studio의 3GS모델을 사용했고 pose를 알고있으니 3DGS을 사용하는데 무리가없지만 아래 그림처럼 사용자가 움직이는 부분에서는 redering퀄리티가 매우 낮게 나왔다고 합니다.

본 논문은 몇가지의 한계점을 이야기하는데 우선 static world에 한정되어 설계되었다는 점 입니다. 그리고 4m^3의 voxel size는 다소 작은 voxel grid입니다.
사실 논문이 실용적인 모델이라고 볼 수는 없을 것 같습니다만 meta의 ar device와 같이 시너지를 낼 수 있는 모델이라고 생각됩니다.



