안녕하세요. 이번에 포스팅할 논문은 Lion이라는 lidar detection model입니다.
Intro
Lidar detection 모델은 크게 point base방법과 voxel base방법으로 나눠져 발전했습니다.(pvrcnn과 같은 두가지의 방식을 혼합한 방법도 있습니다만)
최근 트렌드는 voxel base 방법의 모델이라고 여겨집니다. pointcloud를 voxelization하고 이 sparse voxel grid를 효율적으로 computation 하기 위해 spconv와 같은 sparse convolution을 사용합니다. 헌데 이 operator는 custom cuda kernel를 사용하기에 onnx, trt로 변환하기가 매우 까다롭죠.
이런 이유와 언어모델들에서의 transformer의 성능을 보고 transformer를 이용한 논문들도 나왔습니다.
대표적으로 DSVT가 그것입니다.
[paper review] DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets 논문리뷰
안녕하세요. 이번 포스팅은 lidar 3D detection model중 하나로 Transformer를 활용한 DSVT라는 논문입니다. 논문에서 가장 내세우는 것 중에 하나는 기존의 많은 lidar model들이 sparse conv를 처리하기 위해 cust
jaehoon-daddy.tistory.com
3D 백본으로 transformer를 이용하고 이후의 과정은 이전의 voxel base의 모델들과 같이 BEV와 head를 거쳐 3D cuboid를 prediction합니다.
DSVT에서도 문제가 있습니다. transformer는 기본적으로 quadratic computation cost(transformer는 quatratic bottle neck으로 유명함)를 가지고 있기에 아래 dsvt overview를 보면 x-axis, y-axis를 기반으로 sort해서 group을 만들고 그룹내에서 self-attention을 수행합니다.


문제는 여기서 발생하는데 indoor가 아닌 outdoor의 경우 long-range context 에 대한 이해가 필요합니다. 그렇지 않으면 벽면을 차 벽면으로 오인하는 경우가 많이 발생하겠죠. 하지만 단순계산해봐도 모든 voxel을 self-attention을 수행할수는 없습니다. 이를 위해서 Linear RNN을 이용합니다.
Method

*Linear RNN의 대표 아키텍쳐는 Mamba로 non-linear의 Rnn activation function대신 linear operator를 사용하여 computation cost를 획기적으로 줄임
자세한 이야기는 아래 포스팅 추천합니다.
[논문리뷰] - ⭐️Mamba: Linear-Time Sequence Modeling with Selective State Spaces⭐️ - 맘바 ! Transformer의 대체
1. Interesting Point"We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addr
minyoungxi.tistory.com
method는 위에서 언급했던 3D 백본에 대한 이야기입니다.
LION Layer를 먼저 봅시다. 아래는 DSVT의 overview인데 DSVT block과 매우 흡사합니다. 차이는 self-attention(트랜스포머의 일부분)대신 위에서 언급했던 Linear RNN을 수행하고 Group의 크기를 훨씬 크게 사용하여 long-range의 context또한 interaction할 수 있습니다.
3D spatial Feature Descriptor
Linear RNN은 computation cost가 적지만 매우 큰 group크기를 가지고 있기에 아래 그림과 같이 1,4는 매우 인접하지만 x-axis 정렬했을떄 매우 거리가 멀어질 수 있습니다. 이를 해결하기위해 3D conv + layer norm + gelu를 사용하여 locality를 반영할 수 있도록 합니다.
아마 spconv와 같은 submanifold convolution을 사용했을텐데 custom cuda를 사용해서 trt변환이 어려울 수 있을 것 같습니다.

voxel merging and voxel expanding
multi scale에 강건할 수 있도록 마치 residual block과 같은 작업을 진행합니다. 이 과정에서 index mapping을 사용해서 down sampling, up sampling을 수행합니다.
Voxel Generation

voxel generation은 sparse dataset에서 필요한 위치에 충분한 데이터가 없으면 예를 들면 자동차의 모양이나 위치를 정확하게 파악하기 어렵기때문에 새로운 voxel을 생성하여 밀도를 높이는 역할을 합니다. 보통 foreground일 확률이 높은 voxel을 찾는 식으로 진행합니다. (일종의 augmentation)
본 논문에서는 이를 위해 GT를 사용하지 않고 linear RNN의 auto-regressive를 사용합니다.
3D backbone에서 채널별로 feature값을 계산하고 (아래equation) 이후 feature를 내림차순으로 sort하여 non-empty중에서 상위 m개를 foreground로 선택합니다.

이렇게 voxel이 선택되면 네방향으로 확산시켜 확산된 voxel생성하고 0으로 초기화 시켜 다시 다음 LION Block을 같이 채우게 됩니다.그럼 output voxel을 더 많은 feature 정보를 갖게 됩니다.
(네개의 방향중에 non-empty라면 어떻게 처리하는지에 대한 내용은 없지만 무시하지 않을까합니다.)
이를 수식으로 나타내면 아래와 같습니다.
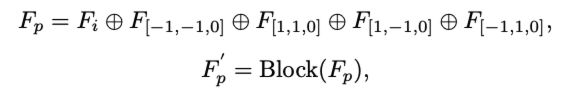
Experiments
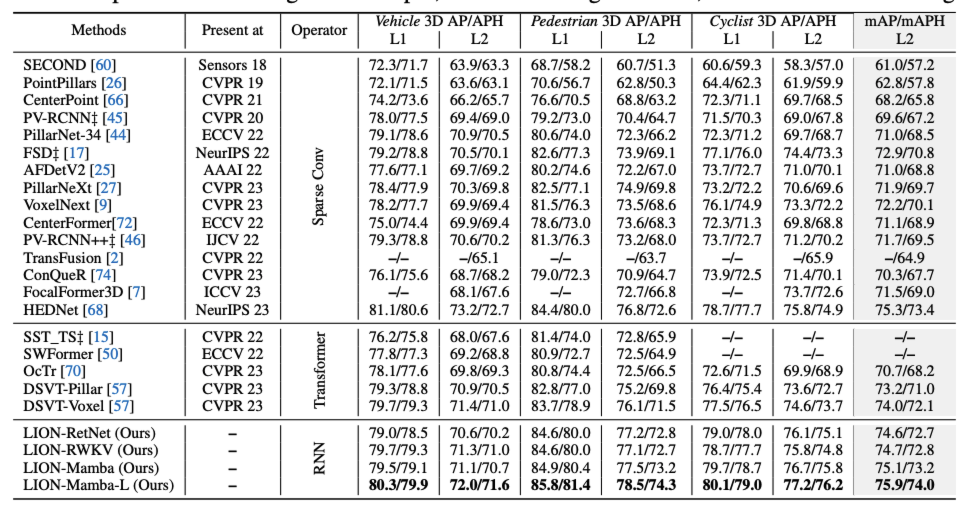
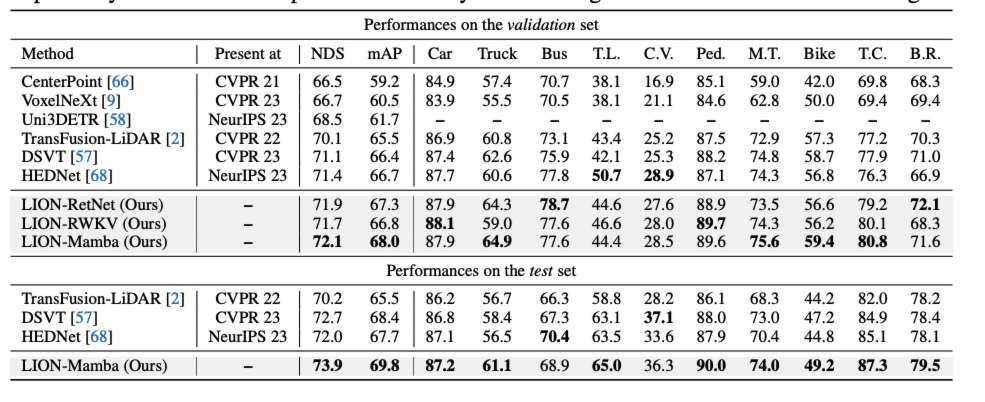
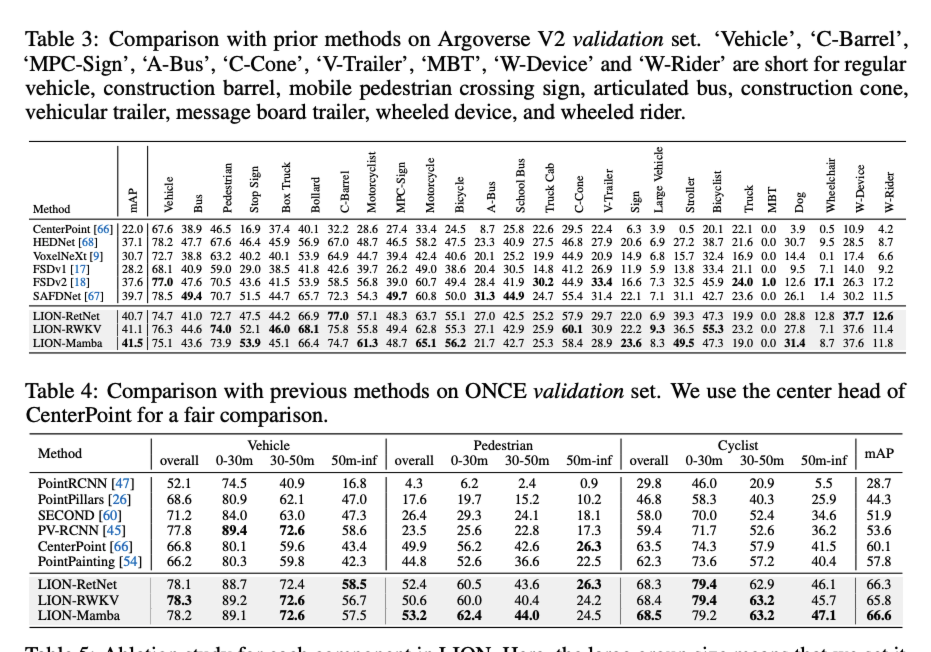
논문은 거의 모든 large lidar benchmark에서 sota의 성능을 찍습니다.
엄청난 성능을 자랑하는 LION모델의 리뷰를 마칩니다.




