안녕하세요. 이번 포스트는 lidar segmentation에서 높은 성능을 보이고 있는 Point Transformer관련 논문리뷰 진행하겠습니다.
간략하게 trasnformer관련 task들을 살펴보면 image 도메인에서는 ViT가 대표적입니다. 문제는 ViT는 이미지 전체에 대해 global attention을 수행하기에 메모리를 많이 잡아먹는 단점이 있어 Swin-Transformer에서 이를 해결하기 위해 grid base의 local attention을 수행하여 이를 해결합니다.
Pointcloud도메인에서는 크게 prjection, voxel, point 방법들이 있는데 projection방법은 다양한 방법으로 image plane으로 projection한 후에 2D CNN기반의 model을 사용합니다. voxel 방법은 voxelization을 하여 sparse 3D conv등을 이용한 model을 사용하고 point 기반 approach는 직접적으로 point마다 다양한 방법을 이용해서 feature를 추출합니다. 해당논문의 방법이 여기에 속합니다.
Preknowledge
PTv2는 기존의 PTv1에서 attention은 수행할때 weight vector를 활용하는데, 모델이 더 깊어질수록 overfit되는 경향이 있기에 이를 해결하기 위해 grouped vector attention, 개선된 position encoding scheme, partition based pooling 전략을 제안합니다.
기존의 local attention을 보면 shift-grid방법이 있는데 non-overlap으로 window를 정해서 local attention을 수행하는 방법으로 image에서 보통 사용하는 방법입니다. 저자는 3D point는 consistency가 image와 같이 균일하지 않기에 해당방법으로는 효과가 없다고 말합니다. PTv1에서는 이 부분을 해결하기 위해서 KNN을 활용합니다.
scalar attention vs vector attention


scalar attention은 attention wieght가 단일 값으로 계산되어 채널별 차이를 고려하지 못하지만 vector attention은 채널별로 차원을 고려할 수 있습니다.
아래는 scalar attention, vector attention의 코드에시입니다.
# Redefine data due to execution timeout clearing variables
import numpy as np
# Initialize data
q_i = np.array([1, 1, 1]) # Query vector
k_j = [np.array([2, 2, 2]), np.array([3, 3, 3])] # Key vectors for neighbors
v_j = [np.array([0.5, 1.0, 1.5]), np.array([1.0, 0.5, 0.2])] # Value vectors for neighbors
C_h = 3 # Number of channels
# Scalar Attention Calculation
scalar_weights = [np.dot(q_i, k) / np.sqrt(C_h) for k in k_j] # Dot product with scaling
scalar_softmax = np.exp(scalar_weights) / np.sum(np.exp(scalar_weights)) # Softmax normalization
scalar_attention_output = np.sum([softmax * v for softmax, v in zip(scalar_softmax, v_j)], axis=0)
# Vector Attention Calculation
vector_weights = [q_i * k for k in k_j] # Element-wise multiplication (simplified)
vector_softmax = [np.exp(w) / np.sum(np.exp(w), axis=0) for w in vector_weights] # Softmax normalization per channel
vector_attention_output = np.sum([softmax * v for softmax, v in zip(vector_softmax, v_j)], axis=0)
# Results
scalar_attention_output, vector_attention_output
PointTransformer V2

Grouped Vector Attention
vector attention은 모델의 layer가 커질수록 계산량과 params양이 급격히 증가하여 overfit문제가 발생할 수 있습니다. 이를 위해 본 논문에서 제안한 것이 GVA입니다. 채널을 그룹으로 나누고 그룹단위로는 scalar attention을 공유하도록 하여 계산량을 줄입니다.

Positional Encoding Multiplier

pointcloud는 irregular한 특징때문에 2D image와 같은 position encoding방법을 사용할 수 없습니다. v1에서는 point간의 차이를 이용한 bias기반의 encoding사용했는데 v2에서는 위의 수식과 같이 mlp기반의 곱셉 encoding함수를 사용하였습니다. 직관적으로 이해해보면 point들의 위치간의 관계에 weight를 부여하겠다 정도로 해석할 수 있겠습니다.
Pooling
pooling방법으로 기존에 사용하던 sampling기반 방법식에서 grid기반의 방법을 사용합니다. sampling방법은 query point를 선택한 후에 FPS와 같은 방법을 사용해서 pooling을 수행합니다. 해당 방법은 sampling된 점들의 정보 밀도와 위치가 불규칙하기에 공간적인 정보를 담기 힘듭니다. 논문에서 제안한 방법은 partition-based pooling으로 non-overlapping partition으로 공간을 나누고 파티션 내에서 정보를 요약하여 하나의 representation으로 변환합니다. (MLP사용)
unpooling방법은 interpolation을 사용하는 대신 pooling단계에서 파티션 정보를 기록하고 unpooling시에 해당 파시션의 representation을 복사하는 식으로 진행합니다.
Network
network아키텍쳐는 전체적으로 U-Net의 구조를 기반으로 하였습니다. 총 4개의 stage로 이뤄져있으며 위에서 설명한 attention과 pooling, unpooling을 사용하여 Encoder-Decoder의 구조를 사용합니다.
PTv3

PTv3버전에서는 v2에서 partition으로 나누는 방법에서 pointcloud serialization의 방법을 사용합니다. 위의 그림처럼 serialization pattern을 활용하여 point들을 구조화시켜 메모리 효율성을 높이고 포인트간의 relation도 더 효율적이고 넓은 receptive field도 갖게 됩니다.
serialization 단계를 아래 에시코드로 설명해보겠습니다.
우선 포인트와 그리드 크기를 input으로 받으면 각 포인트를 그리드 크기로 정규화하고 space-filling curve로 z-order encoding를 사용합니다.
각 좌표를 이진수로 변한 후 z-order순서로 interleave합니다. 이 후에 z-order 코드로 정렬을 수행합니다.

import numpy as np
# 포인트 클라우드 데이터
points = [(1.2, 3.4, 5.6), (7.8, 9.1, 2.3), (4.5, 6.7, 8.9)]
grid_size = 2.0 # 그리드 크기
# Z-order를 이용한 간단한 공간 충전 곡선
def z_order_encode(x, y, z):
"""
각 좌표를 이진수로 변환 후 Z-order 순서로 interleave.
"""
x_bits = f'{int(x):016b}' # x를 16비트 이진수로 변환
y_bits = f'{int(y):016b}' # y를 16비트 이진수로 변환
z_bits = f'{int(z):016b}' # z를 16비트 이진수로 변환
# Z-order 순서로 interleave
z_order = ''.join(b for triplet in zip(x_bits, y_bits, z_bits) for b in triplet)
return int(z_order, 2) # Z-order 코드를 정수로 반환
# 직렬화 코드 생성
def serialize_points(points, grid_size):
serialized = []
for point in points:
# 각 포인트를 그리드 크기로 정규화
normalized = tuple(int(coord / grid_size) for coord in point)
# Z-order 직렬화 코드 생성
z_code = z_order_encode(*normalized)
serialized.append((point, z_code))
return serialized
# 포인트 정렬
def sort_points_by_serialization(serialized):
return sorted(serialized, key=lambda x: x[1]) # Z-order 코드로 정렬
# 실행
serialized_points = serialize_points(points, grid_size)
sorted_points = sort_points_by_serialization(serialized_points)
# 결과 출력
print("Original Points with Serialization Codes:")
for point, z_code in serialized_points:
print(f"Point: {point}, Z-order Code: {z_code}")
print("\nSorted Points:")
for point, _ in sorted_points:
print(f"Point: {point}")
#z-order code
Point: (1.2, 3.4, 5.6), Z-order Code: 18133887232
Point: (7.8, 9.1, 2.3), Z-order Code: 51235346484
Point: (4.5, 6.7, 8.9), Z-order Code: 33245363542
#sorted points
Point: (1.2, 3.4, 5.6)
Point: (4.5, 6.7, 8.9)
Point: (7.8, 9.1, 2.3)
Serialized Attention
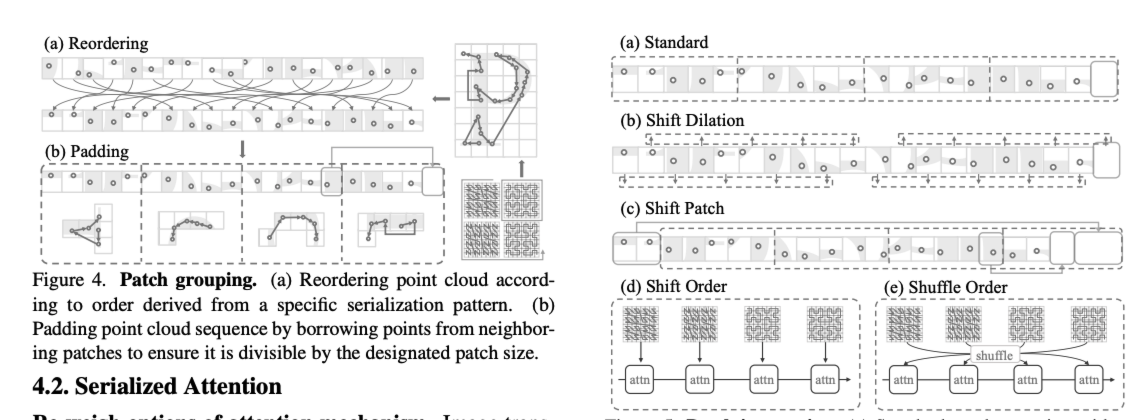
serialization을 통해 포인트들을 reorder하고 patch화 시킵니다. patch크기는 동일해야하기때문에 부족한 부분은 padding을 통해 해결합니다.
이 후에는 patch interaction을 거치는데 서로 다른 패치간의 정보를 결합해서 global attention의 효과를 가집니다. interaction방법으로는 shift dilation, shift patch, shift order, shuffle order 위의 그림과 같은 방법을 사용합니다.
이 과정을 통해 KNN의 방법들보다 더 넓은 receptive filed를 갖게되어 generalization 성능을 향상시킬수있습니다.
Positional Encoding
v3에서는 coditional positional encoding을 확장한 xCPE를 제안합니다. 기존의 v2에서는 point간의 euclidean distance를 계산해야했습니다.
CPE는 기본적으로 octree기반의 구조를 활용합니다. octree depth 레벨별로 sparse conv를 돌려 feature를 뽑는다고 생각하시면 됩니다. xCPE는 거기에 skip connection을 연결해 성능을 극대화 합니다.
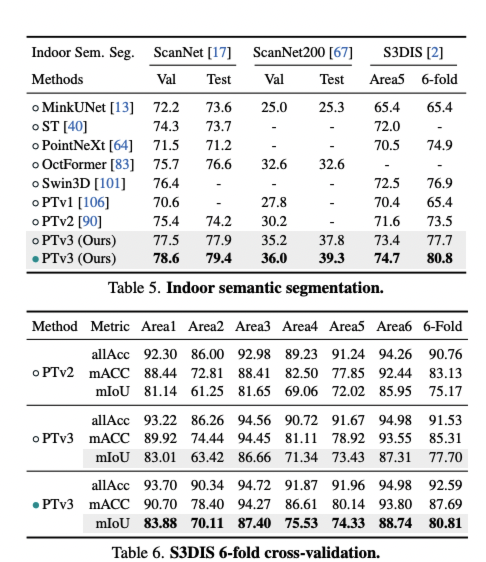
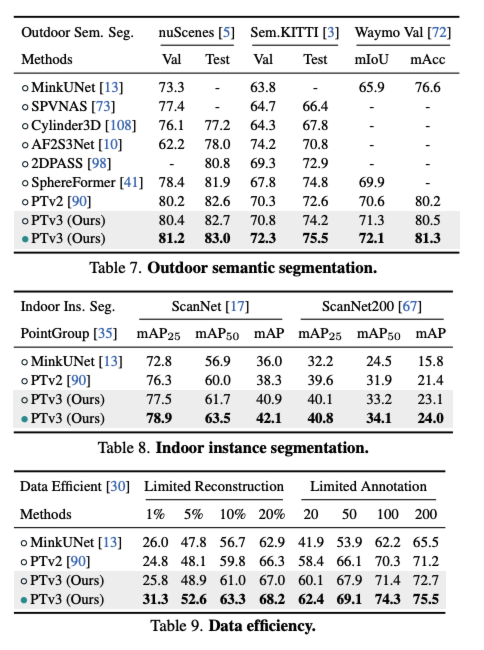
Experiments
indoor, outdoor에서 sota의 성능을 보여줍니다.