이번 포스팅은 panoptic nerf로 3D-2D label transfer관련 논문입니다. 저자분은 KITTI360데이터셋을 구축한 분들 중에 한분으로 현재 고국에서 교수님 생활을 하시면서 후속작을 내신거로 보입니다.
Intro
저자분의 경험치에서 나온거겠지만 보통 3D에서 separate instance를 라벨링하는게 2D에서 보다 쉽다고 합니다. sparse하기 때문에 instance가 어느정도 떨어져 있기 때문이겠죠. 그렇기 때문에 3D에서 labeling 정보를 2D(Image)로 transfer하는 것이 합리적이라고 주장합니다. 저자분이 KITTI360을 구축했을때는 이를 위해 CRF라는 method를 사용하여 이를 해결하였는데 최근 NeRF가 각광을 받으면서 이 NeRF를 통해 3D label정보를 2D로 trasnfer하여 panoptic segmentation을 수행하는 것을 목적으로 합니다.
이를 위해서 3D annotation정보, 2D semantic segmentation pridiction (noise-즉 pretrained)가 필요하다고 합니다.
Methodology

우선 NeRF와 마찬가지로 image 에서 ray를 쏴 points를 샘플링합니다. 이후에 radiance field라고 되어있는 mlp를 통과하여 density와 color값을 도출해 냅니다.
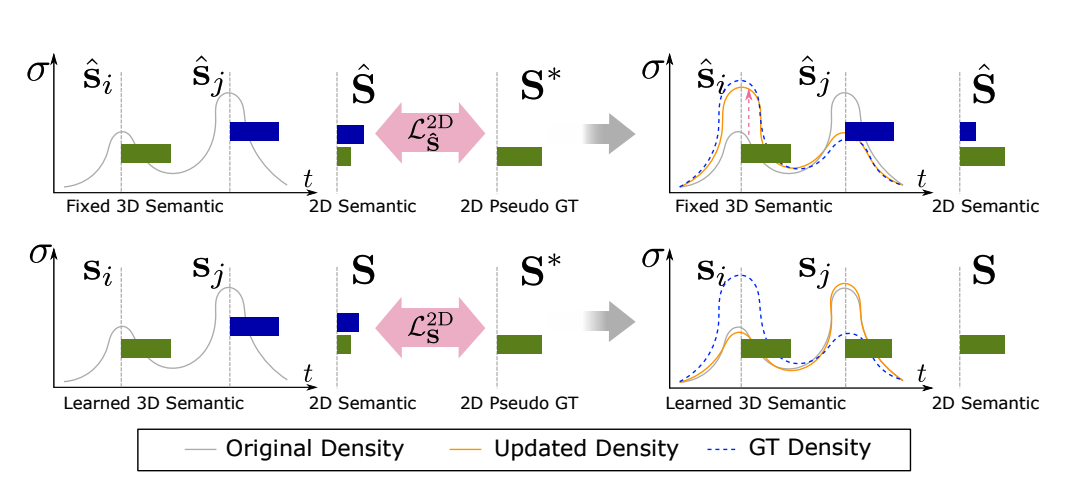
fixed semantic field에서는 sampling한 point를 3d annotation한 영역(fixed) 어느 부분에 매칭이 되는지 categorical 한 one-hot vector로 값이 나오게 됩니다. 이렇게 나온 vector에 앞서 radiance field를 통해 나온 density와 NeRF의 volumn rendering 공식을 이용하여 아래와 같은 수식을 통해 해당 픽셀의 semantic pixel값을 도출합니다. 아래 수식에 s hat부분이 기존의 mlp에서 나온 color값이 들어가는 부분입니다.
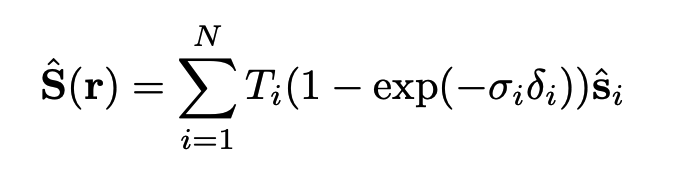
아래의 learned semantic field부분은 Radiance Filed를 한번더 learned semantic field(mlp)를 태웁니다. direction은 input으로 들어가지 않는데, direction과 상관없이 해당 pixel의 semantic값은 일정해야하기 때문입니다. learned semantic field는 최종 softmax를 통해 해당 픽셀의 categorical probability를 나타내고 이 값과 NeRF의 volumn rendering을 통해 아래와 같은 수식을 얻어 learning을 통해 semantic pixel값을 도출합니다.
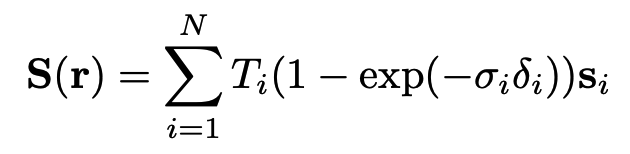
Loss
fixed semantic field의 loss는 아래와 같습니다. 각 ray에 대해서 cross-entropy를 수행하는 것과 비슷한데, GT자리에 있는 $S^{*}$는 noise 2D semantic prediction으로 다른 dataset으로 얻어진 semantic segmentation prediction입니다.
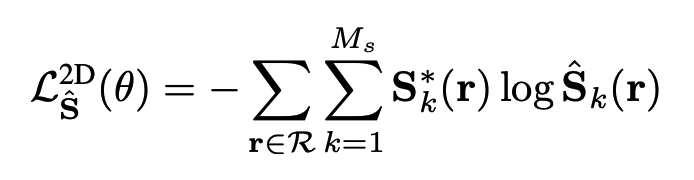
이 과정을 통해 아래와 같이 depth를 합리적으로 추정할 수 있다고 합니다.
다음으로 learned semantic field에서 얻은 값으로는 아래와 같은 loss를 사용합니다.
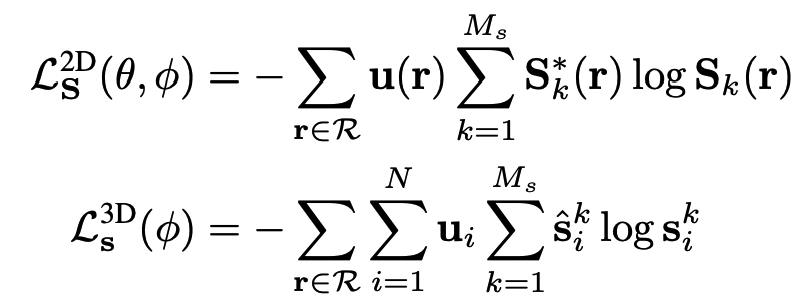
2D loss는 위의 fixed semantic loss와 비슷하지만 $u(r)$부분이 추가 되었는데 pseudo label과 prediction(softmax를 통해 나온값)과 매칭되는 point가 있으면 1이고 ray에 매칭되는 point들이 하나도 없으면 0이 됩니다. 3D loss는 2D prediction의 noise를 suppress하는 역할을 한다고 하는데 point는각각마다 loss를 계산하게 됩니다.
하여 최종loss는 아래와 같은데 $L_{p}$는 기본적인 NeRF loss인 L2를 뜻하고 $L_{d}$는 depth를 추가했는데 kitti360은 stereo라서 pseudo depth값을 stereo를 이용해서 구할 수 있습니다. 중요하지 않아서 해당 부분은 생략하였습니다.
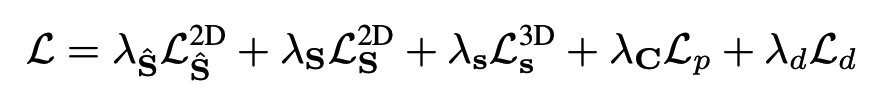
실제 inference를 할때는 learned semantic 부분을 이용하여 semantic or panoptic label을 inference합니다.
Experiment
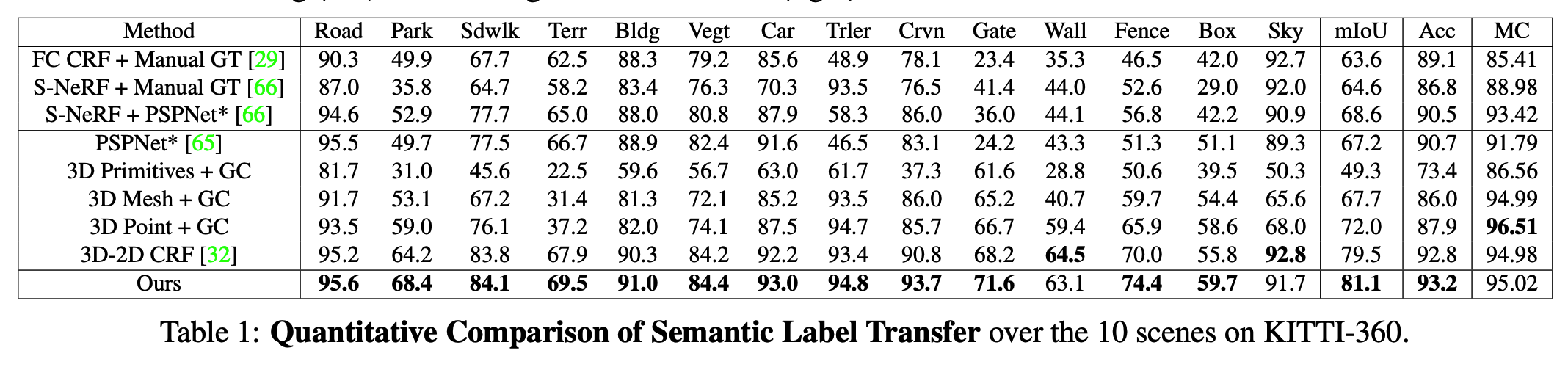
사실 실험결과를 보고 처음에 생각했던 labeling과정에 효율적일거라고 생각했던 부분이 약간 희석이 되었는데요. 위의 3model은 2D-2D transfer이고 아래는 3D-2D transfer 모델들 입니다. 여기서 PSPNet은 pseudo label을 구하기 위한 모델인데요. 다른 데이터셋으로 pretrained된 모델에 KITTI-360으로 finetune한 모델이라고 합니다. 여기서 약간 띠용하였는데요. KITTI-360으로 fine-tune했다는 건 2D GT label이 필요하다는 말이고 이는 곧 label transfer를 하는 이유가 많이 희석되기 때문입니다. 어떻게 보면 약간의 2D GT label로 fine-tune한 모델보다 성능이 좋다라는 일종은 domain adaptation model같아 보이기도 합니다.

물론 위의 ablation study에서 모델을 어떻게 사용하느냐에 따라 fine-tune을 안해도 된다고 하는데, pretrained model에 labeling하려는 class가 없다면 이 또한 적용하기 쉽지 않겠습니다.




