안녕하세요. 이번 포스팅은 lidar 3D detection model중 하나로 Transformer를 활용한 DSVT라는 논문입니다.
논문에서 가장 내세우는 것 중에 하나는 기존의 많은 lidar model들이 sparse conv를 처리하기 위해 custom cuda kernel (spconv등)을 사용하여 model deployment에 상당한 제약이 있었는데, DSVT는 standard transformer로 이루어져있어서 배포에 상당히 용이하다는 점입니다.
Transformer에 대한 대략적인 이해는 아래의 포스팅 참고하세요.
[Transformer] Transformer & Vision
안녕하세요. 이번 ML관련 포스팅에서는 Transformer관련하여 포스팅하겠습니다. 이미 나온지 꽤 오래되었고 많은 분야에서 활용되고 있는 아키텍쳐인데요. NLP분야에서 일찍이 탄생했지만 비전 및
jaehoon-daddy.tistory.com
Introduction
기존의 pointcloud model들을 볼 때 가장 처리하기 애매한 것 중 하나가 empty-voxel입니다. 즉, sparse한 voxel에 어떻게 3D convolution을 적용할지에 따라 spconv 등등의 custom cuda kernel이 나왔고 이 때문에 onnx등으로 배포시 상당한 어려움이 있습니다. 해당 논문에서도 이런 sparse한 특징을 transformer 백본으로 처리하는 방법론이 가장 어려운 부분이였다고 합니다.
그 방법론은 dynamic sparse window attention과 novel learnable 3D pooling operation인데 이 부분은 아래에서 다루도록 하겠습니다.

위의 표를 보면 앞서 설명했다시피 onnx로 변환하고 tensorRT로 변환이 쉽기 때문에 배포시 매우 빠른 inference time을 갖는 장점이 있습니다.
Dynamic Sparse Window Attention
이미지 모델에서 swin transformer이 높은 성능을 만들었기에 swin transformer의 핵심아이디어인 window-based mehodology를 사용하려했지만 sparse한 voxel을 어떻게 처리해야하는지가 문제였다고 합니다. 이를 해결하기 위한 방법이 Dynamic Sparse Window Attention입니다.

우선 dynamic하게 partition을 지정합니다. 좀 더 구체적으로는 위의 overview를 보면 이해가 쉽습니다. 그림에서 흐름대로 설명해보면 VFE를 거쳐서 나온 feature들을 token이라고 하는데 voxel마다 이 token값이 없는 sparse voxel이 많다는 것 문제인데, 우선 주어진 window내부에서 X axis방향으로 순서대로 non-empty한 token을 n개 만큼 동일하게 concat합니다. 즉 빨간색, 노란색, 초록색.. token이 n개 만큼 각각 concat 되어 self-attention branch를 거치게 됩니다. self-attention을 거쳐 나온 feature는 (attention의 in/out feature shape은 같습니다.) 마찬가지로 다시 Y axis방향으로 순서대로 non-emtpy한 token을 n개 만큼 동일하게 concat후에 다시 self-attention을 거치게 됩니다.

이렇게 하면 제일 마지막의 set은 token이 n개가 안될수 있습니다. 따라서 마지막 set은 위의 공식처럼 n* 개의 token과 masked token으로 이뤄지게 됩니다.

위에서 설명한 내용의 하나의 Block이고 window를 다르게 하여 또 한번의 Block을 거치고 이를 위의 flow-chart처럼 총 N번 반복하게 됩니다.

지금까지 설명한 내용을 수식으로 표현한 것 입니다. $D_{x}$, $D_{y}$는 widow내부의 voxel-feature를 x axis, y axis방향으로의 sort를 의미합니다. MHSA는 multi-head self-attention을 뜻하고, PE는 positional encoding을 의미합니다. F는 sorted voxel의 feature들을 뜻하고 O는 F와 correspoding voxel coodinate, 그러니깐 (x,y,z) 들을 뜻합니다.
그리고 Hybrid window aprtition을 사용한다고 나와있는데 swin-transformer에서 사용한 것 처럼 두 번의 연속적인 block에서 window size를 변경하여 재정의하는 것을 뜻합니다.
class DSVTBlock(nn.Module):
''' Consist of two encoder layer, shift and shift back.
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", batch_first=True):
super().__init__()
encoder_1 = DSVT_EncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, batch_first)
encoder_2 = DSVT_EncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, batch_first)
self.encoder_list = nn.ModuleList([encoder_1, encoder_2])
def forward(
self,
src,
set_voxel_inds_list,
set_voxel_masks_list,
pos_embed_list,
block_id,
):
num_shifts = 2
output = src
# TODO: bug to be fixed, mismatch of pos_embed
for i in range(num_shifts):
set_id = i
shift_id = block_id % 2
pos_embed_id = i
set_voxel_inds = set_voxel_inds_list[shift_id][set_id]
set_voxel_masks = set_voxel_masks_list[shift_id][set_id]
pos_embed = pos_embed_list[pos_embed_id]
layer = self.encoder_list[i]
output = layer(output, set_voxel_inds, set_voxel_masks, pos_embed)
return output
class DSVTBlock(nn.Module):
''' Consist of two encoder layer, shift and shift back.
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", batch_first=True):
super().__init__()
encoder_1 = DSVT_EncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, batch_first)
encoder_2 = DSVT_EncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, batch_first)
self.encoder_list = nn.ModuleList([encoder_1, encoder_2])
def forward(
self,
src,
set_voxel_inds_list,
set_voxel_masks_list,
pos_embed_list,
block_id,
):
num_shifts = 2
output = src
# TODO: bug to be fixed, mismatch of pos_embed
for i in range(num_shifts):
set_id = i
shift_id = block_id % 2
pos_embed_id = i
set_voxel_inds = set_voxel_inds_list[shift_id][set_id]
set_voxel_masks = set_voxel_masks_list[shift_id][set_id]
pos_embed = pos_embed_list[pos_embed_id]
layer = self.encoder_list[i]
output = layer(output, set_voxel_inds, set_voxel_masks, pos_embed)
return output
class DSVT_EncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", batch_first=True, mlp_dropout=0):
super().__init__()
self.win_attn = SetAttention(d_model, nhead, dropout, dim_feedforward, activation, batch_first, mlp_dropout)
self.norm = nn.LayerNorm(d_model)
self.d_model = d_model
def forward(self,src,set_voxel_inds,set_voxel_masks,pos=None):
identity = src
src = self.win_attn(src, pos, set_voxel_masks, set_voxel_inds)
src = src + identity
src = self.norm(src)
return src
class SetAttention(nn.Module):
def __init__(self, d_model, nhead, dropout, dim_feedforward=2048, activation="relu", batch_first=True, mlp_dropout=0):
super().__init__()
self.nhead = nhead
if batch_first:
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
else:
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(mlp_dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.d_model = d_model
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Identity()
self.dropout2 = nn.Identity()
self.activation = _get_activation_fn(activation)
def forward(self, src, pos=None, key_padding_mask=None, voxel_inds=None):
'''
Args:
src (Tensor[float]): Voxel features with shape (N, C), where N is the number of voxels.
pos (Tensor[float]): Position embedding vectors with shape (N, C).
key_padding_mask (Tensor[bool]): Mask for redundant voxels within set. Shape of (set_num, set_size).
voxel_inds (Tensor[int]): Voxel indexs for each set. Shape of (set_num, set_size).
Returns:
src (Tensor[float]): Voxel features.
'''
set_features = src[voxel_inds]
if pos is not None:
set_pos = pos[voxel_inds]
else:
set_pos = None
if pos is not None:
query = set_features + set_pos
key = set_features + set_pos
value = set_features
if key_padding_mask is not None:
src2 = self.self_attn(query, key, value, key_padding_mask)[0]
else:
src2 = self.self_attn(query, key, value)[0]
# map voxel featurs from set space to voxel space: (set_num, set_size, C) --> (N, C)
flatten_inds = voxel_inds.reshape(-1)
unique_flatten_inds, inverse = torch.unique(flatten_inds, return_inverse=True)
perm = torch.arange(inverse.size(0), dtype=inverse.dtype, device=inverse.device)
inverse, perm = inverse.flip([0]), perm.flip([0])
perm = inverse.new_empty(unique_flatten_inds.size(0)).scatter_(0, inverse, perm)
src2 = src2.reshape(-1, self.d_model)[perm]
# FFN layer
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return srcAttention-style 3D Pooling
기존의 방식대로 sparse region에 zero-padding후에 mlp를 거쳐 downsampling할 경우 performance의 저하 발생이 있어서 논문에서는 attention-style의 3D pooling operation을 제안합니다.

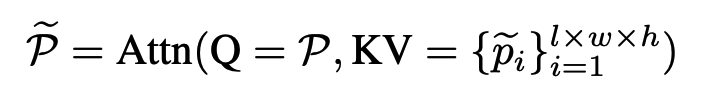
pooling할 local region을 lxwxh으로 pooling할 때 우선 기존의 max pooling처럼 가장 큰 feature를 뽑습니다. 이렇게 뽑은 max feature는 attention 메커니즘의 query vector로 활용되고 원래의 unpooled vector는 key, value vector로 활용하여 attention 메커니즘을 만들고 이를 pooling에 활용합니다.
Experiment
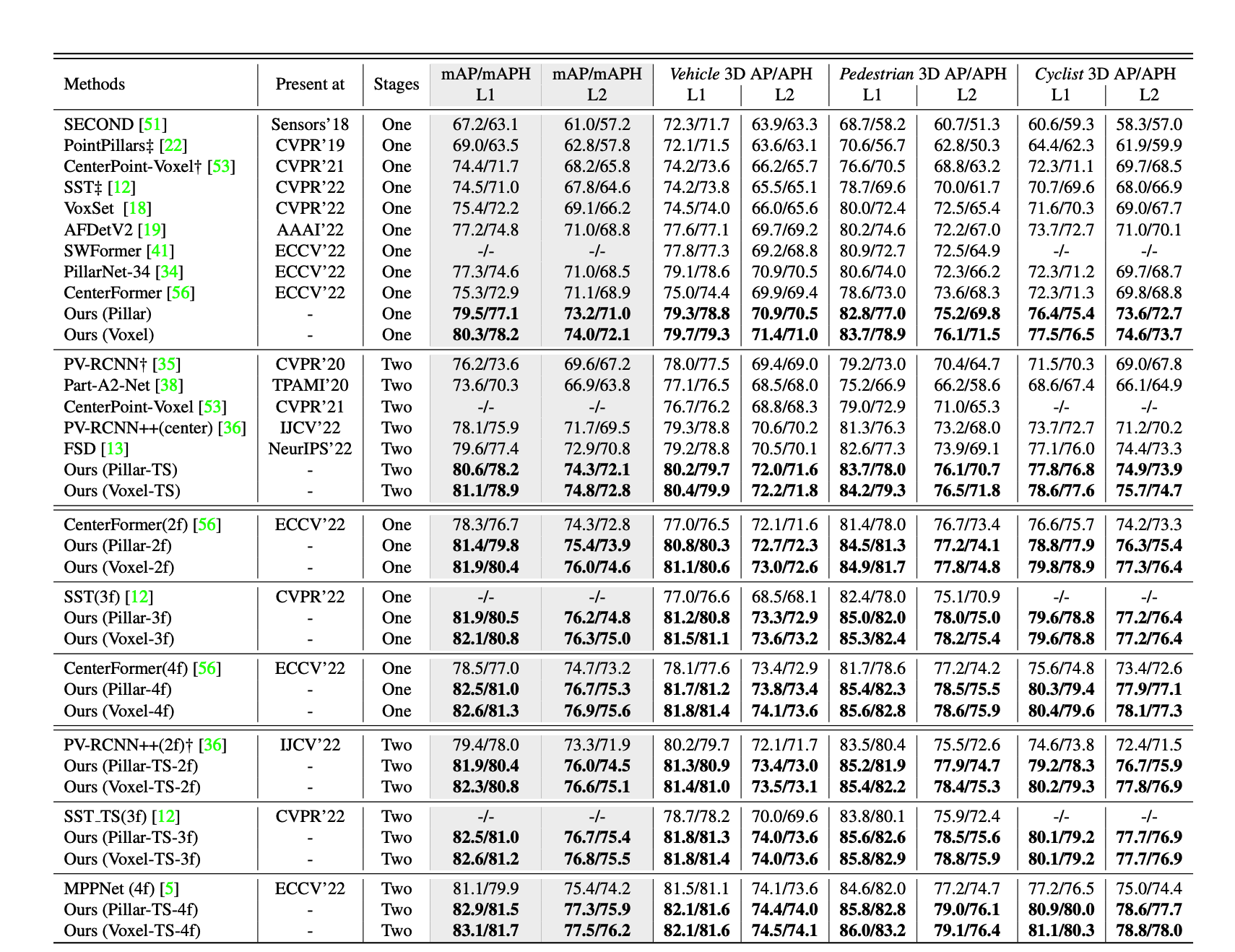
위의 표는 waymo dataset으로 실험한 결과입니다. 근래에 본 lidar detection model중에 가장 디테일한 실험에 좋은 성능을 나타냅니다.
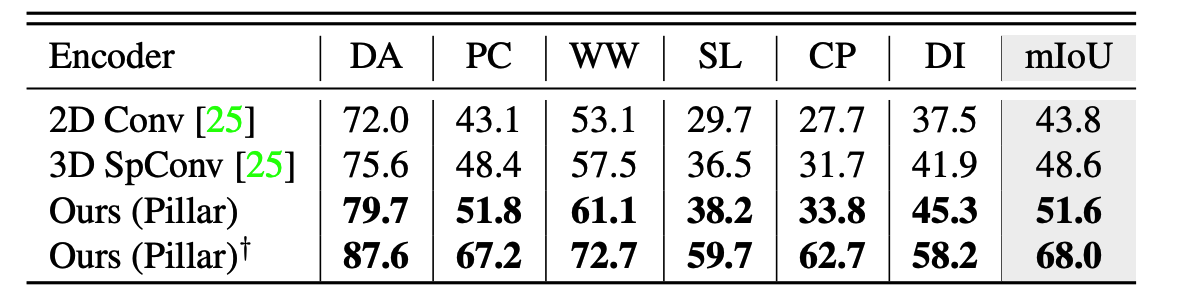
위의 표는 nuscens데이터로 segmentation결과인데 BEVfusion에 lidar branch의 backbone부분만 변경하여 Sota를 달성하였다고합니다.
[paper review] BEVFusion 논문 리뷰
이번 논문리뷰는 BEVFusion이라는 논문으로 3D Detection에서 multi-modal 그 중에서도 camera-lidar에 관련된 논문입니다. ICRA 23에 publish되고 현재기준으로 multi model 3D detection쪽에서 opensource중에서는 최고성
jaehoon-daddy.tistory.com
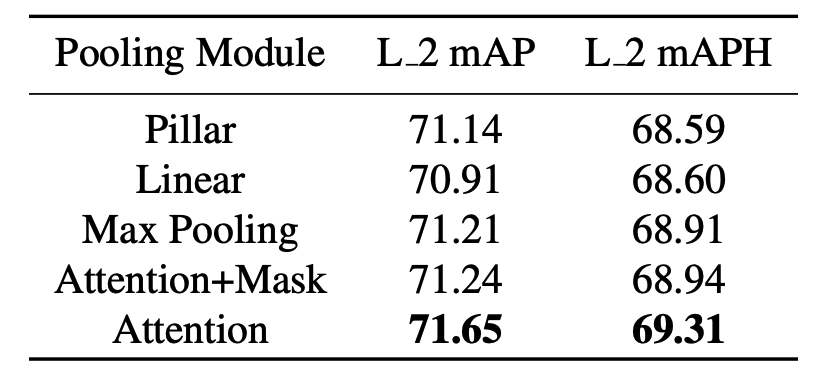
마지막으로 위의 ablation study결과와 inference time에 대해 tensorRT사용시 10~20Hz까지 나올수있다고 하고 마무리하고 있습니다.
이를 기반으로 lidar model에서도 transformer기반의 아키텍쳐들이 많이 나올 것 같습니다.




