안녕하세요. 오늘은 3D Detection에서 multimodal Fusion에 대해 알아보겠습니다. Detection분야에서 멀티모달이라하면 보통 camera와 lidar를 이야기합니다.
Intro

위의 표는 개인적인 생각(?)을 포함하여 Fusion하는 Approach별로 나눈 표입니다. 우선 point-level방법은 raw data level에서 fusion을 해주는 방법입니다. 어떻게 보면 tightly coupled방법과 동일합니다. 문제는 image, pcd의 domain 영역이 다르기 때문에 이를 fusion method에서 어떻게 처리하는지가 제일 이슈인 방법입니다.
다음으로 proposal-level은 lidar, camera 각각 detection모델을 통해 proposal bbox를 뽑아내고 이를 fusion하는 방법론 입니다. 단점으로는 performance가 높지 않다는 점입니다.
마지막으로 feature-level에서 Fusion하는 방법이 있는데, 이는 image, pcd 에 backbone을 거쳐나온 feature map(voxel)을 Fusion하는 방법입니다. 최근 많은 논문들이 이 방법을 채택하고 있고 이번 포스팅은 Feature-level model들에 대해 살펴 볼 예정입니다.
번외로 VFF(Voxel Field Fusion for 3D Object Detection)은 nerf의 컨셉을 이용하여 2D image를 3D voxel에 투영하여 Fusion하는 방법입니다.
DeepFusion
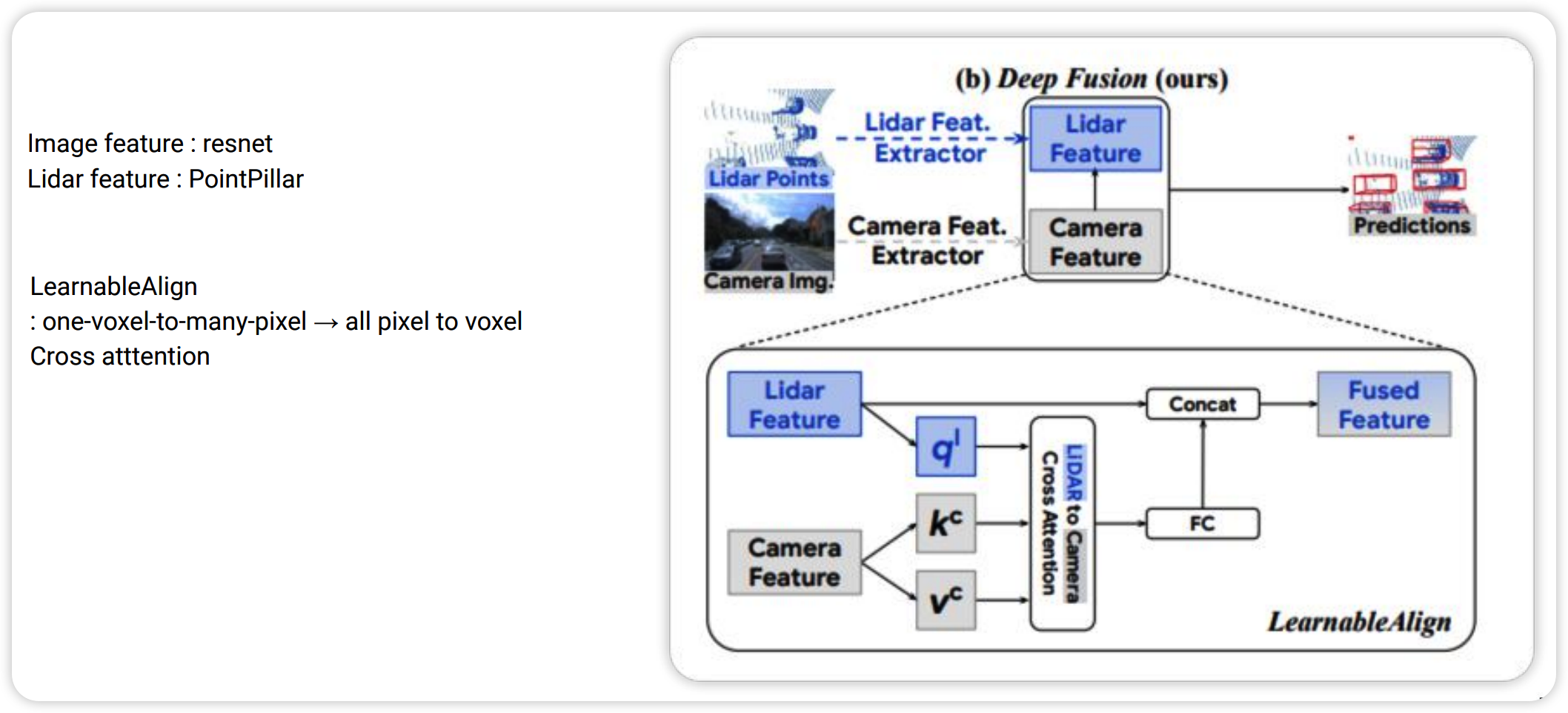
Feature based로 Fusion하는 방법들은 최근 Trasnformer를 사용합니다. Transformer에 대한 설명은 아래의 링크 참고하세요.
DeepFusion을 보면 Image Feature는 Resnet을 백본으로 하여 feature map을 만들고 PointCloud는 PointPillar를 백본으로 하여 Lidar Feature map을 만듭니다. 이 후 Transformer에서 cross-attention을 사용합니다. lidar feature를 query로 하고 camera feature를 key, value로 하여(q,k,v 모두 learnable value 입니다) cross-attention에 들어가게 되고 나온 output과 기존 Lidar Feature map과 concat하여 Fusion Feature를 만듭니다. 아이디어는 사실 비교적 간단합니다. 다음으로 3D Dual Field라는 논문을 보겠습니다. 마찬가지로 transformer를 통해 feature fusion을 진행합니다. 단지 모든 feature point끼리(2D,3D) cross attention하게 될 경우 많은 계산량을 필요로 하기에 보다 효과적인 Deformable Attention을 적용한 논문입니다.
3D Dual Field
해당 논문에서는 Deformable DERT 를 레퍼런스로하여 Fusion을 진행합니다.
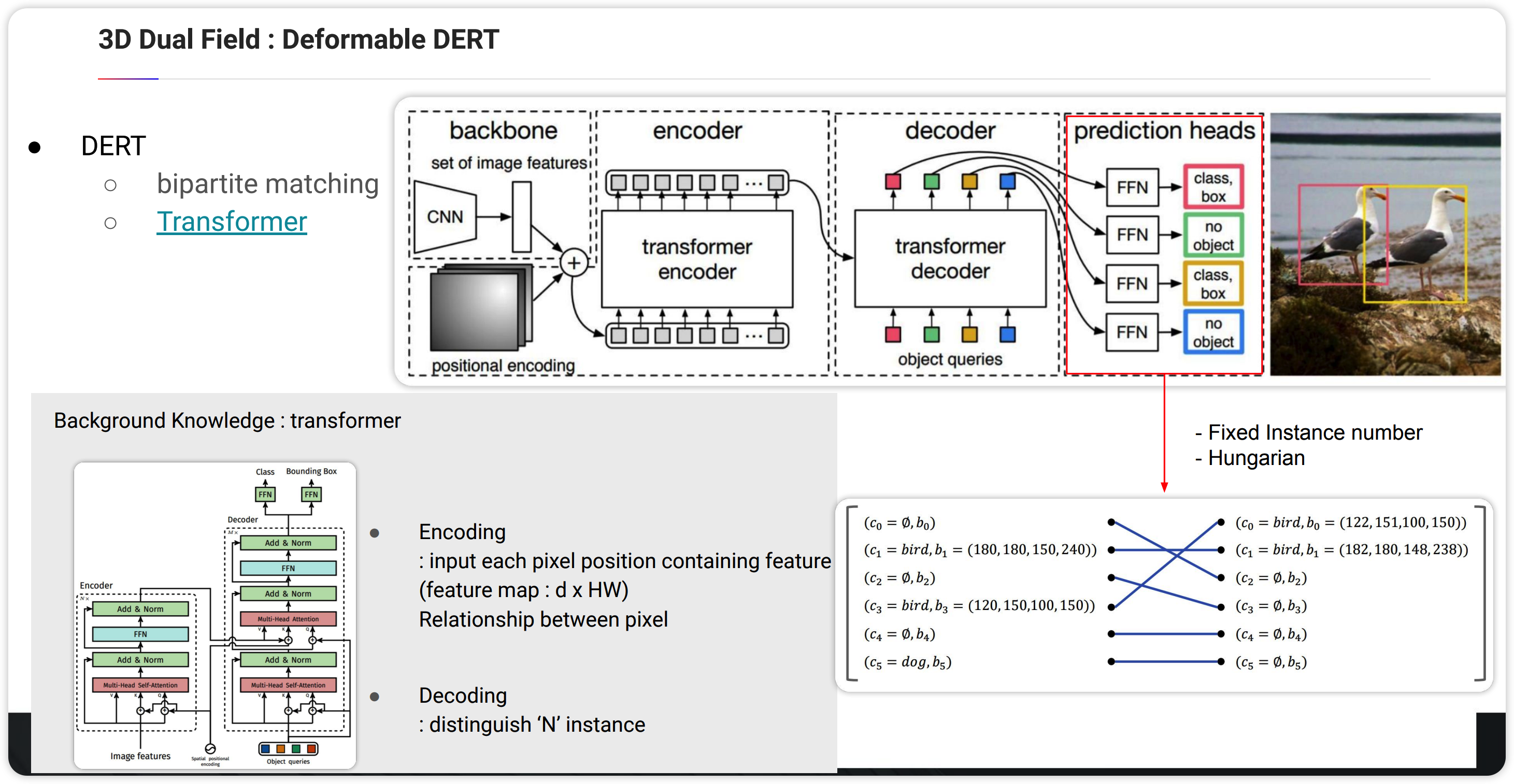
위의 그림은 DERT의 아키텍쳐입니다. detection자체는 사실 여기서는 중요한 부분은 아니고 transformer를 통해 detection을 진행하는데 small object에 대한 Presicion이 낮은 단점이 존재합니다. 보통 이를 방지하기 위해 Neck 모듈, FPN을 적용하게 됩니다. 이 경우 더욱 많은 feature point들끼리 cross-attention을 진행하게 되여 속도의 문제가 발생합니다. 이를 보안하기 위한 방법으로 Deformable DERT를 보겠습니다.
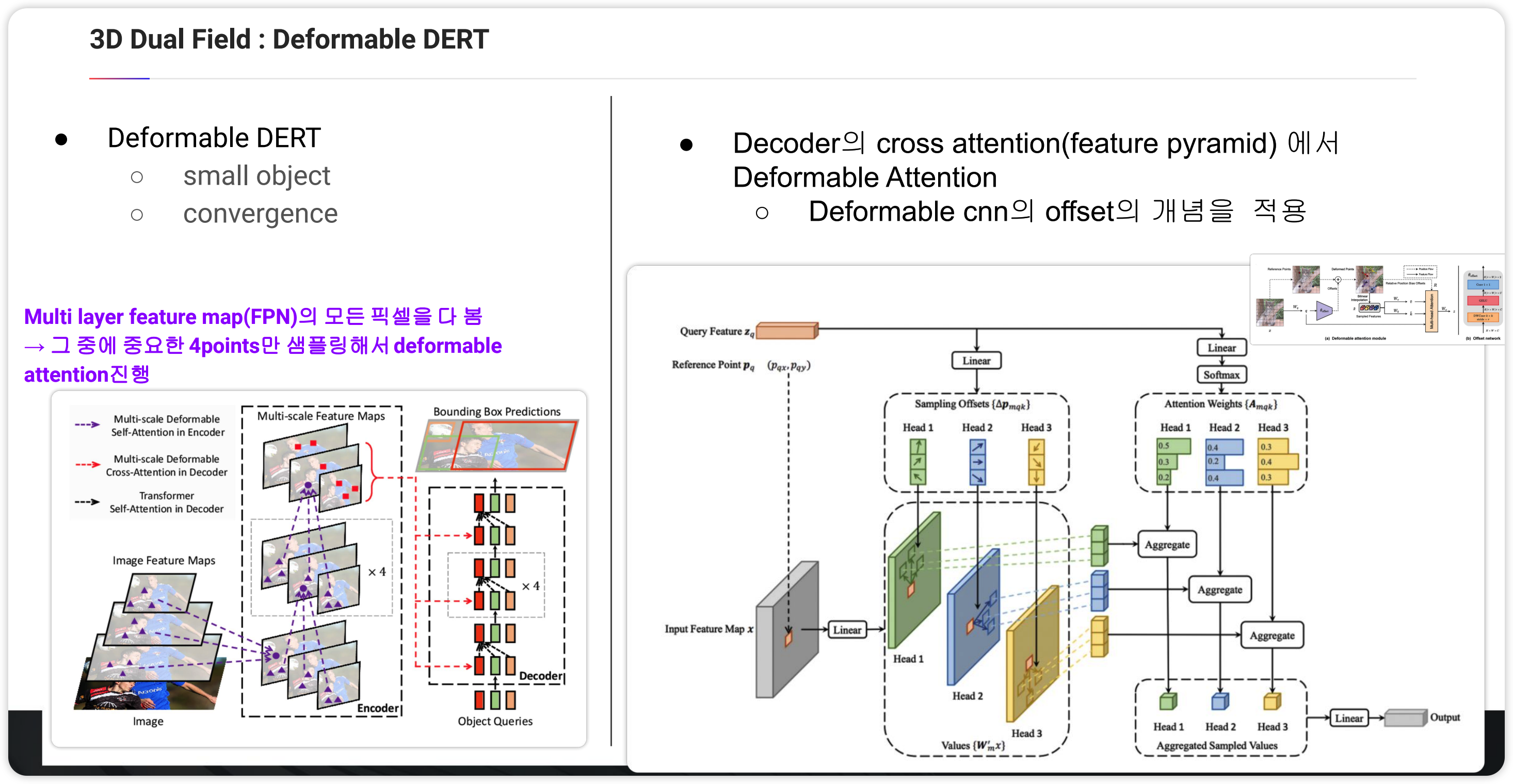
Decoder의 cross attention에서 Deformable attention을 적용합니다. 컨셉은 Deformable CNN에서 가져왔습니다. 좀 더 설명하면 Feature map을 reference로하여 하나의 Feature를 뽑습니다. 이에 대해서 offset를 그림에서는 3point를 뽑게 되는데 이 offset을 query로 명명하고 learnable한 변수입니다. 즉 해당 reference input point에 대해서 가장 적합한 offset point를 학습을 통해 뽑게 됩니다. 또한 weight 도 이 과정에서 학습을 통해 각각의 offset point에 대해 구하게 됩니다. 이후 feature map 에 해당하는 offset point의 value와 각각 aggregation하고 head 모듈과 LInear 과정을 output을 얻게 됩니다.
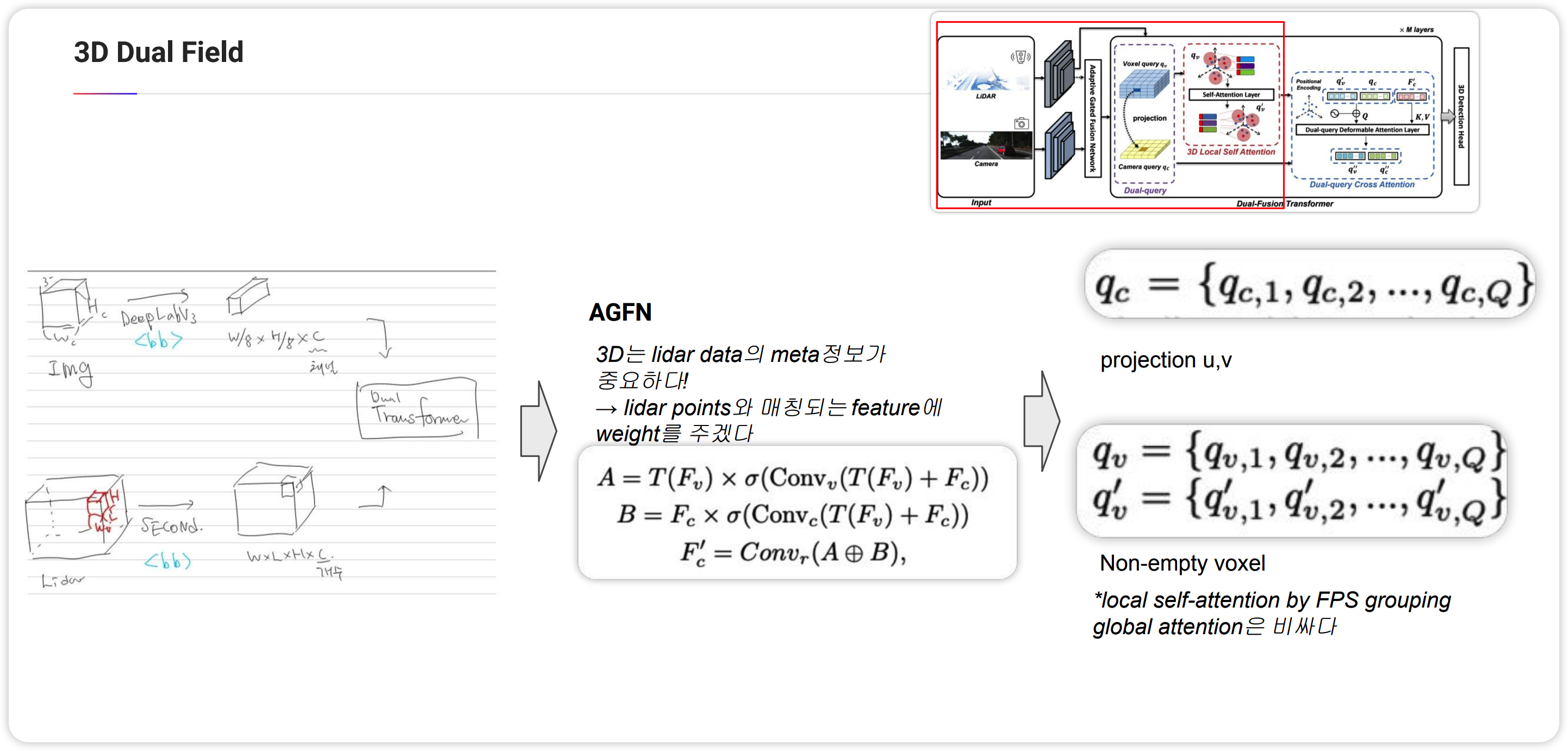
이제 3D Dual Field를 보겠습니다. DeepFusion과 마찬가지로 Image와 pcd에서 feature를 뽑는데, Image는 DeepLabV3을 백본으로 하고 pcd는 SECOND을 백본으로하여 각각의 feature map을 추출합니다. 이 후 AGFN 과정에서 2D Feature map을 업데이트를 합니다. 3D 에서는 lidar 정보가 중요하기 때문에 lidar points에서 projection했을 때 2D feature map에 매칭되는 부분에 weight를 가중하는 방식이며 학습을 통해 이루어져있습니다.
다음으로 Dual-Fusion Transformer과정을 보면 3D Feature map(voxel)에서 non-empty voxel만을 뽑습니다. 즉 point가 있는 Voxel만을 뽑는다는 뜻입니다. 이를 $q_v$로 정의하고 이를 2D feature map에 projection했을 때 매칭되는 2D feature를 $q_c$로 정의합니다. $q_v$는 한 번더 processing을 거치게 되는데 self-attention을 한 번 거칩니다. local하게 self-attention을 진행하게 되는데 time cost때문이라고 합니다. Local self-attention은 pointnet++에서 grouping하는 방법으로 FPS라는 방법을 쓰는데 이 방법을 이용하여 그룹핑을 하여 그룹안에서 self-attention을 수행하게 됩니다.
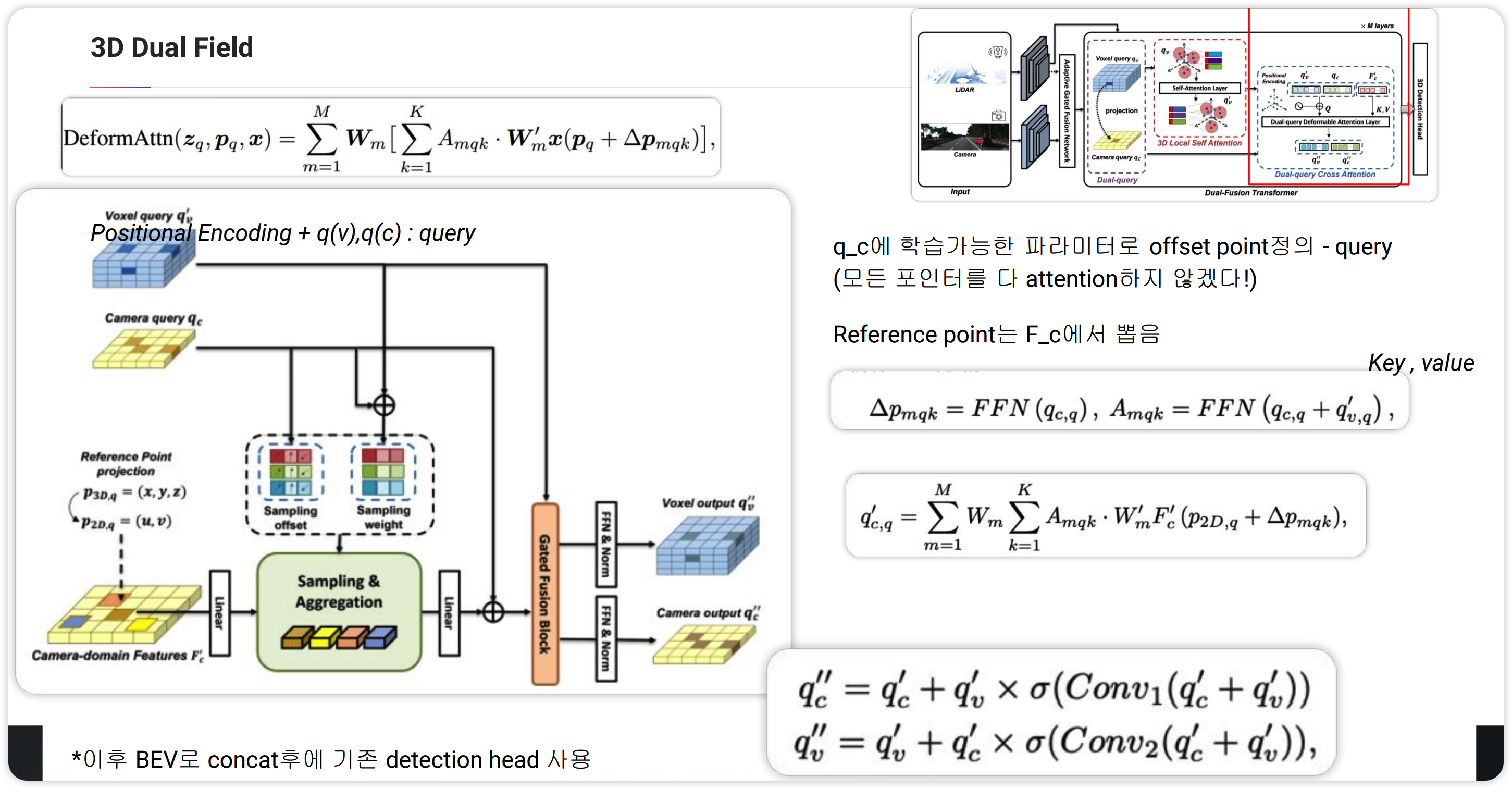
이렇게 얻은 query(c,v)를 가지고 위에서 설명한 deformable attention을 수행하게 됩니다. $q_c$를 query로 하여 offset과 weight를 학습을 통해 구하게 됩니다. 이 과정에서 voxel query$q_v'$를 concat하여 사용하게 됩니다. reference은 AGFN과정 이후 나온 2D feature map을 활용합니다. deformable attention과 다른점을 weight를 구할 때 3D query를 concat하는 점과 deformable attention후에 gated fusion block을 통해 2D정보와 3D정보를 fusion하는 과정을 거치는 부분입니다. 위의 그림의 block을 하나의 Layer로 여러번 반복하여 학습하게 됩니다. 이 후 나온 3D feature와 2D feature를 BEV로 concat한 후 원하는 detection head를 적용하여 bbox를 구하게 됩니다.
여기까지 3D detection에서 Multimodal일 때 Fusion하는 방법론에 대해 알아보았습니다.
감사합니다.




