[Detection] Object Detection History 1탄
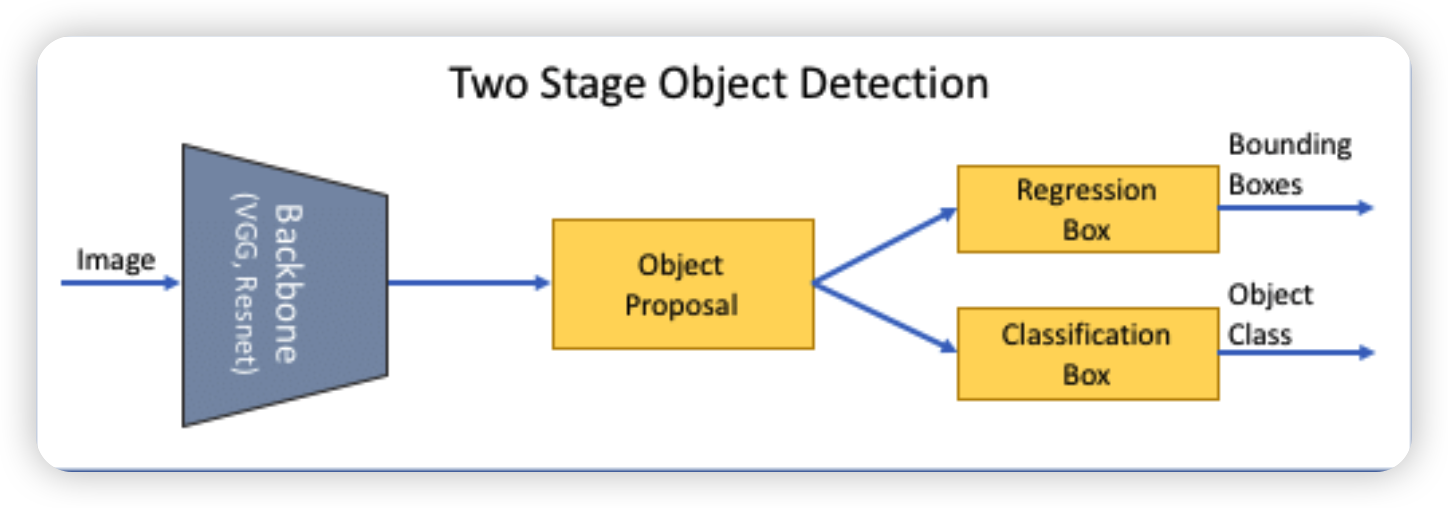
Object Detection의 발전과정 및 개요에 대해 키워드 중심으로 전체적인 맥락을 살펴보도록 하겠습니다. 정의 우선 정의 부터 살펴보자면, Classification/ Localization/ Detection/ Segmentation으로 구분하여 비
jaehoon-daddy.tistory.com
안녕하세요.
지난 포스팅에 이어서 object detection 관련하여 포스팅을 이어 나가겠습니다.
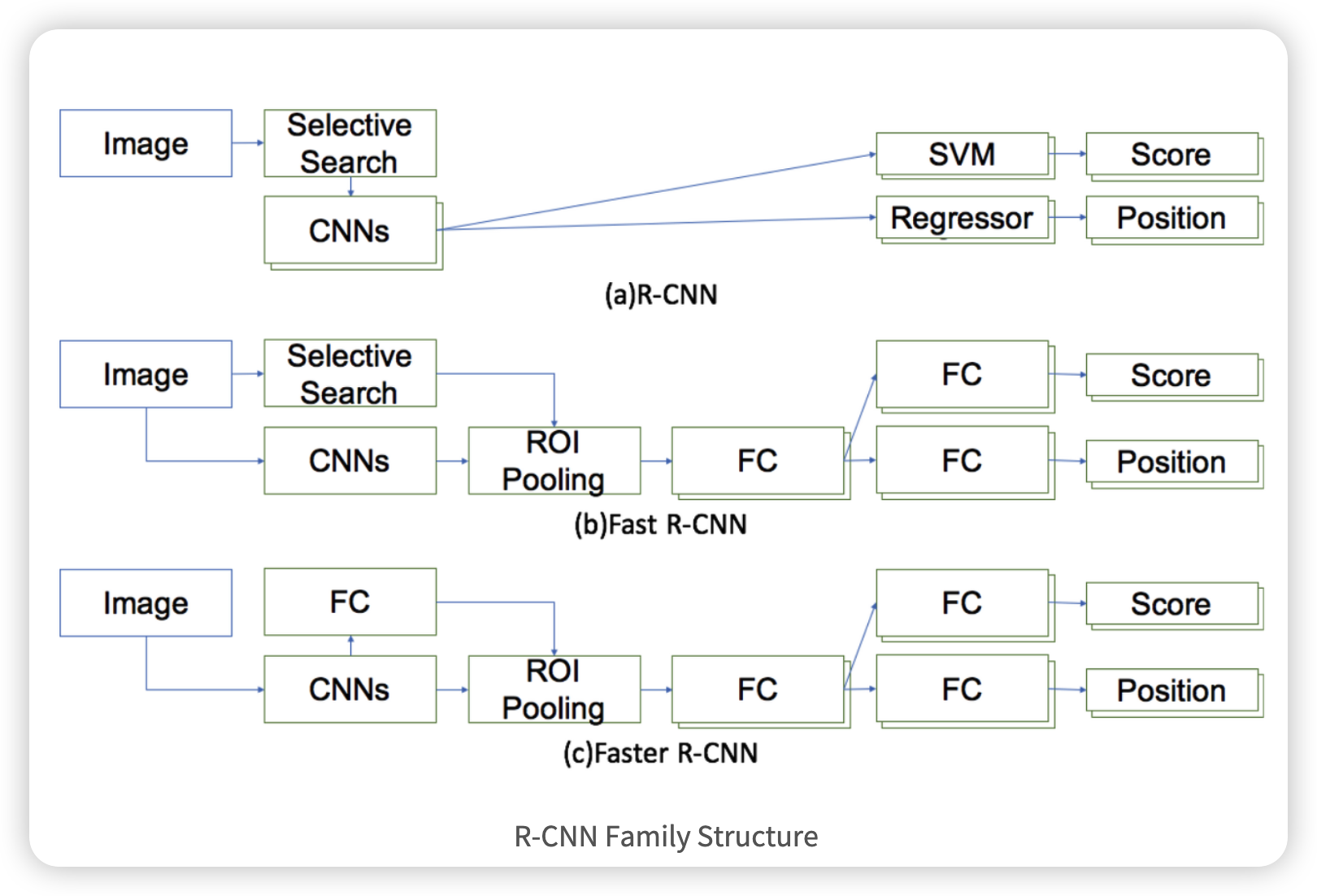
R-CNN 계열
1. R-CNN
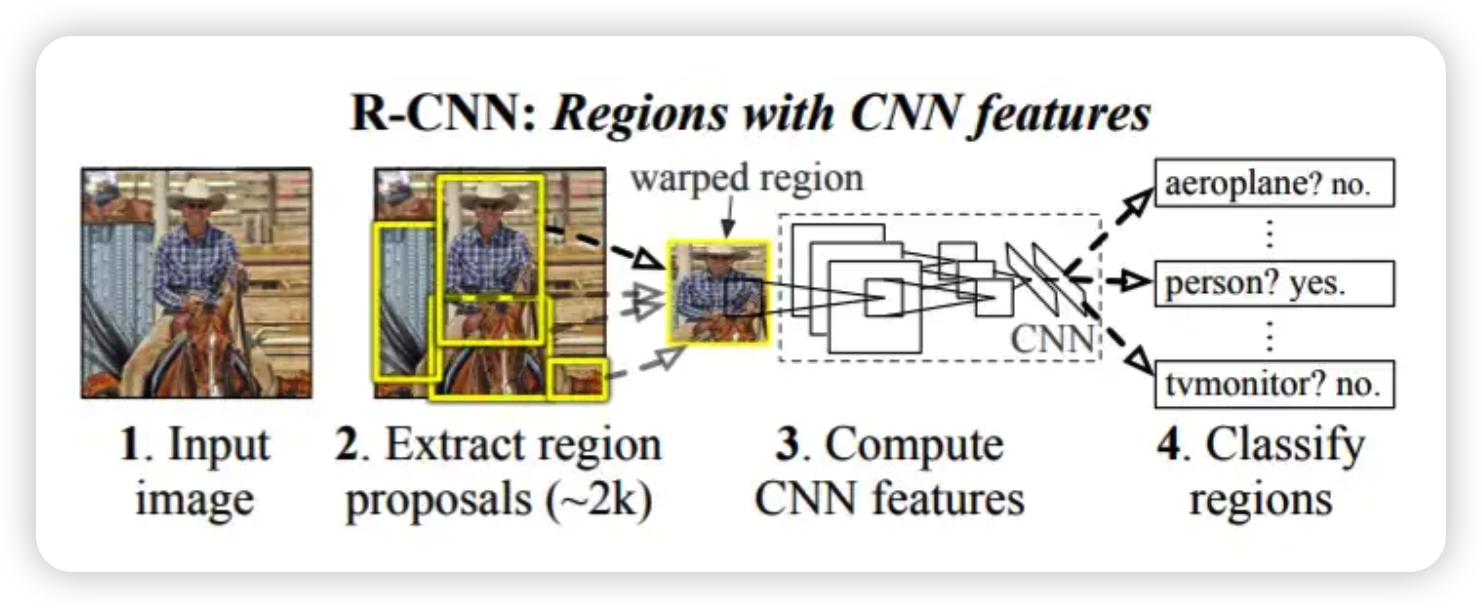
R-CNN은 VOC2012 대회에서 CNN을 활용하여 이전의 방법보다 30%가 넘는 큰 성능향상을 보였습니다.
특징 및 전체적인 흐름은 아래와 같습니다.
- Selective Search알고리즘을 이용하여 object가 있을만한 위치를 제안합니다.(약 2000개의 영역)
- 제안된 영역 2000개를 crop한 후에 (227 X 227) 사이즈로 warping시켜서 CNN model(AlexNet) 에 집어 넣습니다.
- 각각의 영역을 classification하여 object유무를 판별합니다.

구체적으로 CNN모델을 살펴보면 AlexNet Network 마지막 부분을 Detection을 위한 Class 수 만큼 바꾸고 Fine-Tuning을 진행하였습니다. 또한 SVM을 활용하여 classification을 진행하고 Bbox는 regression을 통해서 구하게됩니다.
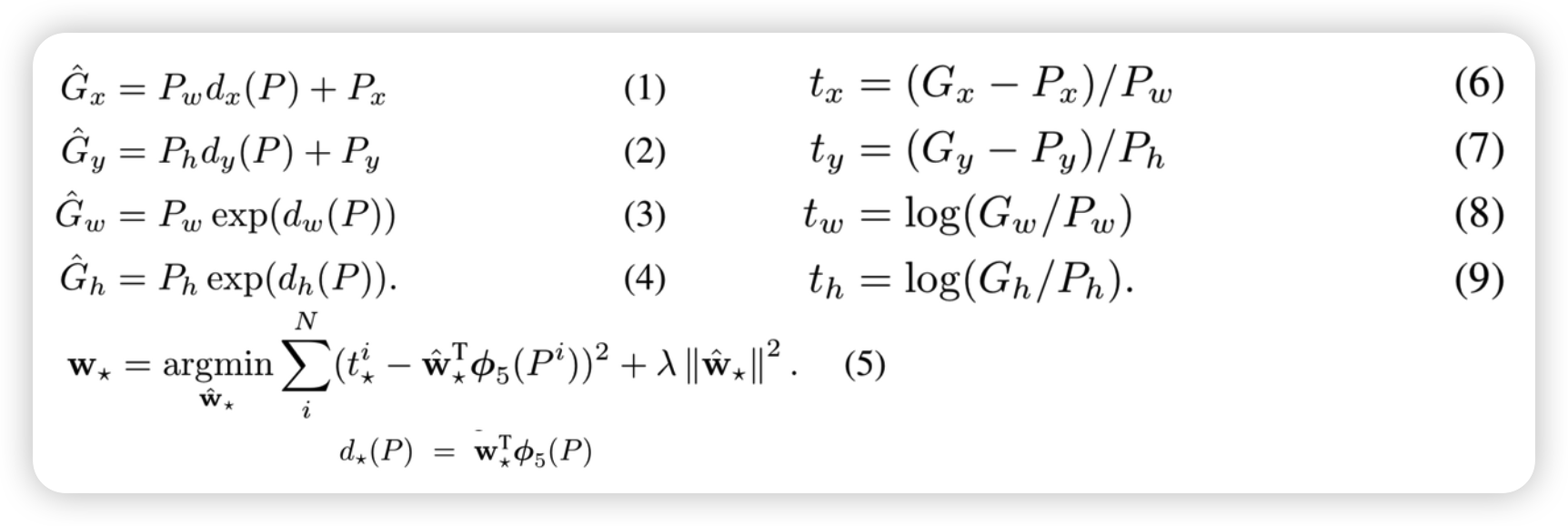
RCNN의 단점으로는 학습에 training, inference time입니다. selective search를 통해 나온 2000개의 region을 모두 CNN model에 넣어버리니 오래 걸릴수 밖에 없습니다. 또한 SVM, Regression, CNN의 multi-stage를 수행하다보니 end-to-end로 학습이 어렵습니다. 즉, SVM, Regression을 통해 CNN을 학습시키지 못합니다.
2. Fast R-CNN
Fast RCNN은 위에 RCNN의 단점을 보완하기 위기 위해 몇가지 방법을 사용하였습니다.
Fast RCNN도 RCNN과 같이 selective search방법으로 region을 proposal합니다. 하지만 각각의 영역에 대해서 CNN model을 적용하는 것이 아닌 전체의 이미지를 CNN model을 거쳐 나온 feature map에 selective search를 사용하여 얻은 proposal region을 projection하여 feature mapt상에서 region을 proposal합니다. 그렇게 되면 CNN model은 RCNN처럼 2000번 사용할 필요 없이 한번만 사용하면 됩니다. 즉, 시간이 획기적으로 줄어들게 됩니다.
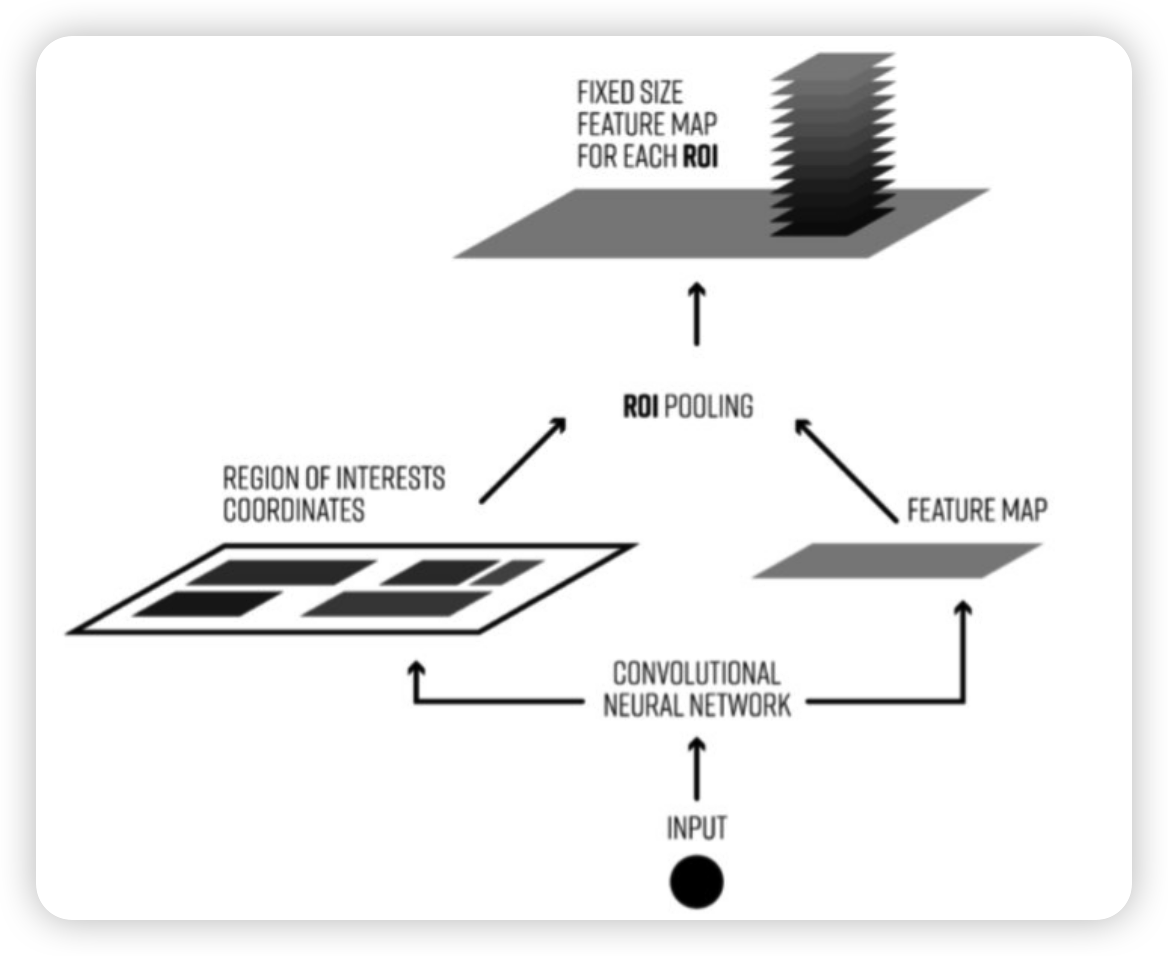
RCNN에서는 warping을 이용하여 input size에 proposal region의 크기를 변경하였습니다. Fast RCNN에서는 위의 그림처럼 ROI Pooling을 거치게 됩니다. ROI Pooling은 크기가 다른 Feature Map의 Region마다 Stride를 다르게 Max Pooling을 진행하여 결과값을 맞추는 방법입니다.

위 그림을 예를 들면 8x8 input feature map에서 Selective Search를 통해 7x5 짜리 Region을 proposal한 후에 이를 2x2로 만들어주기 위해서 Stride (7/2 = 3, 5/2 = 2) 로 Pooling Sections를 정하고 Max pooling 하여 2x2 output을 얻어 냅니다.
또한 SVM이 아닌 softmax를 이용하여 classification을 합니다.

Loss Function은 아래와 같습니다. classification과 regression을 동시에 학습할 수 있도록 두개의 loss을 한번에 나타내었습니다.


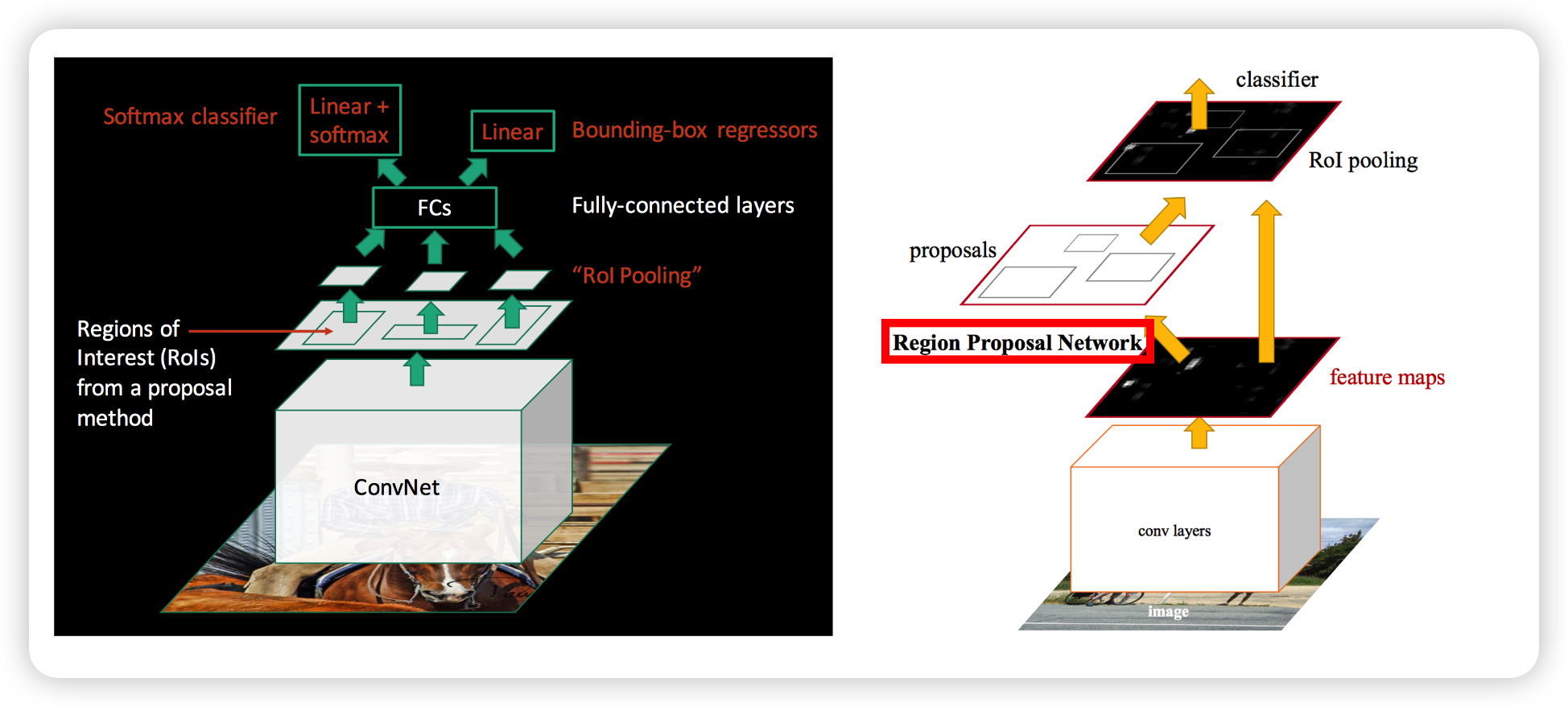
3. Faster R-CNN

Faster R-CNN에서는 Region Proposal영역 또한 GPU를 사용하여 속도를 최대한으로 뽑을수 있도록 하였습니다. 즉, RP부분을 learning based로 바꾸어서 모든 모듈을 Deep Network로 이뤄지게 하였습니다. 이를 RPN(Region Proposal Network)이라고 합니다.
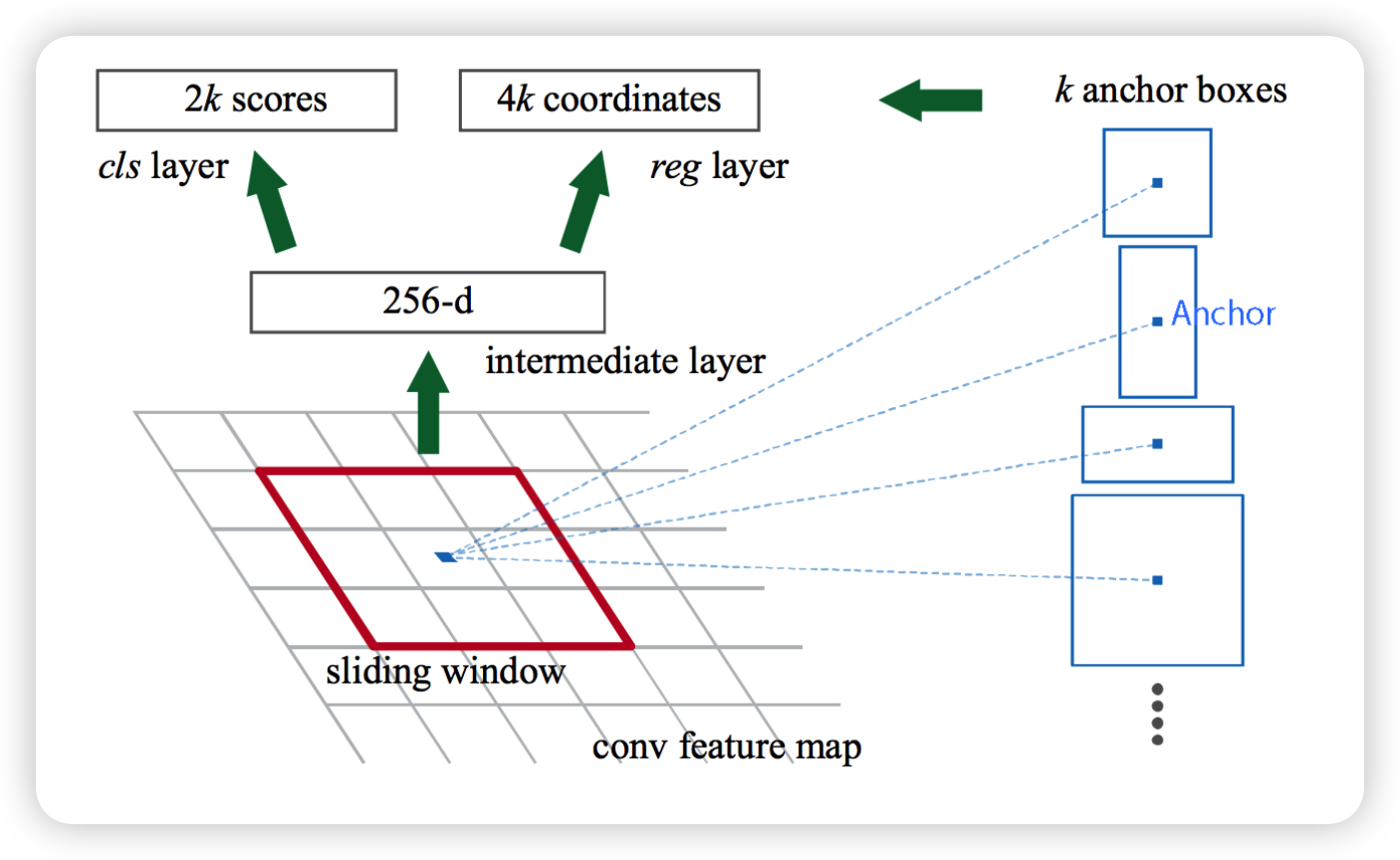
RPN은 내부 feature map의 영역내에서도 충분히 객체의 위치, 특징정보가 남아 있기 때문에 이 feature map 정보를 통해 학습을 하는 방식입니다. RPN에서 각각의 영역을 어떻게 학습할지에대해 논문에서 도입한 개념이 anchor box입니다. Anchor를 중심으로 anchor box를 설정해 feature map에서 영역을 설정합니다. Feature Map을 k개의 Anchor box를 통해 영역을 정하고 Classification Layer와 Bounding box Regression을 거쳐서 물체가 있는 곳을 학습하게 됩니다. 여기서 Classification Layer는 물체가 있는지 없는지만 확인하므로 Class수는 2입니다.
논문에선 k개의 anchor box를 정의해 사용한다고 나와있습니다. 논문에서 실제 사용한 anchor box는 크기에 따라 3가지, 가로 세로 비(ratio)가 다른 3가지를 포함해 총 9가지입니다. Scale 종류는 [128x128, 256x256, 512x512], ratio 종류는 [2:1, 1:1, 1:2] 입니다.
GT Label은 만들어진 각 Anchor들과 Ground Truth Box의 IoU를 모두 계산하여 IoU가 0.7보다 크면 1 (Positive), IoU가 0.3보다 작으면 0 (Negative) 으로 두고 나머지는 -1로 둬서 신경 안쓰도록 합니다. 이렇게만 하면 Positive한 Anchor의 개수가 많지 않을 수 있기 때문에 Ground Truth Box마다 IoU가 가장 높은 Anchor 1개를 뽑아 이 또한 1(Positive)로 Labeling 합니다.
이렇게 다양한 anchor를 기반으로 k개의 anchor box가 적용되어 multi-scale에 대해 학습하게 됩니다.
아래를 이를 나타낸 그림입니다.
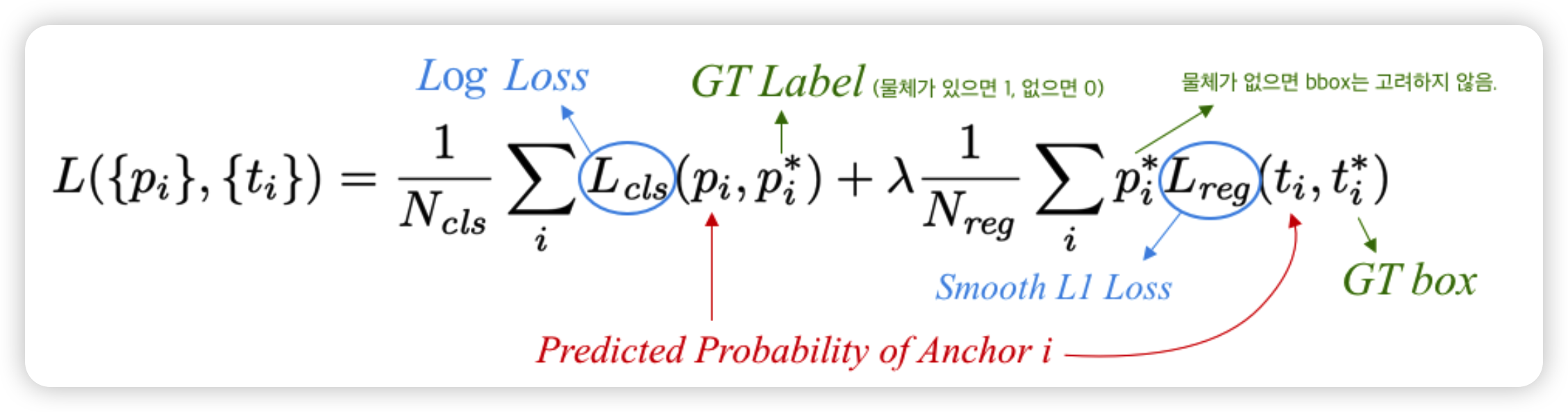
아래의 식은 RPN network의 loss function입니다. RPN Loss는 Fast R-CNN의 Loss와 함께 학습됩니다
최근에는 FPN(Feature Pyramid Network) 모듈을 활용하여 작은 object도 detection할 수 있도록 다양한 Feature map을 활용합니다.

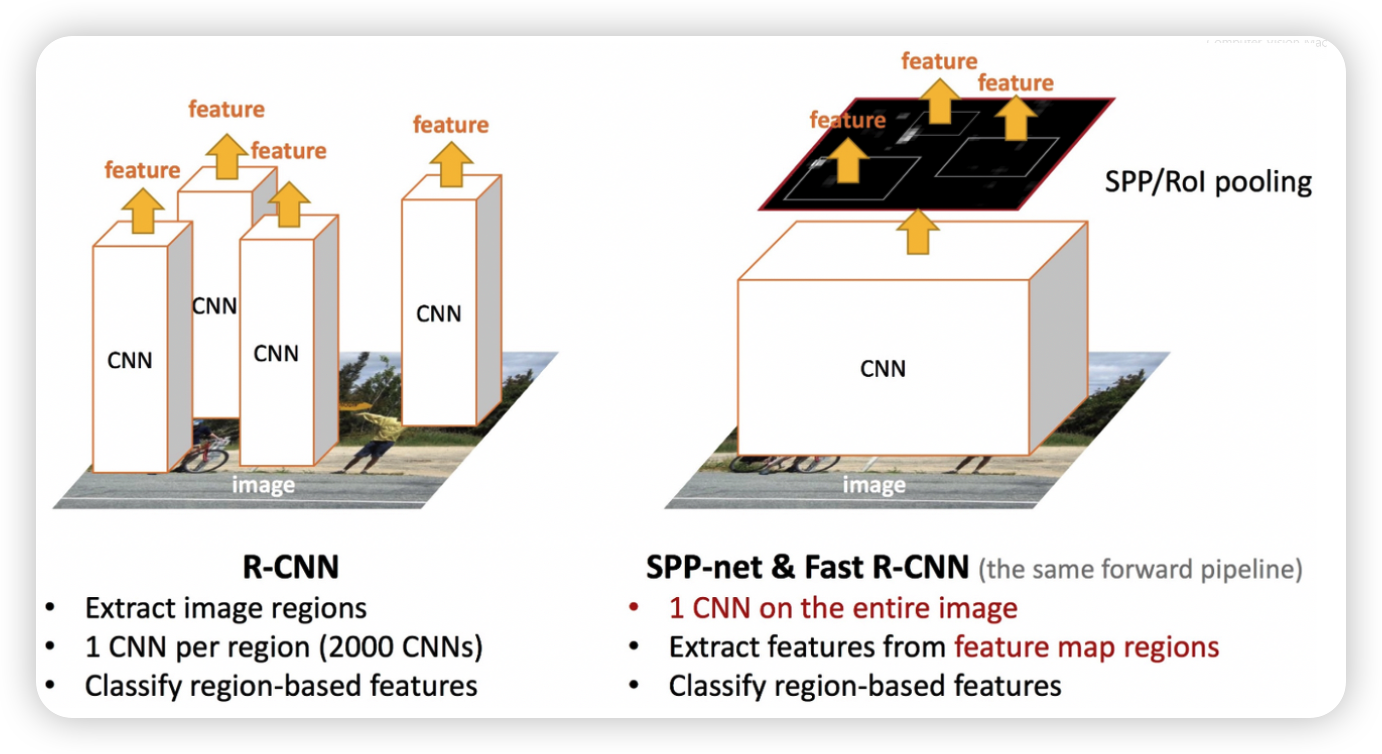
아래는 RCNN계열의 network를 간략하게 도식화하여 비교한 그림입니다.
이상으로 objection detection 2탄을 마치겠습니다. 다음 포스팅은 one stage관련 포스팅하겠습니다.




