![[paper review] PointPillars : Fast Encoders for Object Detection from Point Clouds 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcuqDaX%2FbtrVe4mU7TR%2FlKDa3uMDvpMuS6RIBdOBs0%2Fimg.png)
안녕하세요. 이번에는 3D object detector중 Pointpillars를 간단하게 리뷰하겠습니다.
CVPR '19에 퍼블리쉬 되었으며 Lidar만을 사용한 1-stage 3D object detector입니다.
기존에 VoxelNet에서는 3D conv를 사용하여 middle layer의 feature를 뽑기때문에 inference time이 느렸습니다. PointPillars에서는 2D conv를 사용하여 이를 해결하려 합니다. 2D conv를 적용하려면 3D point를 2D로 표현해야 하는데 해당 논문에서는 pillar feature를 이용하여 pseudo image를 만들어 3D point를 마치 image처럼 2D화 시킵니다.
*voxelnet에 대한 설명은 아래의 포스팅 참고하게요
[paper review] VoxelNet 리뷰
안녕하세요. 이번에는 3D object관련 논문 리뷰를 포스팅하겠습니다. VoxelNet은 '17년도에 apple에서 발표한 논문으로 lidar를 사용하여 voxel기반으로 detection을 수행하는 방법을 제시합니다. Lidar 3D objec
jaehoon-daddy.tistory.com
Architecture
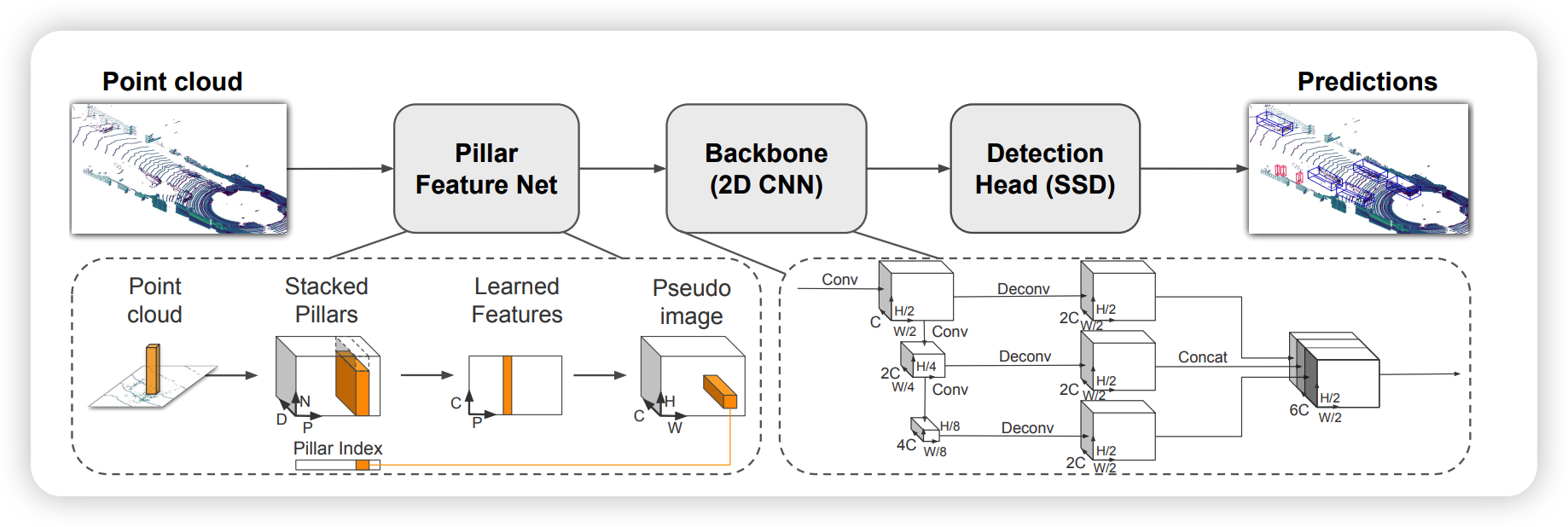
위 그림은 pointpillar의 architecture입니다. 우선 pillar feature net에서 point cloud를 2D conv를 적용하기위해 sparse pseudo-image로 변환합니다. 그 다음 2D conv로 이뤄진 backbone을 거쳐 고차원의 feature를 추출합니다. 2D conv를 사용하기에 3D conv를 사용한 voxelnet보다 computing time에서 이익을 보게 됩니다. 마지막으로 SSD를 사용하여 3d bbox를 regression합니다.
1. Pseudo-Image
우선 pseudo-image를 generation하는 부분을 보겠습니다. 우선 point들을 voxel이 아닌 pillar위에 위치하도록 pillar를 설정합니다. pillar는 voxel과 다르게 z direction으로 limit이 존재하지 않습니다. pillar내부의 points들은 원래의 raw data $x, y, z$에 $r, x_c,y_c,z_c,x_p,y_p$(c는 pillar안의 point들의 arithmetic mean을 뜻하고, p는 center 좌표를 뜻합니다) 를 concat하여 총 9-Dimension을 만듭니다.
lidar의 sparse한 특성상 empty pillar가 많기 때문에 $(D, P, N)$의 크기의 tensor로 encoding합니다.[voxelnet의 sparse tensor를 만드는 과정과 비슷한 것 같습니다 ]D는 위에서 말한 9dimension, P는 non-empty pillar의 개수, N은 pillar당 point의 개수를 뜻합니다. N은 pillar마다 다를수 있기 때문에 많은 땐 random sampling을 적용하고 적을 땐 zero padding을 합니다.
이 후 tensor를 simple pointnet을 태워서 pillar마다 feature vector를 뽑습니다$(C, P, N)$. 이 후 max-pooling을 적용하면 shape는 $(C, P)$가 되고 이 후 원래의 feature coordinate으로 mapping하여 $(C, H, W)$ pseudo-image를 생성합니다.
2. Backbone / Detection Head
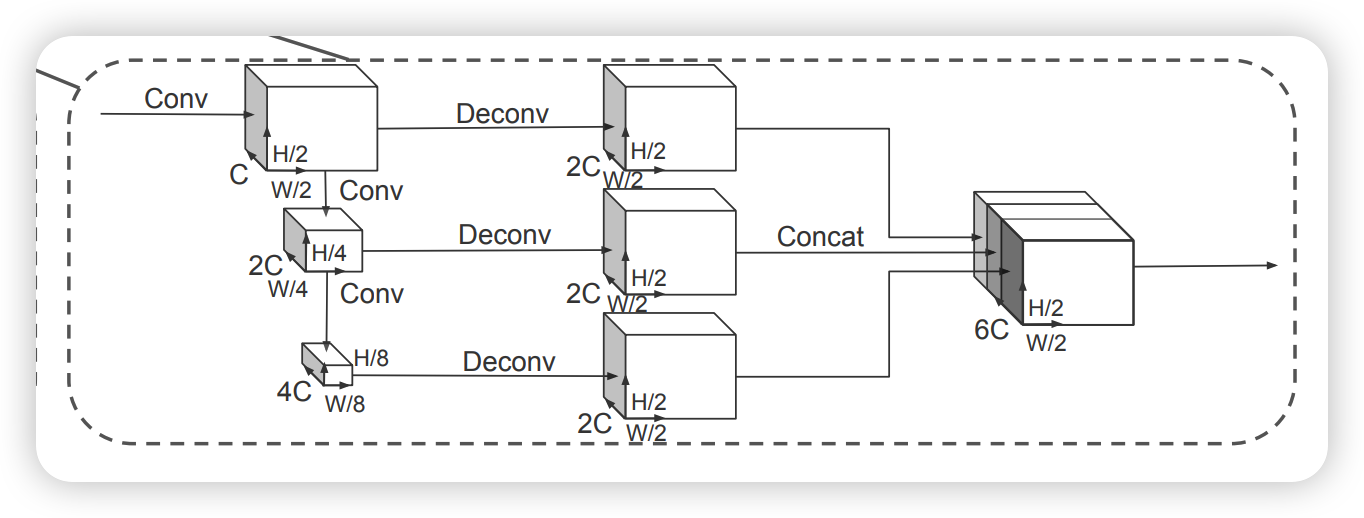
voxelnet과 비슷한 구조로, top-down구조에서는 small spatial feature를 생성합니다. 이 후 upsampling과정을 거친 후에 concat하게됩니다.
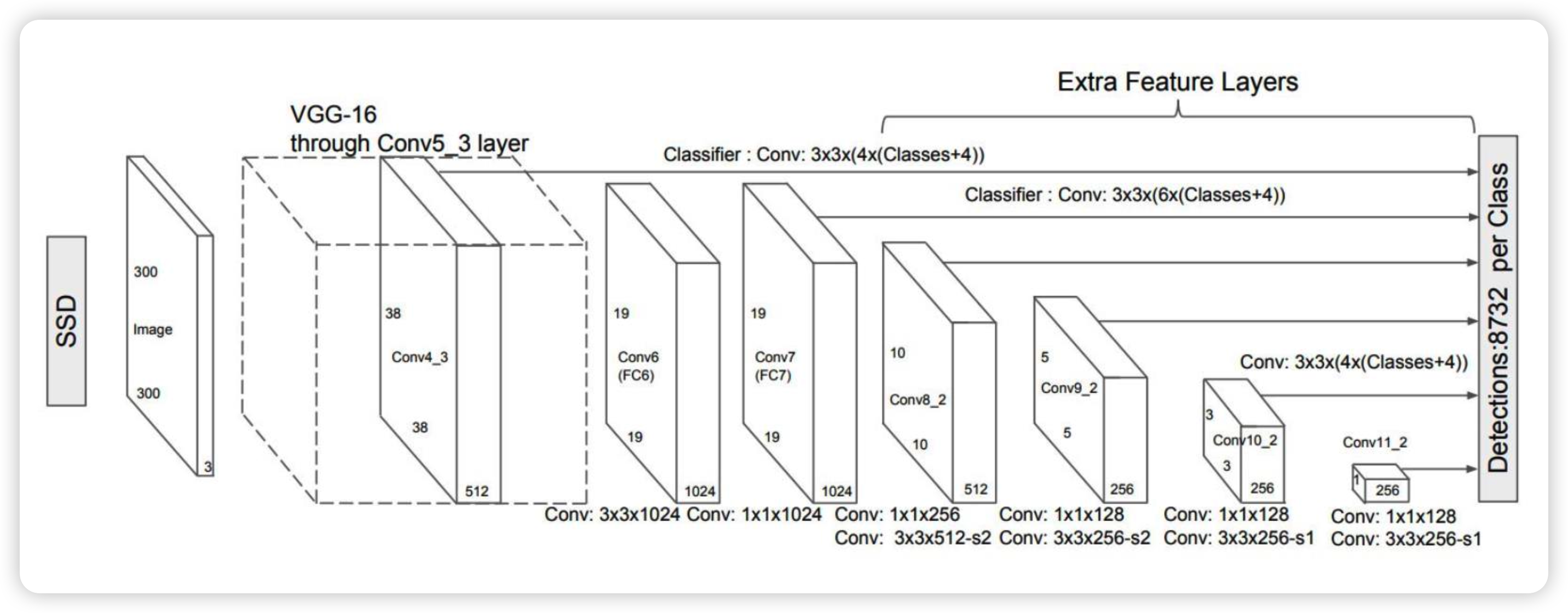
Detection Head에서는 SSD를 사용하여 regression합니다. 2D SSD와의 차이점은 height와 elevation이 추가된 점입니다.
3. loss function

loss function으로는 SECOND이라는 모델과 동일한 function을 사용하였습니다. GT와의 residual을 smooth L1에 적용하고 angle localization만으로는 뒤집어진 box를 구별하지 못하기 때문에 softmax 를 통해 heading을 학습합니다.
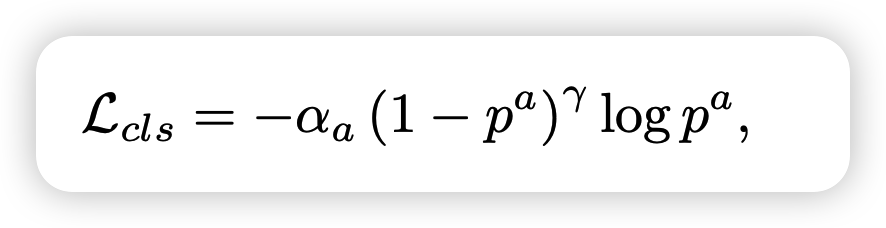
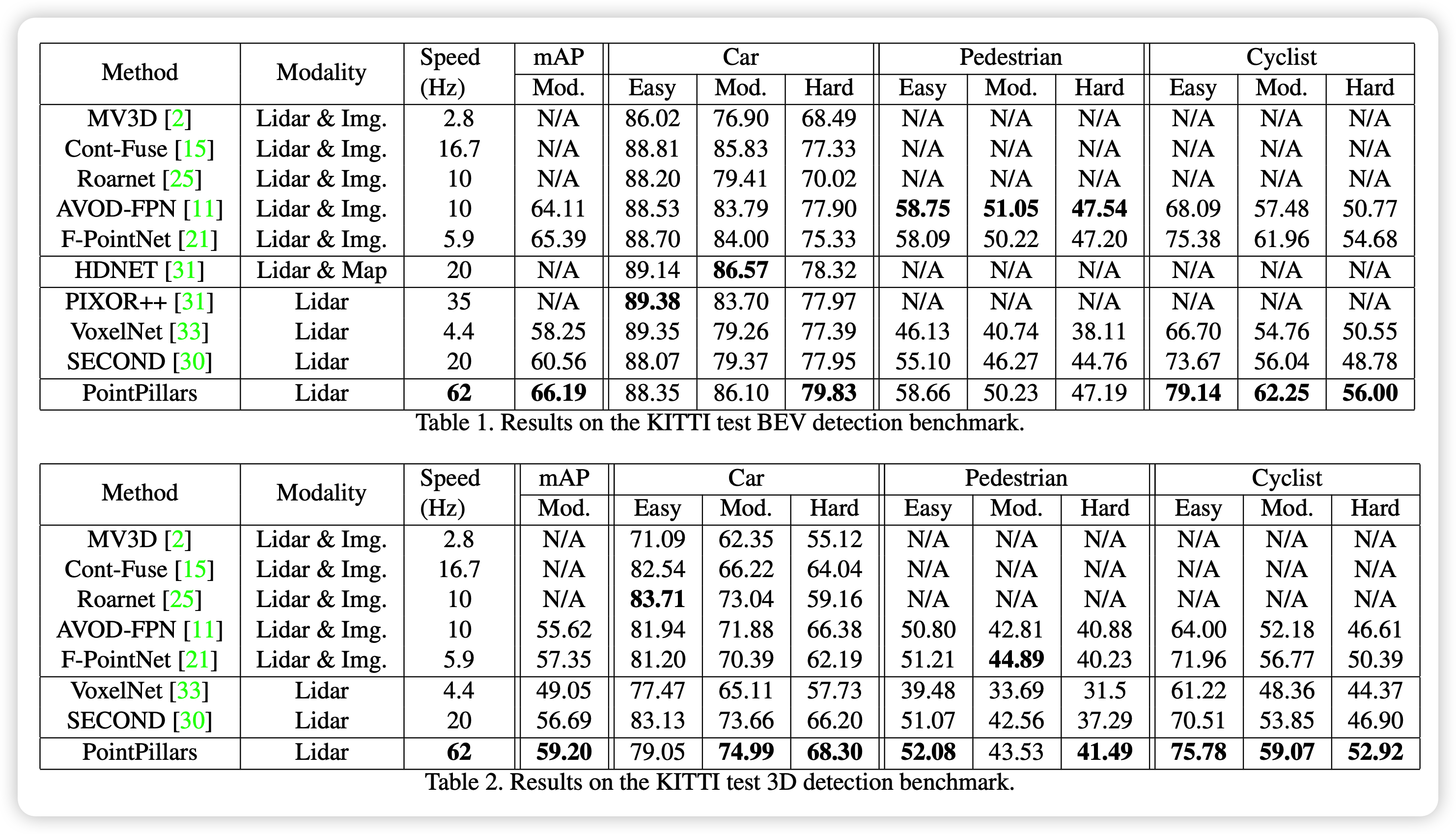
기존의 voxel를 이용한 방식에 비해 좀 더 metric이 좋은 것을 확인 할 수 있습니다.
이상으로 pointpillar에 대한 리뷰를 마치겠습니다.
