안녕하세요. 이번에는 3D object관련 논문 리뷰를 포스팅하겠습니다.
VoxelNet은 '17년도에 apple에서 발표한 논문으로 lidar를 사용하여 voxel기반으로 detection을 수행하는 방법을 제시합니다.
Lidar 3D object detection의 milestone이 된 논문으로 자세한 내용은 아래 설명할 예정입니다.
Architecture
기존 Lidar 3D object detection방법들 대비 해당 논문의 novelty와 contribution에 대해 살펴보겠습니다. 기존의 방법들은 RPN을 활용하기 위해 hand-crafted feature를 어떻게 뽑아낼지에 집중하였지만 해당 논문에서는 feature extraction과 RPN을 single stage로 하여 end-to-end deep network architecture를 제안하였습니다.

feature network
1. 위에 언급하였다시피 voxelnet은 voxel을 활용하여 feature를 추출합니다. 따라서 3D space를 x,y,z axis마다 3D voxel grid(D×H×W)로 만들어줍니다(class에 따라 voxel의 크기를 다를게 정의하며 tune의 영역입니다). 이 후에는 voxel마다 grouping작업을 실시합니다. 이 과정을 거치면 복셀마다 다양한 개수의 point를 갖게 됩니다. lidar 데이터는 sparse하기 때문에 대부분 빈 영역일 확률이 높습니다.
2. ~100k 개의 point가 들어있는 point cloud에서의 computing issue를 해결하고 sparse한 부분이 많기 때문에 밀도의 차이가 심하게 되어 bias가 생기는 것을 방지하기 위해 다음 Random Sampling단계를 거치게 되는데 이 단계를 통해 연산량 감소, density imbalance 해결, variation추가의 장점를 더해주게 됩니다.
3. VEF layer
다음으로는 VFE layer(Voxel Feature Encoding)단계입니다. 우선 raw point의 좌표를 (xi,yi,zi,ri), centroid point를 (vx,vy,vz)로 정의할 때 이 centroid point에 대한 각 raw point의 차이를 계산해 원래 raw point의 좌표에 concat하여 point-wise input을 만듭니다. (xi,yi,zi,ri,xi−vx,yi−vy,zi−vz)
이 후 FC단계를 거쳐 나온 feature중에 Maxpooling을 적용하여 point-wise feature중에 가장 큰 feature를 선택한 feature와 FC단계를 거쳐 나온 feature를 concat합니다. 이렇게가 한번의 VFE layer이고 이 작업을 n번 반복합니다. 그렇게 나온 feature의 크기는 처음 feature에 n배의 크기를 갖게 될 것 입니다.
모든 non-empty voxel은 위의 방법을 통해 feature encoding을 진행하게 되면 그 이후에는 voxel마다의 feature를 얻을 수 있게 됩니다.
Sparse Tensor
voxelizae결과 empty voxel이 90프로이상입니다. lidar 데이터 특성한 sparse하기 때문입니다. 따라서 메모리 및 연산량 낭비를 줄이기 위해 parse tensor representation방법을 사용합니다. 참고로 sparse matrix의 표현방법에 대해서는 아래 참고하세요.
Sparse Matrices · Matt Eding
Sparse Matrices 25 Apr 2019 Data Structures - Sparse Matrices Table of Contents Introduction Construction Matrices Coordinate Matrix Linked List Matrix Dictionary of Keys Matrix Compressed Sparse Matrices Compressed Sparse Row/Column Block Sparse Row Diago
matteding.github.io
Middle Layers
위에서 뽑은 feature를 이용하여 3D CNN을 수행합니다. (3D CNN → Batch Normalization → Activation)
즉, Voxel마다 feature를 추출하고(VFE) 그렇게 뽑은 voxel feature를 3D CNN을 태웁니다. 마지막으로 RPN을 거치게 됩니다.
아래는 RPN(Region Proposal Network)의 구조입니다.
RPN 구조에서 Conv3D가 아닌 Conv2D가 사용된 이유는 middle layer에서 4D의 shape(channel, z, y, x) 을 3D로 reshape하기 때문입니다.(BEV:bird eye view feature map형태)
Loss Function
loss는 class score, bbox regression에 관한 loss를 의미합니다. BEV상에 grid마다 2개의 anchor box를 사용합니다. 그렇게 되면 score(해당 class일 확률-classifiction)관련 channel 2개, bbox regression(x,y,z,l:길이,w:폭,h:높이)관련 channel 14개가 됩니다.
이렇게 prediction한 값들과 GT값들과의 비교를 통해 loss를 구하게 됩니다. 구체적으로는 아래에 설명하겠습니다. 설명하기 전에 기본적인 용어는 아래의 포스팅 참고하세요
[Detection] Object Detection History 1탄
안녕하세요. 후니대디입니다. 이번 포스팅에서는 Object Detection의 발전과정 및 개요에 대해 키워드 중심으로 전체적인 맥락을 살펴보도록 하겠습니다. Definition 우선 정의 부터 살펴보자면, Classifi
jaehoon-daddy.tistory.com
각각의 anchor box와 GT bbox와 IoU를 구하고 이 값이 threshold를 넘으면 positive anchor, 작으면 negative anchor로 정의합니다. positive anchor의 score는 1이 되도록, negative anchor는 0이되도록 binary cross entropy를 사용하여 loss function을 정의합니다. 또한 positive anchor에 대해선 bbox를 regression해야하기 때문에 regression loss를 정의합니다. 이를 정리하면 아래의 식으로 표현가능합니다.
위에서 설명한 classification에 대한 loss function입니다. 3번째 term은 아래의 regression loss를 의미합니다.
regression bbox에 대한 regression loss로 smooth L1 loss를 사용하였습니다.
Efficient Implementation
위에서 설명한 sparse tensor의 자세한 방법에 대해 다루겠습니다. GPU처리에 있어서 sparse한 point cloud의 성질은 맞지않습니다. 이를 dense하게 만들기 위해서 아래의 그림과 같은 과정을 수행합니다.

위 그림을 설명하면 K×T×7의 shape의 voxel input feature buffer와 K×1×3의 voxel coordinate buffer를 생성합니다. K는 non-empty voxel의 최대 개수이고, T는 voxel이 가질 수 있는 point의 최대 개수입니다. 그리고 위에서 설명한 7개의 좌표 (xi,yi,zi,ri,xi−vx,yi−vy,zi−vz)를 삽입니다. non-empty voxel이므로 한 행이 전부 sparse한 부분은 없을 것이고 voxel내부의 point가 다르기 때문에 빈곳이 있을 것인데 이는 0을 채워넣습니다. 이렇게 dense한 matrix를 만들어냅니다. 그리고 이렇게 dense한 map을 mapping하고 다시 이전으로 de-mapping하기 위해서 voxel coordinate buffer를 사용합니다.(즉, index를 mapping하는 역할을 합니다). 결국 voxel input feature buffer를 이용해 GPU연산을 통해 voxel-wise feature를 얻고나면 voxel coordinate buffer를 통해 3D voxel grid로 mapping시키게 됩니다.
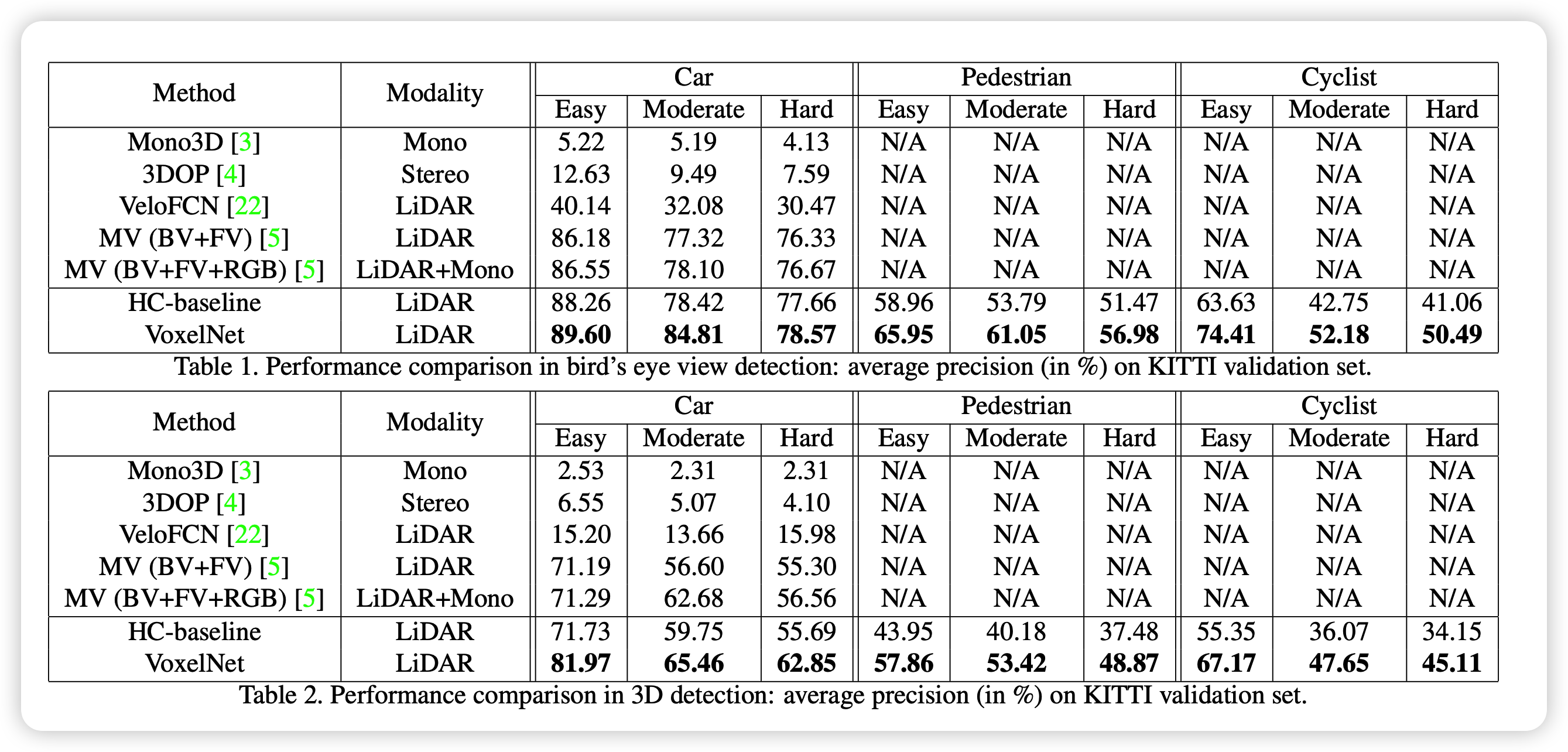
VoxelNet은 voxel을 활용한 매우 간단한 논문이지만 기존의 handcrafted feature가 아닌 end-to-end로 상당한 성능향상을 가져온 1-stage 논문입니다. 1-stage논문의 시발점이라고 볼 수 있겠습니다.
이상으로 VoxelNet 리뷰 마치겠습니다.




