안녕하세요. 이번에는 Lidar 3D object detection의 대표, CVPR '19에 퍼블리쉬된 pointRCNN 논문리뷰를 진행하겠습니다.
pointRCNN은 대표적인 2-stage detector입니다. 기존의 detector들은 point cloud의 irregularity를 해결하기 위해 BEV로 projection을 하거나 3D voxelization을 하였습니다.(quantization 문제발생)
* 3D voxelization의 대표 디텍터로는 VoxelNet으로 아래 포스팅 참고하세요.
[paper review] VoxelNet 리뷰
안녕하세요. 이번에는 3D object관련 논문 리뷰를 포스팅하겠습니다. VoxelNet은 '17년도에 apple에서 발표한 논문으로 lidar를 사용하여 voxel기반으로 detection을 수행하는 방법을 제시합니다. Lidar 3D objec
jaehoon-daddy.tistory.com
이에 반해 pointRCNN은 3D points representation을 그대로 사용합니다(point-based method). 그렇게함으로서 보다 더 3D information을 더 잘 활용할 수 있게 됩니다. 또한 전체적인 pipeline을 two-stage로 가져갑니다. 시간은 조금 더 소요되겠지만 정확도가 높아지는 장점이 있습니다.
Architecture

위의 그림은 pointRCNN architecture입니다. bottom-up방식으로 윗부분이 stage-1, 아랫부분이 stage-2로 볼 수 있습니다.
Stage-1 : Point Cloud representation of input scene
우선 첫번째 stage부터 살펴보겠습니다. backbone으로는 pointNet++를 사용합니다. pointNet++를 태우고 나서는 point마다 feature vector를 얻게 됩니다. 이를 통해 3D bbox 생성과, foreground point segmentation을 구합니다. Foreground point는 bbox내부에 있는 point를 뜻합니다. (밖에있는 point는 background point라고 합니다)
보통 이미지에서는 background와 foreground로 분리하려면 segmentation label이 있어야합니다. 하지만 3D point에서는 bbox GT label 만으로도 segmentation을 어느정도 수행할 수 있습니다. image처럼 fix-position이 아니기 때문에 3D bbox내부에 있는 point를 foreground, 그렇지 않은 point를 background로 label하면 됩니다.
Training시에는 GT 3D bbox를 통해 3D box generation과 foreground point segmentation을 동시에 수행하고 inference에서는 segmentation을 수행하여 나온 foreground points를 이용해 3D bbox를 generation합니다.
loss function
위에서 말한 stage-1의 seg, 3D box generation을 위한 loss를 살펴보겠습니다. 우선 segmentation같은 경우 background point가 foreground point보다 훨씬 많기때문에 focal loss를 사용합니다. 또한 GT bbox가 매우 정확하진 않을 수 3D bbox크기를 0.2m씩 늘려서 적용합니다.
bbox regression은 object의 center 위치(x,y,z), 크기(l,w,h), orientation(θ)로 구분할 수 있습니다. centor localization은 x,y,z축으로 쪼갤수 있고 그 중 x,z축을 discrete한 bin으로 다시 쪼갭니다. 아래 그림을 참고하세요.
x,z축에서 위치를 찾는 방법은 2-step을 거칩니다. 1. bin-based classification으로 object center가 bin기반의 grid에서 어떤 grid에 속하는지는 찾고 2. grid cell내에서 fine tune하면서 더 정확한 위치를 찾는 것 입니다.
y축, object의 크기는 smooth L1 loss를 사용해서 residual값을 regression합니다. orientation은 x,z축과 비슷하게 2π를 n개의 bin으로 쪼개서 regression을 수행합니다. 이를 aggregation해서 표현하면 아래와 같습니다.
이렇게해서 구한 stage-1의 foreground point에서 BEV기준으로 training시에는 IoU기준 0.85로 NMS를 수행해서 top 300개만 남겨 stage-2로 넘깁니다. inference시에는 0.8로 NMS를 적용해서 top 100개만 사용합니다.
*용어를 모르신다면 아래의 포스팅 참고하세요
[Detection] Object Detection History 1탄
안녕하세요. 후니대디입니다. 이번 포스팅에서는 Object Detection의 발전과정 및 개요에 대해 키워드 중심으로 전체적인 맥락을 살펴보도록 하겠습니다. Definition 우선 정의 부터 살펴보자면, Classifi
jaehoon-daddy.tistory.com
Stage-2 : Canonical 3D bbox refinement
다음으로 architecture그림에서 아랫부분에 해당하는 stage-2에 대해 설명하겠습니다. pooling 단계에서는 proposal bbox를 각각 l,w,h방향으로 각각 η 만큼 enlarge하여 주변 context가 함께 encoding되도록 합니다. enlarged bbox 내부에 속하는 point와 feature를 refinement에 사용합니다. 사용하는 feature는 위 그림에서 확인할 수 있습니다. [ raw points, semantic feature(resulted from Pointnet++), segmentation mask ]
위에서 언급한 enlarged bbox에 속하는 point와 feature를 이용하여 classification과 bbox regression refinement를 수행합니다. classification에서는 class여러개를 cross entropy를 활용하여 구하는 것이 아니고 class 마다 binary cross entropy를 활용하여 class가 맞는지 아닌지를 판단합니다. (yolo v3처럼)
refinement를 수행할 때 Canonical transformation을 수행합니다. canonical transformation이란 기준 좌표계로 변환시켜주는 작업이고 여기서의 canonical transformation은 각각의 object의 local coordinate를 뜻합니다. 아래 그림을 참고하세요
local spatial feature는 local coordinate의 정보이기 때문에 depth정보를 잃게 되기 때문에 global coordinate상의 depth를 local point마다 추가합니다. 이 과정을 통해서 local spatial feature를 더 잘 학습할 수 있다고 합니다.
즉, canonical coordinate상의 좌표 + reflection intensity + segmentation mask + distnace를 모두 concat한후 FC를 거쳐 encoding하게 됩니다. 이렇게 얻은 local spatial featrue를 stage-1에서 구한 global semantic feature와 다시 concat한 후 bbox refinement와 confidence prediction을 수행하는 네트워크로 들어가게 됩니다.
loss function
confidence prediction을 위해서 GT bbox와 IoU가 0.55보다 큰 proposal은 positive label을 그렇지 않은 proposal은 negative label을 적용하여 cross entropy loss를 계산합니다.
bbox refinement는 위세어 GT bbox가 positive인 proposal에 대해서만 수행합니다. 방법은 stage-1과 동일하게 bin-based localization을 수행합니다.
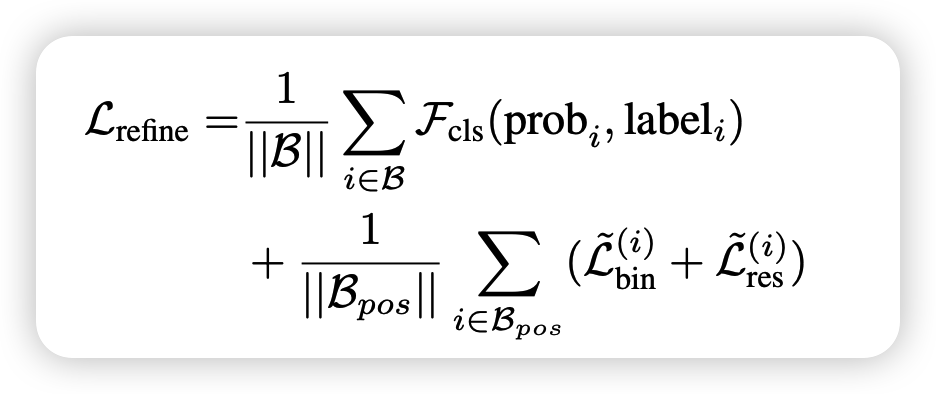
이후 BEV기준으로 IoU threshold 0.01을 수행하여 최종적인 3D bbox를 구합니다.
아래는 실험결과입니다. pedestrian은 오히려 meric이 낮네요.

이상으로 3D object detector의 2-stage의 milestone pointRCNN에 대해서 리뷰해보았습니다.




