안녕하세요.
PointNet++ 논문 리뷰 시작하겠습니다.
시작하기전에 PoinetNet++의 전신인 PointNet리뷰를 먼저 참고해주세요.
[paper revew] pointnet 논문 리뷰
이번 포스팅은 3D pointcloud detection의 고전 pointnet를 보겠습니다. PointNet pointnet은 딥러닝을 사용한 pointcloud detection 분야의 고전으로 현재 많은 알고리즘의 토대가 되는 논문입니다. 우선 3D pointcloud
jaehoon-daddy.tistory.com
기존 PointNet의 문제
기존의 PointNet은 이전의 방법론에 비해 월등한 성과를 이뤄냈지만 단점이 존재합니다. unordered 의 특성을 해결하기 위해 point마다 MLP로 구성된 model에 들어가고 global max pooling을 통해 전체적인 feature를 파악하게 됩니다. 이 과정에서 PointNet은 한번의 global max pooling만을 활용하다 보니 local structure를 유추하기가 힘듭니다. CNN같은 경우는 local information을 단계적으로 정보를 유추하여 모델의 마지막 부근에서는 global한 정보까지 유추하게 됩니다. 즉, 자연스럽게 local feature부터 global feature까지 추출하게 됩니다. PointNet++은 PointNet의 local feature를 추출하기 힘든 문제를 해결하려 했다는 것이 주요 contribution입니다.
Method

Image에서는 고정된 grid에 data가 있기 때문에 CNN과 같은 방법을 통해서 local feature를 추출하기 쉽습니다. 하지만 pointcloud같은 경우는 variable density, feature scale, drop out등의 이유로 local이 어디서부터 어디까지인지 정하는 것 자체도 쉽지 않습니다. 이를 위해 PointNet++에서는 sampling -> grouping -> mini pointnet 과정을 거칩니다.
Sampling
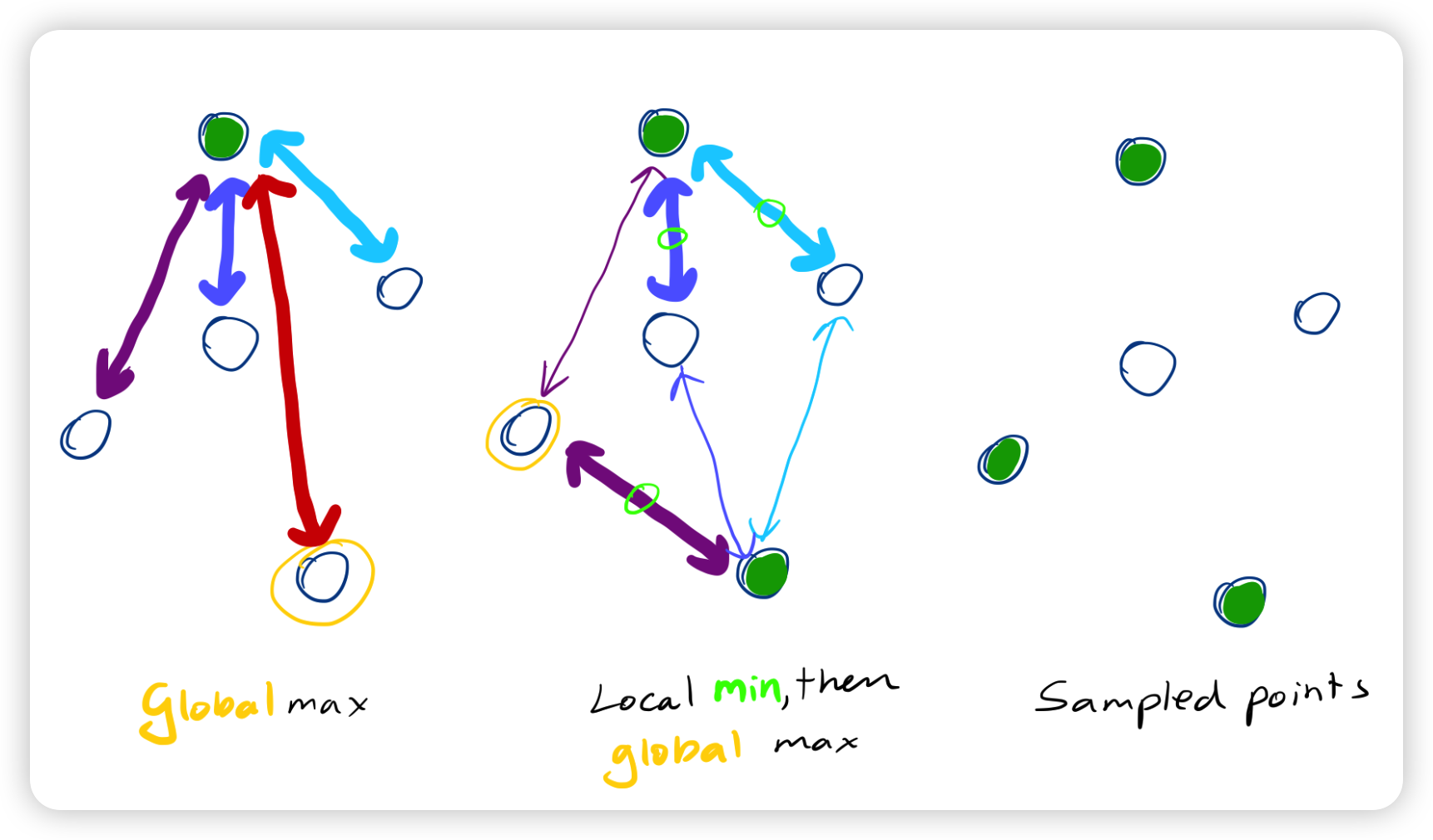
sampling과정에서는 pointcloud에서 대표가 되는 점들을 선택합니다. 즉, local한 공간에서의 중심을 의미합니다. 우선 N개의 pointcloud에서 $N^`$개의 점들을 샘플링합니다. 샘플링할 때 점들간의 유클리드 distance가 가장 먼 점들로 선택합니다. 이 과정을 Farthest point sampling이라고 합니다..
Furthest Point Sampling
I have come across an algorithm named furthest point sampling or sometimes farthest point sampling a few times in deep learning papers dealing with point cloud data. However there is a lack of resources online explaining what this algorithm actually does.
minibatchai.com
Grouping
grouping 단계에서는 샘플링 단계에서 추출한 중심점들과 그 중심점들 각각의 주변의 점들과 그룹으로 묶어줍니다. Grouping에 방법에는 크게 KNN방식과 ball query방식이 있습니다. KNN은 중심점에 대해 가장 가까운 K개의 이웃한 점을 의미합니다. ball query 방식은 정해진 크기의 영역을 만들어 그 영역안에 있는 점들만 그룹핑하는 방법입니다. PointNet에서는 ball query방식을 사용하였습니다.

PointNet
Sampling과 Grouping과정을 거친 점은 pointnet에 통과하게 됩니다. 처음 input의 pointcloud의 크기를 $N \times (3 + C)$라고 notation할 수 있는데, N은 pointcloud점의 개수,3의 3차원, C은 학습을 통해서 알아내야 할 point의 feature입니다. Sampling과 Grouping을 거치면 $N_1 \times K \times (3+C)$로 K개의 그룹으로 표현할 수 있고 PointNet을 통해 학습을 한 결과는 $N_1 \times (3+C_1)$로 K개의 그룹이 각각의 local feature를 학습한 결과로 나타나게 됩니다. 이 과정을 반복하면 마치 CNN이 hierarchy하게 feature를 추출하는 방법과 유사하게 low-level부터 high-level까지 다양한 feature를 뽑아내게 됩니다.(그림1 참고)
Density Adaptive Feature Learning
pointcloud는 위에 언급하였다시피 밀도 가 일정하지 않습니다.(variable density) 이렇게 되면 sparse한 데이터로 학습한 부분과 dense한 데이터로 학습한 부분이 서로 다른 분포의 데이터에서는 좋은 성능을 내기 힘듭니다. 이를 해결하기 위해 일부로 다양한 밀도를 sampling하여 만들어 학습에 사용합니다. 이 방법을 density adaptive layer라고하는데 두가지 방법을 소개합니다.
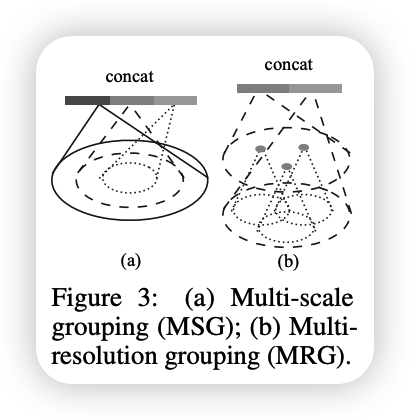
Multi-scale grouping(MSG)
MSG방법은 grouping단계에서 반지름의 크기를 다양하게 적용합니다. 그렇게해서 추출한 feature vector(pointnet output)을 concatenate하여 multi-scale feature를 얻는 방식입니다. 이 방법은 다양한 정보를 같은 점들을 얻을 수 있지만 각각의 grouping마다 pointnet을 적용하여 concat해야하기 때문에 계산량이 많습니다.
Multi-resolution grouping(MRG)
MRG는 논문에서 채택한 방식입니다. MSG에서 계산량이 많은 단점을 보안하기 위한 방법론 입니다. multi-scale을 위해 따로 여러번 grouping을 하는 것이 아니고 Pointnet++에서 set abstraction(sampling+grouping)과정을 을 5번 진행한다고 가정하였을때 1번째 진행하여 얻을 feature vector부터 5번째 진행하여 얻은 feature vector까지 concat하여 모든 level의 정보를 활용합니다. multi-scale을 위해 따로 scaling한게 아니니 계산량 측면에서도 MSG보다 더 좋습니다. 마치 skip-connection느낌입니다.
Point Feature Propagation
해당 과정은 segmentation을 위해 존재합니다. set abstraction 과정을 통해 pointcloud의 개수가 줄어들기 때문에 segmentation을 위해서는 원래의 개수로 복원해야합니다. 이를 위해 interpolation을 사용하여 up-sampling을 합니다.
feature vector로 부터의 weight와 down-sampling과정에서의 feature를 skip-connection를 통해 concat하여 interpolation을 하게 됩니다.

마치 CNN과 같이 Local feature를 extraction하기 위해 scale, dense variety문제를 해결한 부분에서 의미가 있다고 생각합니다. 해결하는 과정에서 알고리즘적인 측면으로 이를 해결하였는데 self attention을 이용하여 이 조차 learning based로 처리할 수도 있지 않을까 싶습니다.(아마 논문이 있을겁니다..)이상으로 PointNet++ 리뷰 마치겠습니다.




