안녕하세요. 후니대디입니다.
colmap으로 유명한 SfM revisited 논문을 리뷰해보겠습니다.
review
해당논문은 SfM에 대한 Review가 잘 쓰여있습니다. Review부분을 통해 SfM의 pipeline을 살펴보고 해당논문에서 pipeline의 어떤부분을 개선했는지 보겠습니다.
SfM가 무엇인지에 대한 정의는 아래 포스팅을 통해 확인하시면 됩니다.
[SLAM] 0. SLAM / SfM 이란?
안녕하세요. 후니대디입니다. SLAM 시리즈 첫번째로 SLAM의 개념부터 전체적인 pipeline을 포스팅하겠습니다. 정 의 SLAM은 Simultaneous Localization and Mapping 의 줄임말이고, SfM은 structure from motion의 줄임말
jaehoon-daddy.tistory.com

위의 그림은 SfM의 pipeline의 overview입니다. unordered image들이 input으로 들어오고 correspondence search와 incremental reconstruction과정을 거쳐 pose, map을 output으로 뽑아냅니다.
1. correspondence search
SLAM과 다르게 순서가 없는 input image의 feature를 뽑습니다. 이 부분은 최근에는 딥러닝이 잘하는 부분이라서 superpoint등과 같이 딥러닝을 사용하기도 합니다. hand craft로는 SIFT, ORB등이 있습니다. 해당 방법은 keypoint( edge와 같은 특징점)과 description( 해당 keypoint을 구별할 수 있는 id와 같음)으로 구성되어있습니다.
다양한 방법으로 feature extraction후에 matching 단계를 거칩니다. 가장 간단한 방법으로는 naive atching방법으로 모든 feature 쌍을 찾아서 가장 오버랩이 많은 image들을 pair로 하는 방법입니다. reference로 다양한 robust방법들을 제시합니다. 개인적으로는 아래의 superglue를 한번 읽어보시길 추천합니다. (self attention을 활용한 matching method입니다)
마지막으로 geometric verification으로 위 matching단계에서 뽑은 image pair를 geometric 방법을 통해 검증하는 단계입니다. 방법론으로 논문에서는 Homography, Epipolar geometry(Essential matrix, Fundamental matrix), trifocal tensor 그리고 RANSAC입니다. (Ransac은 outlier 제거용으로 전자의 것들과 성격이 다릅니다.). 이와 같은 방법론을 통해 matching단계에서 뽑은 pair set 중에 inlier들을 추려줍니다.
feature extraction, match, geometric verification 을 통해 scene graph를 만드는 것이 correspondence search단계의 최종 목적입니다. image를 node로 검증된 pairs들을 edge로 한 graph를 최종적으로 만들어냅니다.
2. Incremental Reconstruction
scene graph를 이용하여 점진적으로 reconstruction을 해 나아갑니다. scene graph에서 적절하게 initialization할 pair image를 선택합니다. 보통 location정보가 많은 pair를 선택하는 것이 robust하다고 합니다. Initialization하는 방법은 해당 논문에는 구체적으로 나오지 않았지만 보통 Epipolar geometry를 통해 Essential matrix를 구해 두 scene의 projection matrices를 얻게됩니다. 두개의 projection matrices와 2D points(matched feature)를 알고있기때문에 triangulation을 통해 3D point를 recon할 수 있습니다.
이렇게 하면 initialization과정이 끝나게 됩니다. 이 후에는 Image Registration이라고 표현되어 있는데, scene graph를 통해 다음 edge에 연결된 image pair를 가지고 옵니다. Perspective-n-Point(PnP) : 3D-2D 방법을 통해 map에 있는 3D point와 그에 매칭되는 새로 가지고온 image에서의 2D point를 통해 새로운 images의 pose를 estimation합니다. 이 후 다시 새로운 images의 pose를 이용해 triangulation을 거쳐 3D point을 복원할 수 있습니다. 해당과정을 어느정도 진행후 Bundle Adjustment을 합니다.
BA는 Reconstruction한 3D points와 pose를 reprojection후에 error를 minimizing하는 최적화로 Levenberg-Marquardt 방법을 보통 사용합니다.


여기까지의 SfM의 일반적인 pipeline입니다. 이 pipeline 과정에서 해당논문에서 contribution한 부분을 살펴보겠습니다.
Scene Graph Augmentation
corresponding search에서 scene graph를 만들때 몇가지 방법들을 추가로 사용합니다. 우선 fundamental matrix를 추정하여 Nf이상의 inlier를 발견하면 verified image pair로 간주합니다. 다음으로 homography inlier개수를 구해 Nh로 정의합니다. 또한 essential matrix를 추정하여 inlier개의 Ne를 구합니다. 이 3가지의 값을 이용해 classify합니다. Nh/Nf가 일정 threshold보다 작으면 해당 pair는 moving camera로 간주합니다.(즉, pure rotation이 아니라고 간주합니다.) 또한 Ne/Nf가 일정 threshold보다 크면 correct calibration으로 간주합니다. 논문에서는 이 과정을 통해 WTFs을 scene graph에 추가되는 걸 막을 수 있고, Non-panoramic 하고 calibrated image pair를 scene graph로 추가할 수 있다고 말합니다.
Next Best View Selection
image registration단계에서 best view를 뽑는 방법을 제시합니다. bad view를 selection하게 되면 triangulation단계에서 reconstration error가 많이 나타나기 때문입니다.
보통의 방법은 3D points (triangulated points)가 많이 보이는 혹은 매칭될 수 있는 view를 선택합니다. 하지만 논문에서는 매칭될 수 있는 point의 개수도 중요하지만 point들의 distribution 또한 중요한 인자라고 합니다. 2가지 visible points 개수와 얼마나 uniform 하게 분포되어 있는지를 score를 매겨 선택합니다. 아래 그림을 참고하면 이해가 빠릅니다.
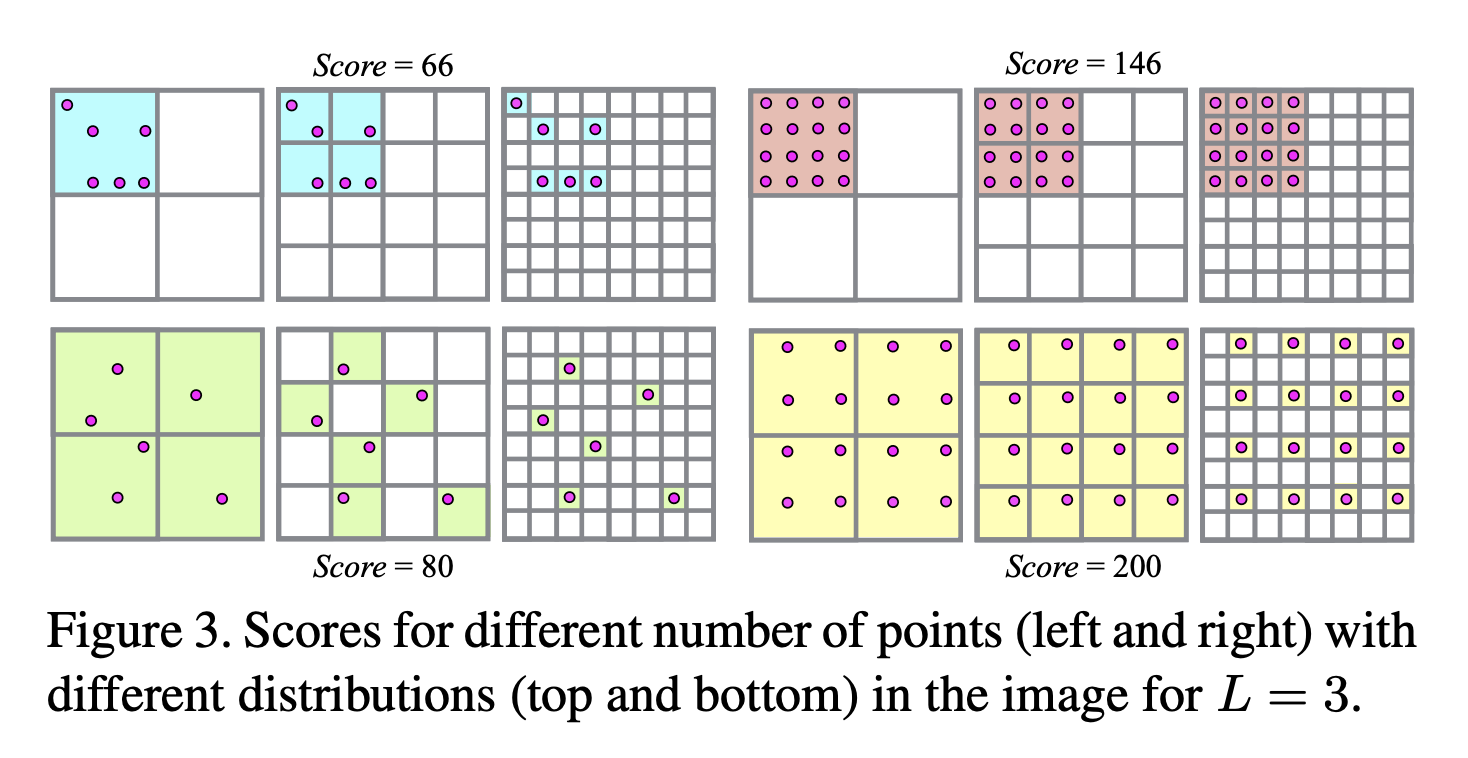
Robust and Efficient Triangulation
해당논문에서는 sampling-based triangulation방법을 제시합니다. tracking과정에서 쌓인 error들에 robust하기 위해 우선 RANSAC을 활용합니다. 자세한 방법은 아래 설명합니다.
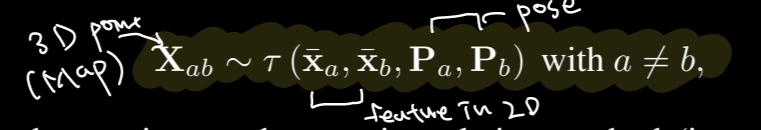
위의 그림은 triangulation eq입니다. 두 개의 constraints를 적용합니다.
1. 충분한 각도의 triangulation 각도를 사용합니다.
2. positive depth를 사용합니다.
triangulation과정 후 reprojection error를 구하고 error threshold보다 작으면,random sampling을 통해 feature set를 선택하고 K번의 iteration을 거쳐 Ransac을 지속하여 best 3D point를 구합니다.tracking과정에서의 outlier의 2D point들이 쌓일 수 있기 때문입니다.
Bundle Adjustment
BA과정은 보통 local과정과 global과정으로 분류됩니다. 본 논문도 마찬가지로 local과정과 global과정으로 구분했습니다. local BA는 scene graph에서 가까운 image들로 BA를 진행하고 특정 percentage마다 global BA를 진행합니다. 구체적으로는 아래 4단계로 표현할 수 있습니다.
1. parameterization : sparse direct solver로 ceres solver를 이용합니다.
2. filtering : large reprojection error와 minimum triangulation angle을 활용하여 threshold 이상인 image는 model에 입력되지않고 filtering됩니다.
3. Re-Triangulation : visualSfM에서와 비슷하게 re-triangulation(RT)을 사용합니다. BA 과정 전후에 Triangulation step을 추가합니다.
4. Iterative Refinement : 위의 과정(BA, RT, filtering) 을 반복합니다. Threshold는 adative하게 바뀝니다.
Redundant View Mining
BA과정에서 특히 global BA과정이 보통 SfM, SLAM에서 bottleneck부분입니다. 해당 논문에서는 Redundant image들 처리해서 효율적인 BA parameterization을 구성합니다.
submap을 이용합니다. scene graph에서 비슷한 것(오버랩이 많은 것)들을 grouping합니다. global BA를 진행할때는 group을 하나의 camera로 collapsion시킵니다. local BA는 그룹내에서진행하고 global BA는 group을 single camera화하여 BA진행함으로서 bottleneck을 해결합니다.
grouping방법은 N개의 scene마다의 feature 포인트를 binary vector화하고 아래 bitwise 계산을 통해 두 scene의 상호연관성을 계산 합니다. (Vab 값이 클수록 상호연관성이 크다고 판단). 그 후 일정 threshold이상인 것들을 하나의 group으로 활용합니다.
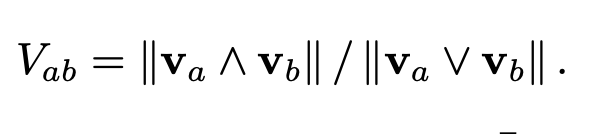
Experiments
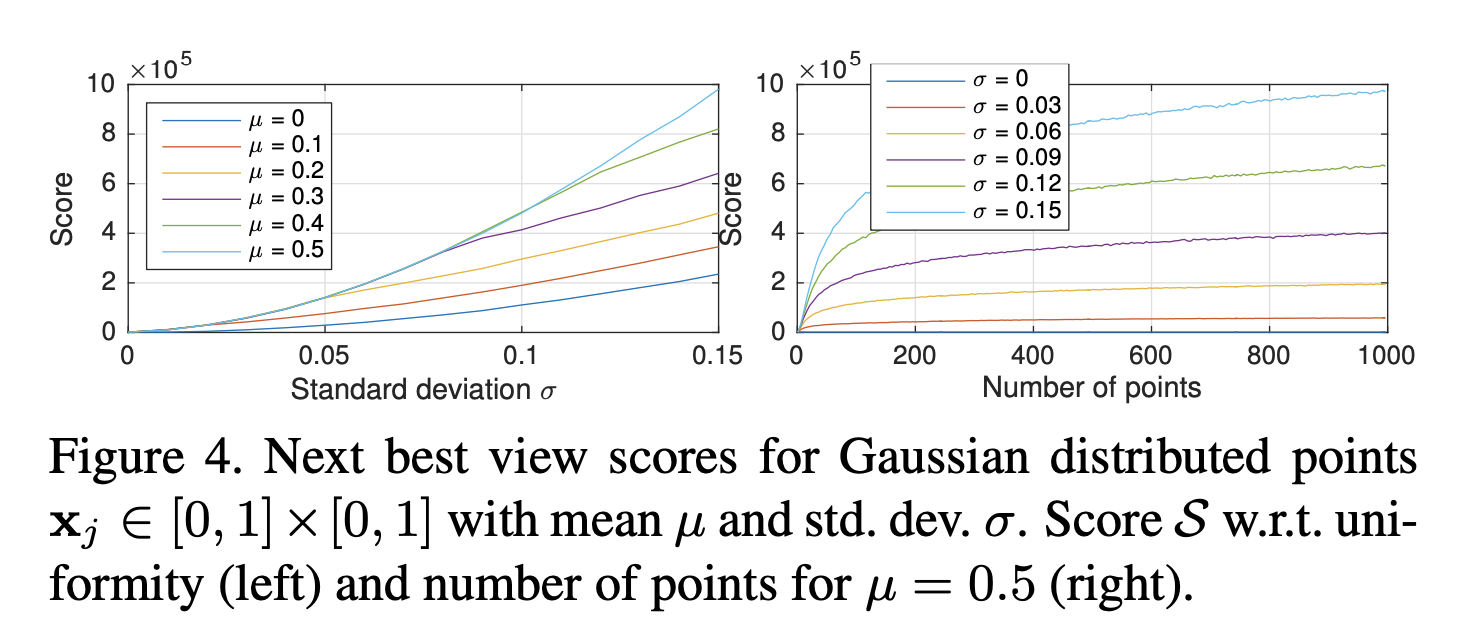
image registration과정에서 image를 selection할때 score점수가 corresponding개수와 distribution을 얼마나 잘 반영하는지 보여줍니다.
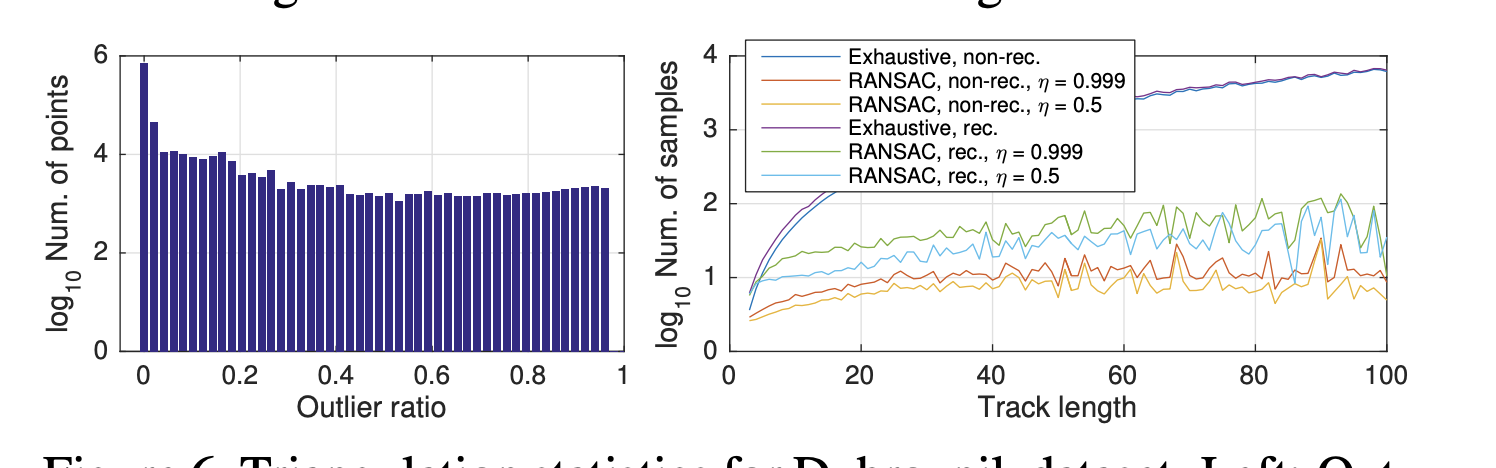
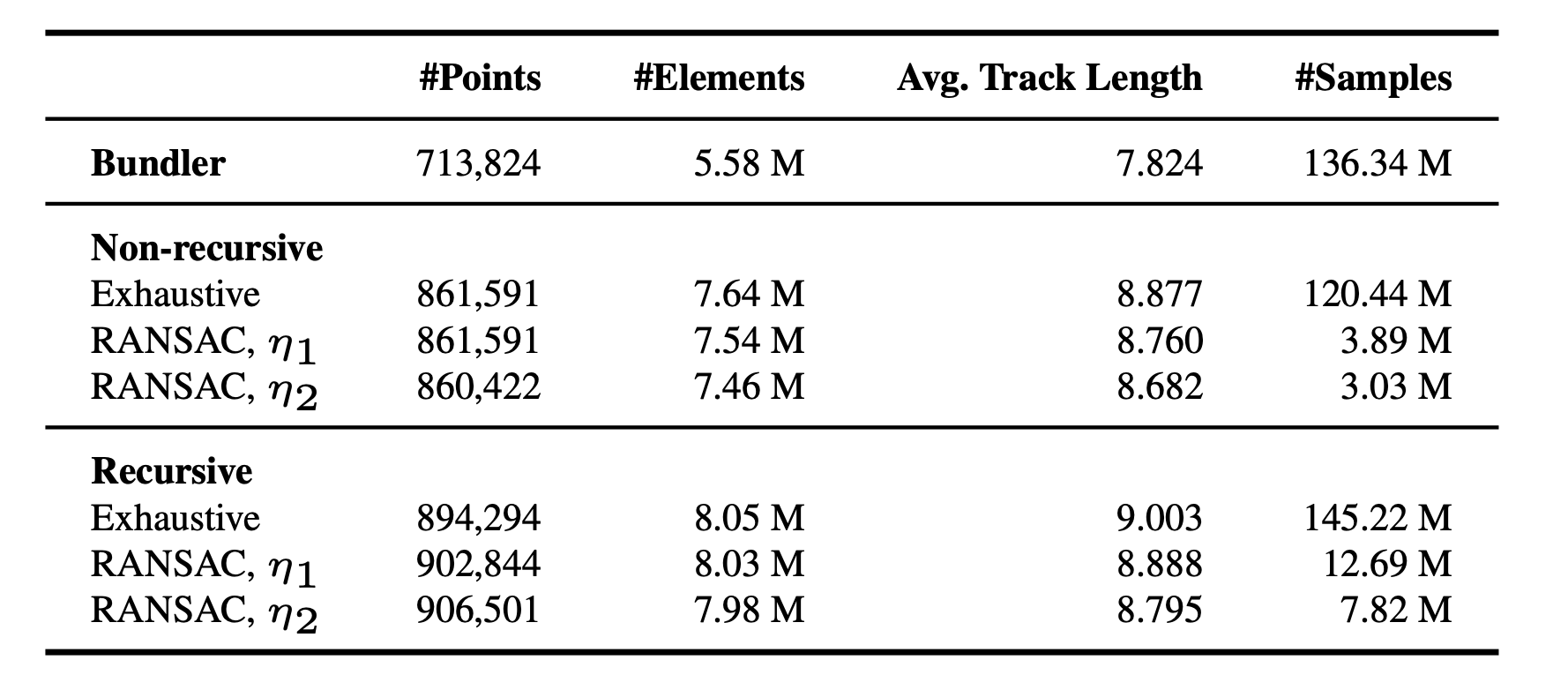
recursive방법이 tracking 전 구간에서 더 많은 points를 뽑아냅니다.
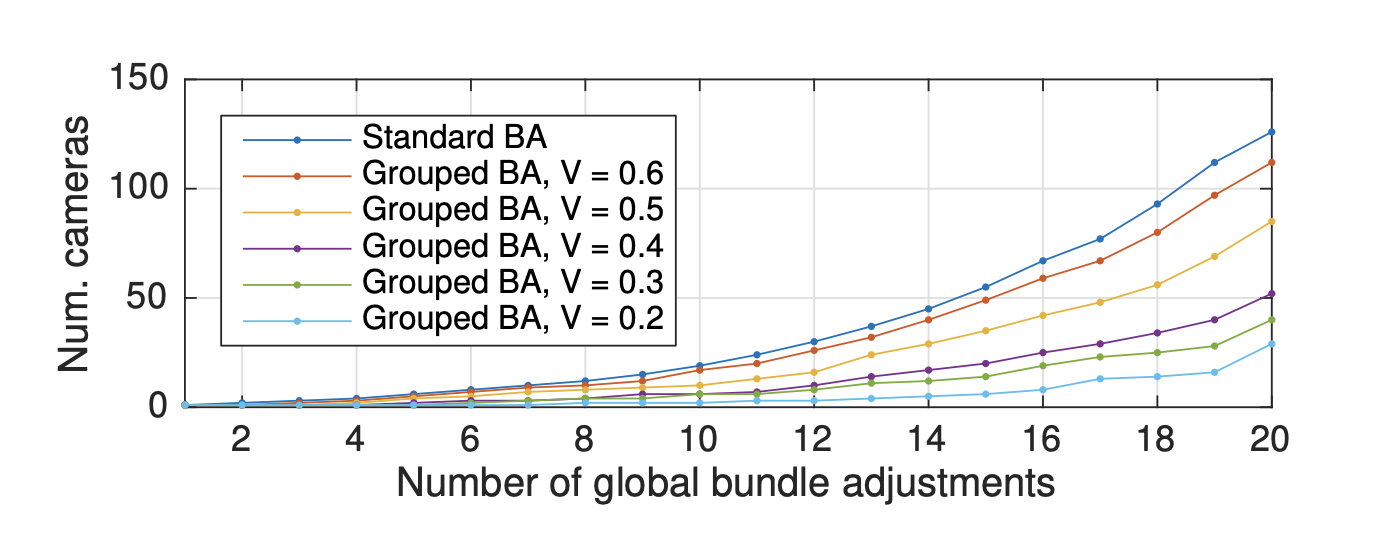
global BA할때 필요한 camera의 개수를 나타내고 V(overlap)비율에 따라 global BA에 걸리는 시간을 줄일 수 있습니다,.
conclusion
colmap은 SfM opensource로 가장 유명하고 많은 research에서도 활용되는 application입니다. colmap은 해당 논문을 base로 하여 개발된 알고리즘입니다. 개인적으로 본 논문을 통해 전반적인 SfM의 pipeline을 한 눈에 볼 수 있다는 것이 장점인 것 같습니다. 또 많은 부분들이 휴리스틱하여 colmap이 완성도를 높이기까지 많은 노가다(?)가 필요했겠다는 생각이듭니다. 완벽한 이해를 위해서는 세부내용들 BA, PnP, Triangulation, Epipolar Geometry를 선행으로 공부해야합니다.
해당 영상을 마지막으로 마치겠습니다 :)




