안녕하세요. 후니대디입니다.
이번에는 pixelNeRF라는 논문을 리뷰해 보겠습니다.
시작하기 전에 해당 논문의 원활한 이해를 위해서는 NeRF의 논문을 먼저 이해할 필요가 있습니다.
이를 위해 이전에 포스팅한 글을 참고하시면 좋을 것 같습니다 :)
[paper review] NeRF 논문 리뷰
최근 synthetic data들의 중요성이 대두되고 있습니다. simulation, generative model 등 여러 방법이 있지만 여기서는 NeRF를 짧게 분석해보겠습니다. 정 의 NeRF는 Novel View Synthesis 계열의 기술입니다. NVS..
jaehoon-daddy.tistory.com
NeRF Limitation
본격적으로 시작하기 전에 우선 NeRF의 한계점에 대해 이야기하겠습니다. Novel View분야에 센세이션을 일으킨 NeRF이지만 (사실 Idea 자체는 기존에 있던 것들이 많지만..) 많은 한계점을 가지고 있습니다.
- 많은 input image를 필요로 한다.
- 각 view마다 (즉, input image 마다) 독립적으로 학습하기 때문에, view마다의 prior knowledge의 공유가 힘들다.
이외에도 많은 한계점이 있지만, 우선 pixelNeRF는 위의 2개를 어느 정도 해결하지 않았나 싶습니다.
Single-Image pixelNeRF
pixelNeRF는 하나의 이미지로 novel view를 렌더링 하는 방식을 먼저 설명합니다.

위의 그림은 pixelNeRF의 전체적인 아키텍처입니다. CNN Encoder 부분, W(pi*x)부분을 제외하면 사실상 기존의 NeRF와 동일합니다.
첫 번째 특징인 CNN Encoder부터 살펴보겠습니다.


pixelNeRF는 input image를 CNN encoder를 통해 feature grid로 만듭니다. CNN encoder는 resnet을 백본으로 하여 4개의 feature map을 만듭니다.(위의 그림에서 dimension을 알 수 있습니다.). bilinear upsampling방법을 통해 각각을 H/2 X W/2 resolution으로 만들고 concat 하여 최종적으로는 512 X H/2 X W/2로 만듭니다.
이후에는 target view에서 nerf에서와 마찬가지의 방법으로 ray를 쏘고 sampling을 통하여 points를 선택하여 point들의 위치와 direction을 input으로 MLP에 넣는 것은 동일합니다.
두 번째 특징으로는 샘플링된 points를 view space(input space)의 feature grid에 projection 합니다. points가 sparse 하기 때문에 모든 correspond point를 구할 수 없으므로 없으므로 bilinear interpolation을 하여 feature vector(W(pi(x))를 추출합니다. 이 방법을 통해 prior knowledge를 share 할 수 있습니다. 참고로 NeRF는 object중심의 canonical space를 사용하고 pixelNeRF에서는 input view의 camera space인 view space를 사용하고 있습니다. 실제 공간에서는 canonical space와 같은 절대적인 coordinate이 존재하지 않기 때문에 view space 기준으로 학습을 하면 generalization 하는데 유리하다고 합니다.
이렇게 구한 feature vector를 MLP 모델의 condition으로 넣어서 학습을 진행하고 이후의 방법은 nerf와 동일합니다.
Incorporating Mutiple Views
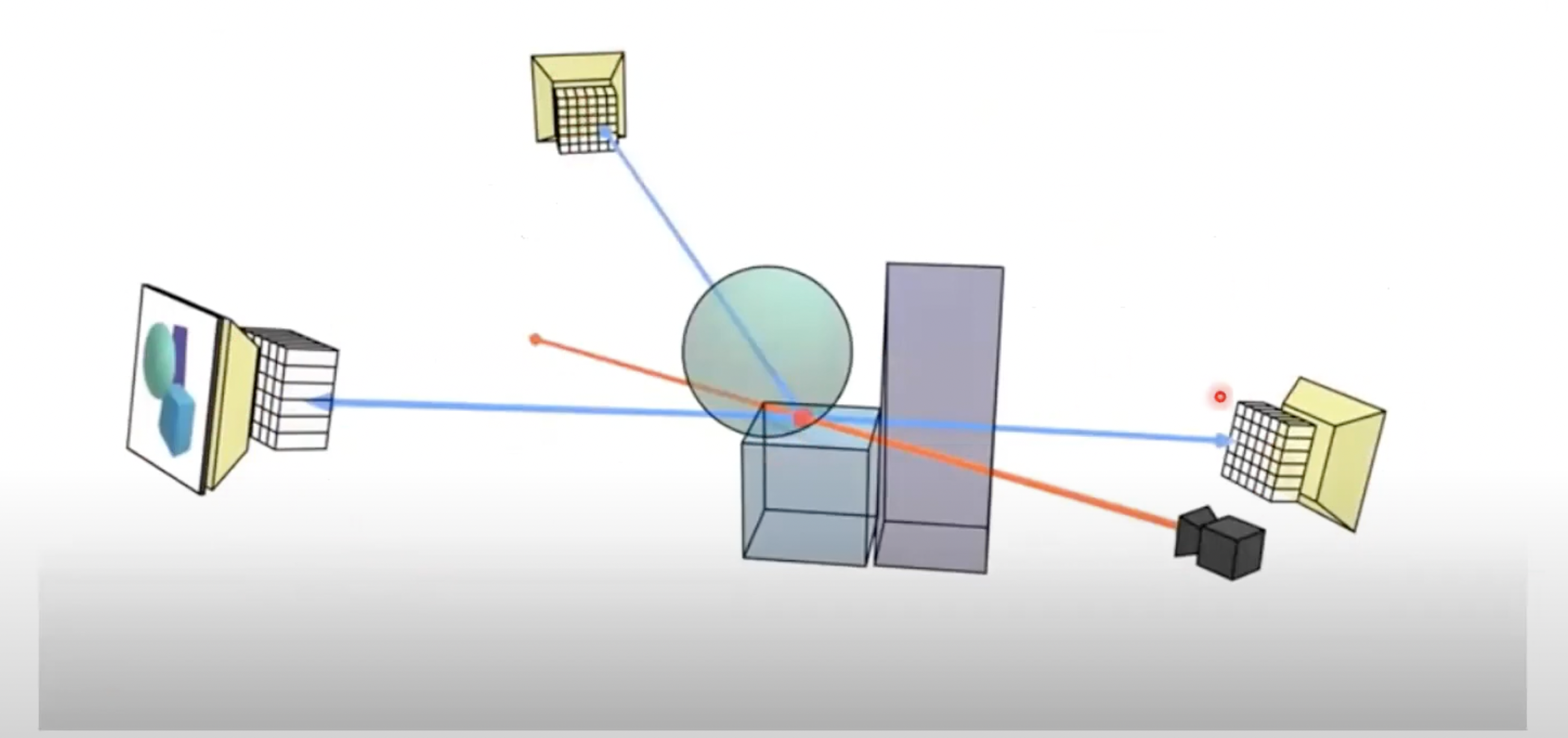
그다음으로 mutiple views에 대한 network입니다. 즉, input image가 여러 장 일 때의 아키텍처입니다. 기본적인 baseline은 single view와 거의 같습니다. 대략적으로 말씀드리면 target view에서 각각의 multiple input view에 single view와 같은 network을 만든 후 적절하게 aggregation 한다고 생각하시면 됩니다.

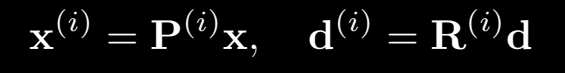
단계별로 구체적으로 알아보겠습니다. 우선 n개의 input image가 있다고 하였을 때 world coordinate을 어떻게 잡든 각각 view space(input image)와의 상대적인 좌표(R|T)는 알고 있어야 합니다. 그래서 위의 식은 P라는 상대적인 translation과 rotation을 나타내는 matrix로 각각의 input image의 view space를 표현한 식입니다.
그다음 target view에 대하여 각각의 input image마다 single image와 같은 과정을 각각의 image마다 해서 총 n번 반복합니다.
여기서 주목할 부분이 있습니다.

각각의 input image에 대해여 single image network와 같은 형태이지만 depth가 1/2인까지인, 위의 그림에서 f1을 n번 반복하는 것입니다.

수식은 위와 같이 쓸 수 있습니다.
이 f1단계의 network를 n번거쳐서 나온 layer를 mean pooling 하여 여기서 f2으로 표현된 network, 즉 single image network기준으로 뒤 쪽 나머지 반의 layer을 통과하여 최종으로 color와 density를 output으로 뽑게 됩니다.
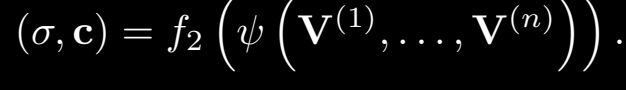
f2과정의 수식은 위와 같습니다.
이후의 학습과정은 nerf, single image network와 동일합니다.
Discussion
experiment는 위의 pixelNeRF의 공식 동영상으로 대체하겠습니다. 꽤 많은 지분을 논문에서 experiment에 채운만큼 확실히 few image 상태에서의 결괏값은 훌륭한 것 같습니다.
그러나 논문에서도 인정하는 optimization time을 줄이는 데에는 생각한 것만큼의 성과를 이루지 못하였고, 개인적으로는 pose, direction을 미리 알아야 하는 상황에서의 실용성은 아직 많이 낮지 않나 싶습니다.
이후에는 해당 shortage를 극복한 nerf에 대해 알아보도록 하겠습니다.
감사합니다




