이번 논문 포스팅은 FORM이라는 모델입니다.
Lidar를 이용한 Odometry estimation 모델은 크게 smoothing method, filtering method로 나눌수있습니다.
smoothing은 과거의 pose구간을 한꺼번의 smoothing하는 방법으로 window 방식으로 optimization을 하는 것을 의미합니다. 그렇기에 새로운 정보를 바탕으로 과거의 상태를 보정할 수 있어 정확하지만 연산량이 많아서 실시간 처리가 불가능합니다. filtering 방법은 연산량 문제를 피하기 위해 현재의 state만 estimation하는 방법을 사용하고 과거의 scan은 submap으로 처리합니다.
보통 filtering방식을 사용하는데 submap은 한 번의 estimation의 오차가 발생해서 잘못 반영되면 그 에러가 영원이 수정이 되지 않는 단점이 있습니다. FORM은 smoothing 기법을 사용하면서도 실시간 처리 속도를 유지하는 모델입니다.
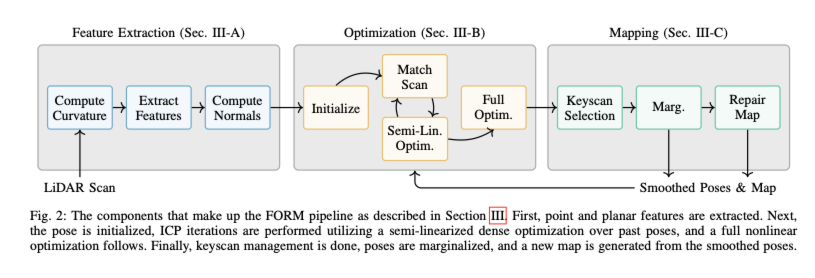
FORM은 크게 세 가지 모듈로 돌아갑니다. Feture Extraction, Optimization, Mapping부분입니다.
Feature Extraction
noise제거 부분인데 scan line의 가장자리에 묻혀있는 점들과 그 주변의 점들을 모두 invalid로 처리합니다. LOAM 알고리즘과 달리 edge 특징점을 안 뽑기 때문에 occlusion을 체크하는 복잡한 연산은 생략해서 속도를 높였고 살아남은 유효한 점 pi가 얼마나 평평한지 않기위해 curvature를 계산합니다.

lidar scan line을 여러 구역으로 나눈뒤에 각 구역에서 위 수식으로 구한 곡률이 임계값 보다 작으면서 가장 평평한 점들을 평면 특징점으로 뽑아냅니다.

이 후에 이 평면이 어느 쪽을 바라보고 있는지 normal vector를 알아냅니다. 특징점 f 주변 반경내에 있는 점들을 모아서 위 수식처럼 convariance matrix를 구하고 이 행렬에서 가장 작은 eigenvector를 추출하면 평면의 수직 방향인 norm vector가 됩니다.

추가적으로 도심처럼 건물이 많은 곳은 평면 특징점만으로 충분하지만 숲속이나 복잡한 오프로드같은 unstructured 환경에서도 robust하기 위해서 plane feature가 없는 구역을 골라서 point feature을 추가로 추출합니다. 위의 사진이 파란색은 plane feature 주황색이 point feature가 됩니다.
Optimization
최적화부분이 이 논문의 핵심적인 부분입니다.
최적화를 시작하기 전에 ego pose에 대해서 initial guess가 필요한데 직전의 두 pose를 이용해서 constant velocity model을 이용해서 현재 scan pose를 추정합니다. 이후에 ICP를 진행하는데 현재 scan point의 feature point를 map의 과거 scan에서 가장 가까운 점과 correspoding합니다. 이때 distance threshold를 주고 유클리드 거리를 이용합니다. corresponding point를 찾으면 현재 pose와 과거 pose사이의 feature를 추가하는데 이를 통해 densely connected factor graph를 만들게 됩니다.

residual은 위의 수식처럼 plane to point, point to point서로 다르게 계산합니다.
이제 smoothing window(과거 pose들)을 LM 을 통해 최적화하려면 residual과 그것의 Jacobian matrix를 계산해야하는데 이 연산량을 줄이기위해 semi linearized optimization이라는걸 제안합니다. 과거 매칭들은 linearize처리를 하는데 smoothing window안에 있는 과거의 포즈들은 이번 최적화에서 값이 크게 변화하지 안힉에 ICP loop를 시작하기 전에 현재 scan 과 연결되지 않은 matching factor는 모두 linearization합니다. 그리고 잘못된 초기 매칭 때문에 그래프가 망가지는 것을 방지하기 위해 최적화의 시작점은 직전의 반선형화 결과가 아니라 full optimization 결과값을 가져옵니다.
ICP loop 의 마지막은 선형화했던 과거 matching을 모두 풀도 전체 비선형 최적화를 한번만 수행해서 최종 포즈를 확정합니다. 즉 과거의 데이터들은 크게 안 변하니깐 선형화하고 새로 들어온 데이터 매칭에만 연산력을 집중해서 속도와 정확도를 높였습니다.
여기서 의문은 smoothing window를 해서 과거의 pose도 refinement하면서 현재의 pose 정확도를 올리는 것이 이 논문이 지향하는 바가 아닌가? 이럴거면 왜 복잡하게 window optimization을 하는거지? 라고 생각이 드는데 짧은 시간에서 constraint를 단순하게 1차식으로 근사해서 SLAM이라는 요건을 갖추고 마지막에 전체 비선형 최적화를 통해서 선형화하면서의 error를 보상한다고 보면 될 것 같습니다.

동그라미들이 smoothing window 안에 있는 ego의 과거 위치와 현재 위치를 나타냅니다. line과 네모 기호가 특징점들 사이의 contraint factor가 됩니다. 자세히 보면 주황색과 회색 선이 있는데 주황색 선은 맨 오른쪽의 현재 스캔이 과거의 스캔들과 매치된 새로운 팩터들이고 회색은 과거 스캔들끼리 연결된 예전 매칭들입니다. 회색부분은 linearize합니다.
제일 아래 분홍색 네모는 marinalization prior로 너무 오래되거나 불필요해져서 그래프에서 빼버린 과거 위치들의 정보를 압축해서 남겨둔 latent vector같은 것입니다.
Map
연산량을 관리하기위해 과거 어떤데이트를 버릴지 결정하고 smoothing된 완벽한 위치를 바탕으로 지도를 어떻게 repair하는지를 설명합니다. 첫번째로 keyscan selection을 사용합니다.
keyscan selection은 지도가 기하학적 영역을 충분히 덮을 수있도록 유지하는 과정입니다. 항상 최근 스캔들을 N개까지 유지하고 만약 이 개수가 꽉 차면 가장 오래된 최근 스캔 하나를 버릴지 아니면 중요한 keyscan으로 할지 평가하는데 이때 아래 수식을 사용합니다

또 그래프가 무한정 커져서 연산이 느려지는 것을 방지하기위해 marginalization을 실행합니다. keyscan이 최근 N번의 반복 주기 동안 단 한 번도 최근 scan과 매칭되지 않았다면 그래프에서 제외합니다. mapping과정을 통해 smoothing window사이즈를 구한다고 생각됩니다.
Experiments
총 7개의 데이터셋을 사용했습니다. Ouster, Heasi, velodyne 등 다양한 센서를 사용한 데이터들을 모았습니다.
KISS-ICP, GenZ-ICP, MAD-ICP, CT-ICP와 비교하였습니다.


위의 표는 사용한 데이터셋들과 결과입니다.

위쪽 그래프틑 거리별 RTE로 짧은 구간을 보면 파란선인 FORM의 오차가 다른 모델보다 월등이 낮습니다. 작은 window size가 local smoothness를 나타낸다고 말합니다. 아래쪽 그래프는 실제 이동 경로를 확대한 것인데 다른 모델들 submap기반 filtering들은 정답을 따라가지만 jittering, choppy 모습을 나타냅니다.

ablation study결과입니다.


