안녕하세요.
이번 포스팅은 monocular camera 3D detection입니다.
최근 줄여서 mono cam 3D detector들을 조사하고 있는데, 적절한 survey 논문도 없고 해서 간략하게 공부한 바를 기록하게 되었습니다.
기본적으로 3D detection을 위한 센서로는 여러가지가 있을 수 있지만, 보통 Lidar 센서가 많이 사용되고 multi-camera가 사용됩니다. 여러대의 camera를 이용하면 3D 공간의 recognition이 좀 더 쉬워지고 metric 레벨의 depth도 추정이 가능하게 됩니다.
하나의 camera으로는 여러 제약이 존재하는 것이 사실입니다. 특히 depth map을 absolute scale로 예측하는 것이 사실상 불가능하다고 여겨왔습니다.
하지만 최근 depth anything이라는 논문, 모델이 나오면서 depth도 metric 레벨로 foundation model을 만들어 굉장한 성능을 이끌어내는 것을 보고 mono 3d detector들도 tipping point가 오지않을까하여 조사를 시작하였습니다.
sota models

Nuscenes의 경우 mono cam 벤치마크가 존재하지 않아 사실상 모든 모델이 muti-camera(or frame) 모델입니다. 어떻게 multi feature를 잘 fusion하는지가 이슈이고 크게 query base( global scale), BEV methodology가 사용됩니다.

위의 그림은 KITTI360의 벤치마크입니다. Seabird라는 method와 panopticBEV라는 segmentation 모델을 결합한 논문이 SOTA를 찍고 있는데, pure한 detection이라고 하기 애매하고 add one의 성격이 강해 다음 논문으로 DEVIANT, GUPNET을 뽑을 수 있습니다. (BoxNet,VoteNet은 lidar model)
DEVIANT는 seabird와 동일저자의 논문이고 GUPNET은 현재 대부분은 mono3d detector들이 refernece하고 있는 모델입니다.

다음은 waymo인데 KITTI 360이랑 비슷합니다.

마지막으로 KITTI benchmark입니다. 아무래도 KITTI가 mono 3D detection에서는 가장 활발한 업데이트를 보여주는 것 같습니다. 여기에는 보이지 않지만 monoDETR이라는 모델이 github에 쓰여져있는 저자의 eval기준으로는 가장 높은 순위를 보입니다.
아래에서 위의 논문들 중에 몇몇에 대해 간략히 살펴보겠습니다.
위의 벤치마크들은 모두 outdoor dataset입니다. Indoor, outdoor를 unify한 모델들 또한 존재하는데 omni3D(cubercnn), UniMODE 가 대표적입니다.
GUPNet
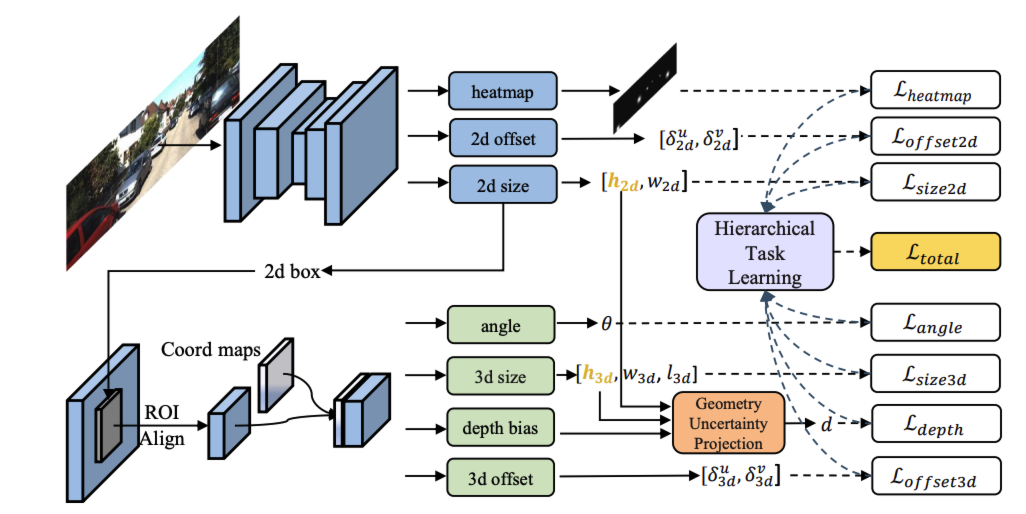
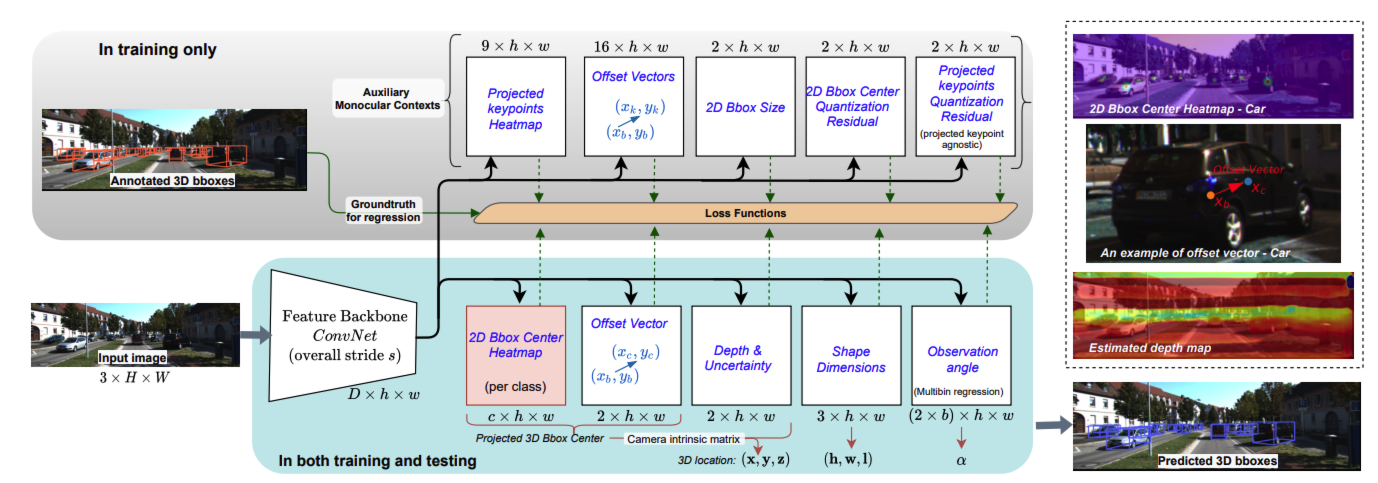
전체적인 overview입니다. 상단부분은 centernet을 백본으로 하여 heatmap, 2D offset(center), 2D size를 prediction합니다. 이후 RoI feature representation 단계에서 RoI를 구하고 Coord map를 concat합니다. coord map normalized coordinate map인데 이 과정은 RoI내 pixel의 좌표값을 정규화한 map입니다. 예를 들어 x좌표는 (0,1)왼쪽에서 오른쪽으로 증가하고 y좌표는 (0,1)로 위에서 아래로 갈수록 증가합니다. 이를 통해 뉴럴넷이 local 정보를 좀 더 explicit하게 활용할 수 있다고 주장합니다.
이 후에 3D detection Head를 거쳐서 4개의 sub-head들을 output으로 나오게됩니다. 3D offset은 2D feature map상에서의 3D bbox중심을 이야기합니다(3d center 에서 projection된 중심점). angle은 camera angle에 상대적인 각도를 의미합니다.
Geometry Uncertainty Projection이 해당 논문에서 자랑하는 부분입니다. depth의 uncertainty를 보정하는 부분인데
우선 object의 3D height을 Laplace distribution으로 가정합니다.
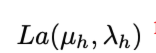
이를 이용해서 height의 loss를 아래와 같이 정의합니다.
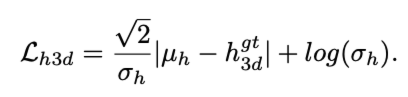
이제 projection을 사용해서 3D height의 distribution으로 부터 depth distribution으로 approximation하고 여기에 depth bias(학습된)를 추가하여 아래의 최종 loss공식을 얻습니다.
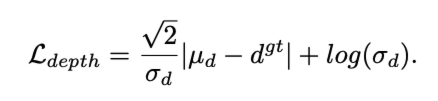
HTL은 논문에서 contribution으로 주장하는 또 하나의 methodology입니다. multi-task learning에서 task간의 Hierarchy를 고려해서 안정적으로 학습하는 방법입니다. 예를 들면 depth estimation은 3D height에 디펜던시가 있습니다. 그렇기에 각 작업의 진행 상황을 모니터링해서 indicator를 만들고 각 작업의 손실 함수에 대한 가중치를 dynamic하게 조절합니다.
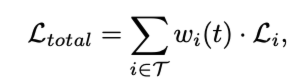
MonoLSS
다음으로 볼 모델은 MonoLSS입니다. 비교적 최근에 나온 모델이고 위의 GUPNet과 매우 흡사합니다. 러프하게 말하면 GUPNet에서 depth uncertainty를 상쇄하기 위한 모듈인 GUP 모듈대신 LSS모듈을 사용했다고 봐도 무방할 정도입니다.
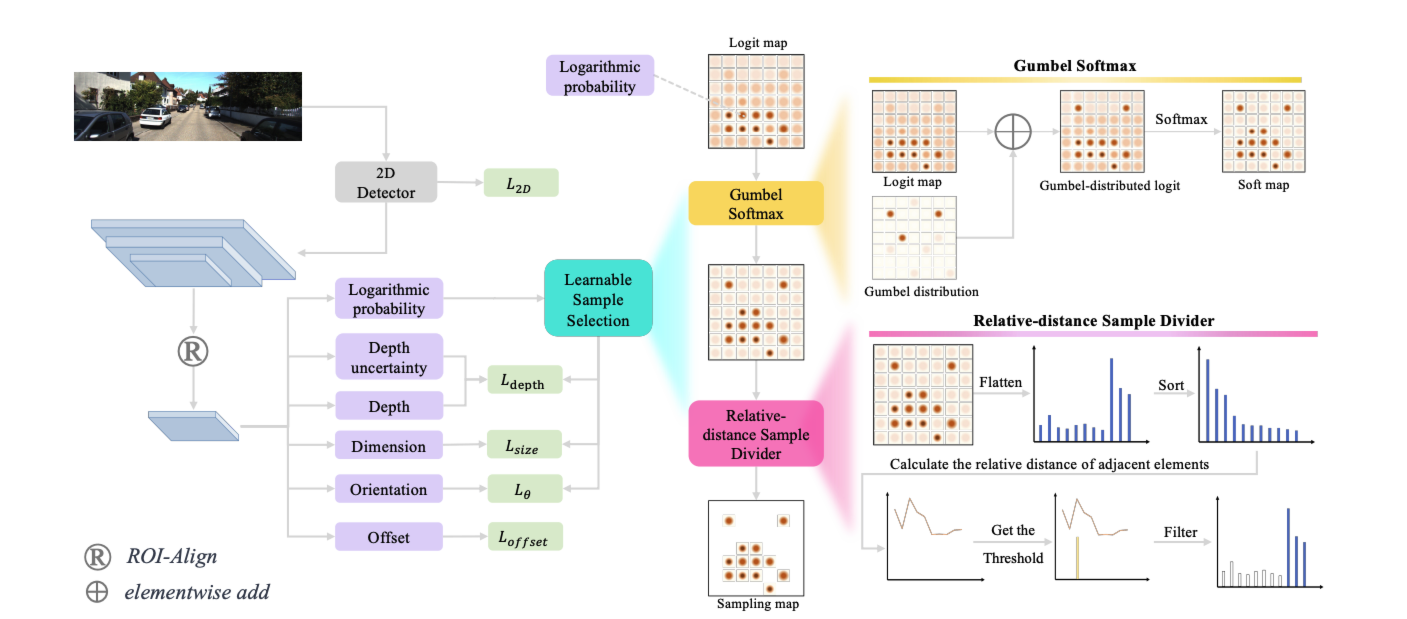
LSS 모듈을 보겠습니다. 저자는 2D feature에서 3D attribution을 예측하기 위해 필요한 feature만 sampling하는 것이 중요하다고 말합니다. 첫번째 테크닉으로 Gumbel softmax를 이용합니다. Gumbel softmax는 sampling을 하고싶은데 backpropagation이 불가능할때 gumbel max 트릭을 이용하여 backpropagation을 할 수 있게 해준다고 합니다. 구체적으로 gumbel에서 argmax와 같은 operator는 미분이 되지 않으니 여기에 softmax를 적용하여 미분가능하도록 만든 operator라고 생각하시면 되겠습니다. 이후에는 relative distance sample divider단계로 넘어가는데 gumbel softmax에서 나온 출력을 1차원 벡터로 변환하고 인접한 요소들간의 상대 거리를 계산하여 positive, negative 영역으로 샘플을 구분합니다. 예를들어 [0.84,0.12,0.04,0]인 softmax값이 있을 경우 relative distance가 가장 큰 값은 0.84/0.12 = 7 이고 7보다 큰 0.84영역만 positive로 구분됩니다. 이렇게 구해진 LSS logit map을 sub-head를 통해 나온 feature map과 곱하여 중요한 feature에 weight를 추가하는 역할을 하게 됩니다.
MonoCON
Omni3D(CubeRCNN)
Omni3D의 경우 이전에 포스팅을 하였으니 간단하게 살펴보겠습니다.
[paper review] omni3D 논문 리뷰
오늘 리뷰할 논문은 omni3D입니다.메타에서 발표한 mono 3D detection 으로 huge dataset을 활용하는 이름하여 zero-shot monocular camera 3D detection입니다. 최근 3D object detection은 크게 두개의 domain으로 나뉩니다
jaehoon-daddy.tistory.com
Omni3D는 사실 여러 데이터셋을 모았다는 표현이고 omni3D를 이용하여 학습한 모델의 이름은 CubeRcnn입니다.
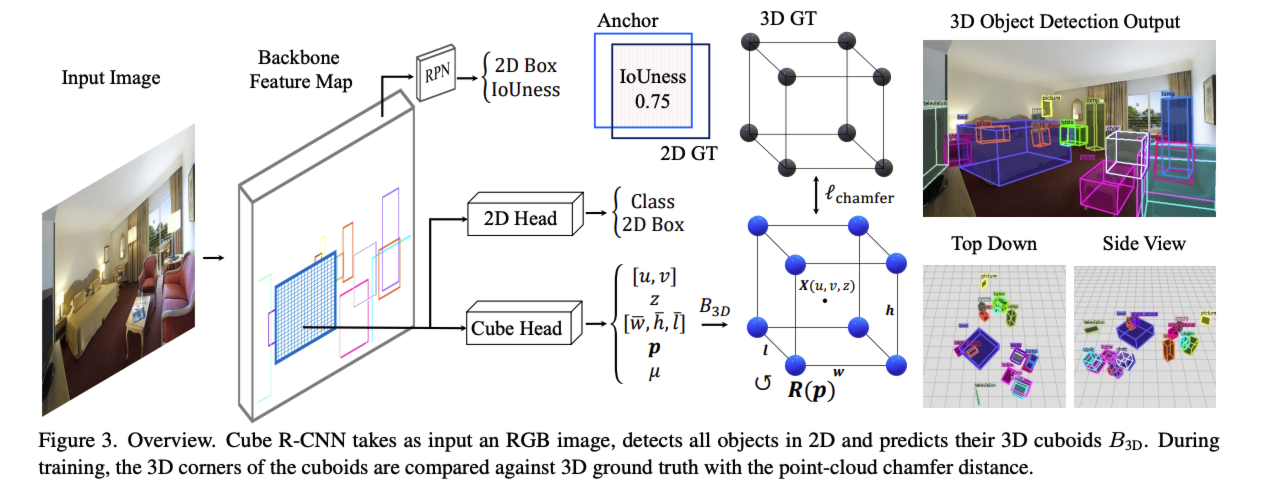
CubeRCNN은 faster RCNN의 2D detector를 baseline으로 합니다.
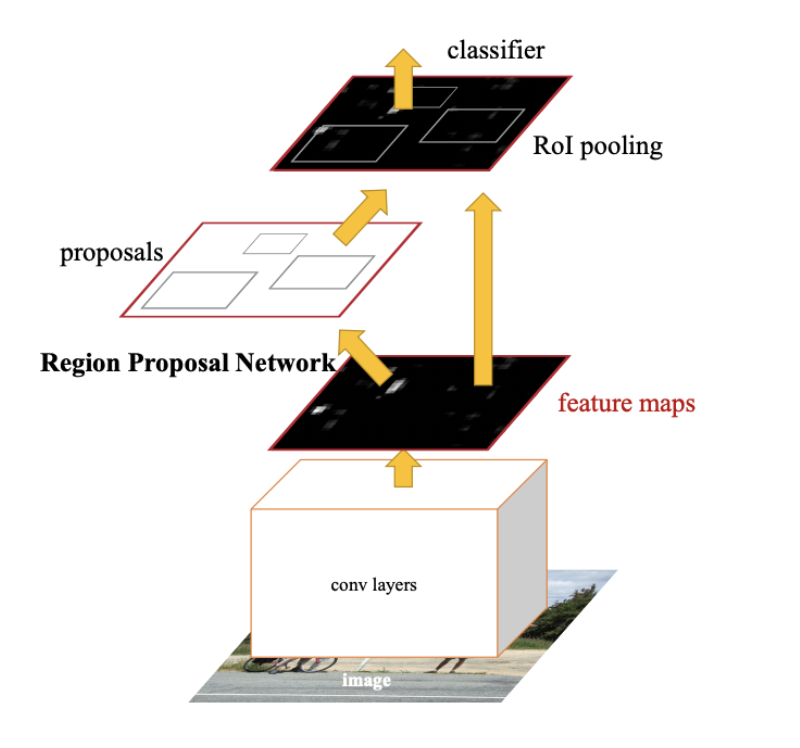
위의 그림과 비교해보면 cubehead부분만 추가되었다고 보면 됩니다. CubeHead에서는 3D 중점에서 projection한 image상의 중점, virtual depth, dimension(log normalized scale), object rotation(6d vector), uncertainty(confidence) 이렇게 총 13개의 파라미터를 구하게 됩니다.
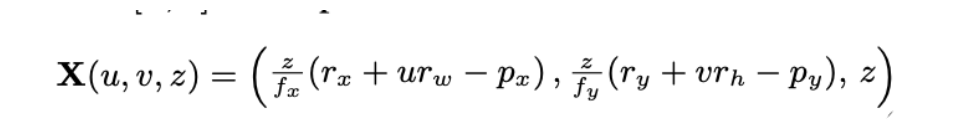
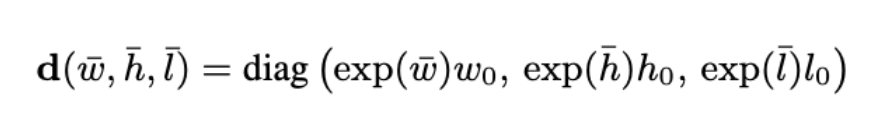
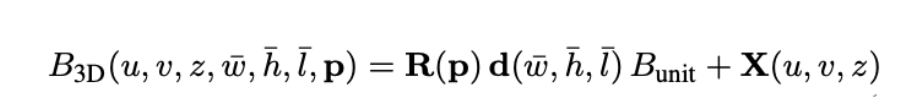
위의 수식은 prediction한 13개의 파라미터를 가지고 inverse projection하는 수식입니다. 이후에 아래 처럼 RPN, 2D, 3D의 loss를 weight sum합니다. 3D loss는 center point부분에 L1, dimension에 L1, rotation에 L1을 사용하고 cuboid의 꼭지점 8개의 GT와 chamfer distance도 loss로 활용합니다. u는 2D와 3D의 weight 조절하는 파라미터 입니다.
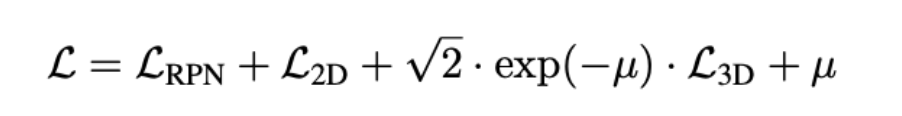
depth를 추정할때 virtual depth개념을 도입합니다. omni3d는 다양한 데이터셋을 활용하기 때문에 데이터셋마다 camera parameter가 다를수 있고 이를 위해 가상의 virtual depth를 도입합니다.
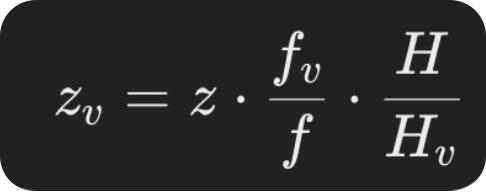
위의 공식을 활용하면 camera parmeter에 상관없이 scale을 통일한 z를 구할수 있습니다.
MonoDETR
마지막으로 MonoDETR에 대해 보겠습니다. 해당 논문은 최근 image 2D detector에서 SoTA를 찍고 있는 DETR을 응용한 모델입니다. 아키텍쳐상으로는 제일 트렌디하다고 볼 수 있습니다.
아래는 이전에 포스팅한 MonoDETR 논문의 상세 설명입니다.
[paper review] MonoDETR : Depth-guided Transformer for Monocular 3D Object Detection 논문 리뷰
안녕하세요. 이번에는 monocular 3D detector인 MonoDETR 이라는 논문에 대해서 리뷰하겠습니다.MMlab으로 유명한 CUHK의 mmlab에서 나온 논문으로 ICCV '23 에 publish되었습니다. 기존의 방법들은 보통 2D detecto
jaehoon-daddy.tistory.com
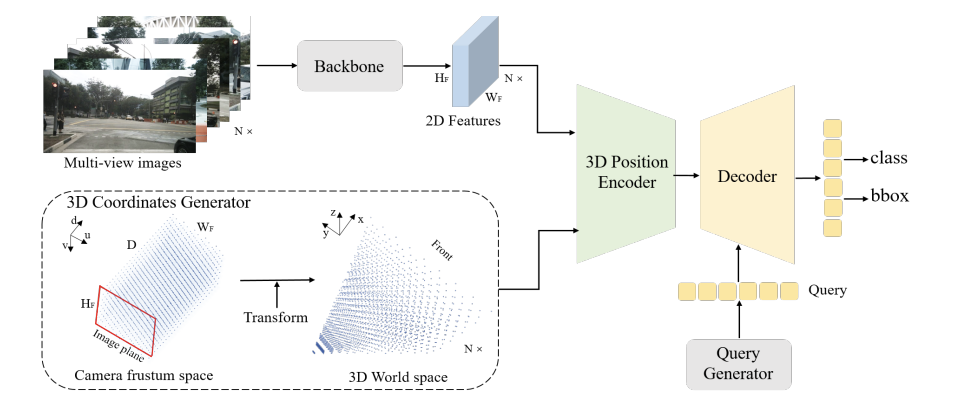
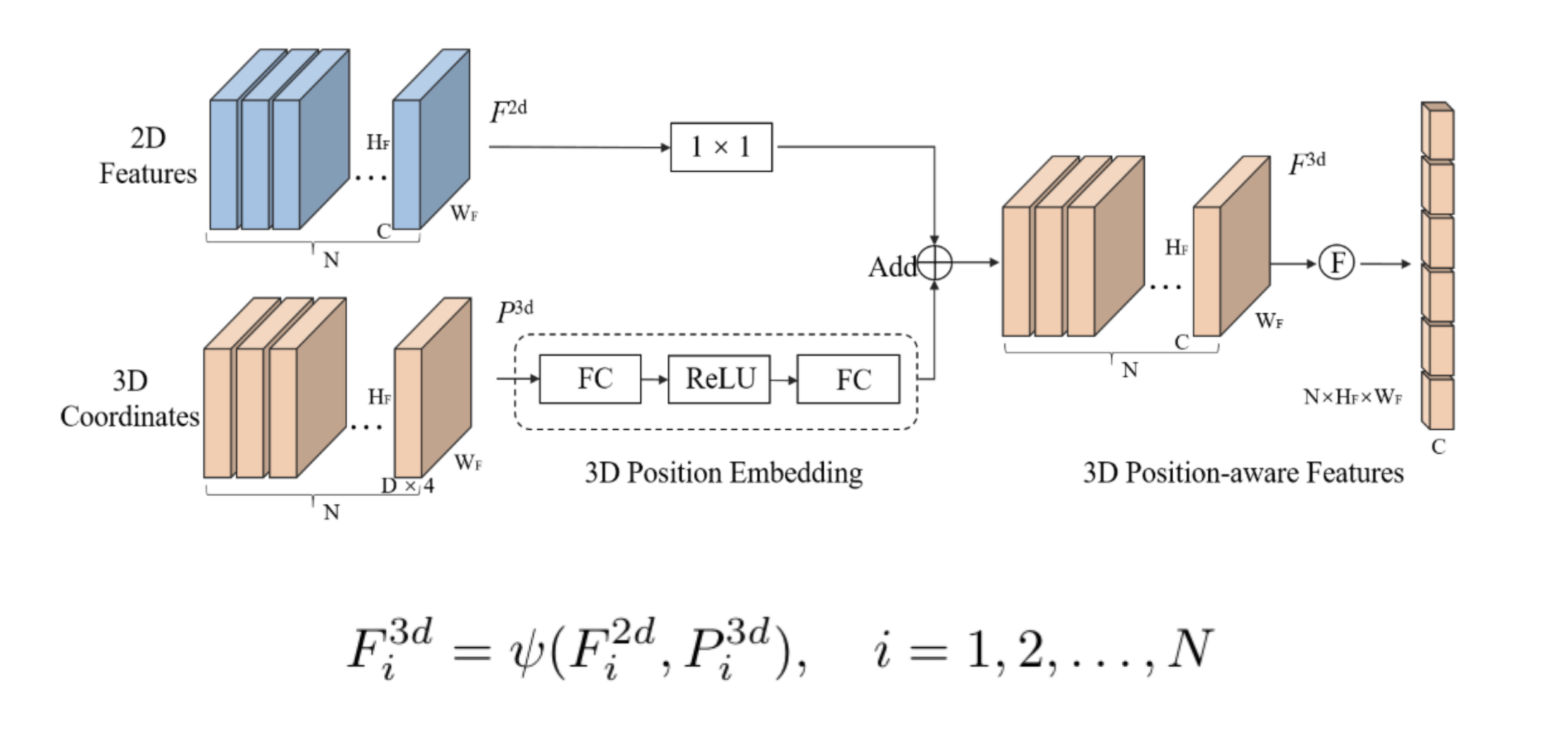
DETR은 기본적으로 query base의 detector입니다. encoder , decoder로 transformer를 사용하고 input으로 query가 사용되는 text 기반의 transformer와 달리 learnable parameter인 query를 사용해서 cross attention을 이용해서 cls, reg을 수행하게됩니다. 각각 query가 object의 cls, reg를 갖고 있기때문에 nms를 사용할 필요없고 hungarian algorithm으로 매칭시킵니다. 이를 3D 공간으로 옮긴 논문에 PETR입니다. nuscenes에서 petr기반의 multi-frame 모델들이 SoTA를 찍고 있습니다.
2D features를 camera, extrinsic parameter를 알고있다는 가정하에 2D feature를 world coordinate로 보내 conv를 태워서 depth map을 구합니다. 이 후에 2D feature와 depth feature를 aggregation해서 3D feature를 완성합니다. world coordinate의 feature map이 될 것이고 여기에 query와 cross attention을 해서 (DETR과 같이) decoder를 통해 prediction을 수행합니다.
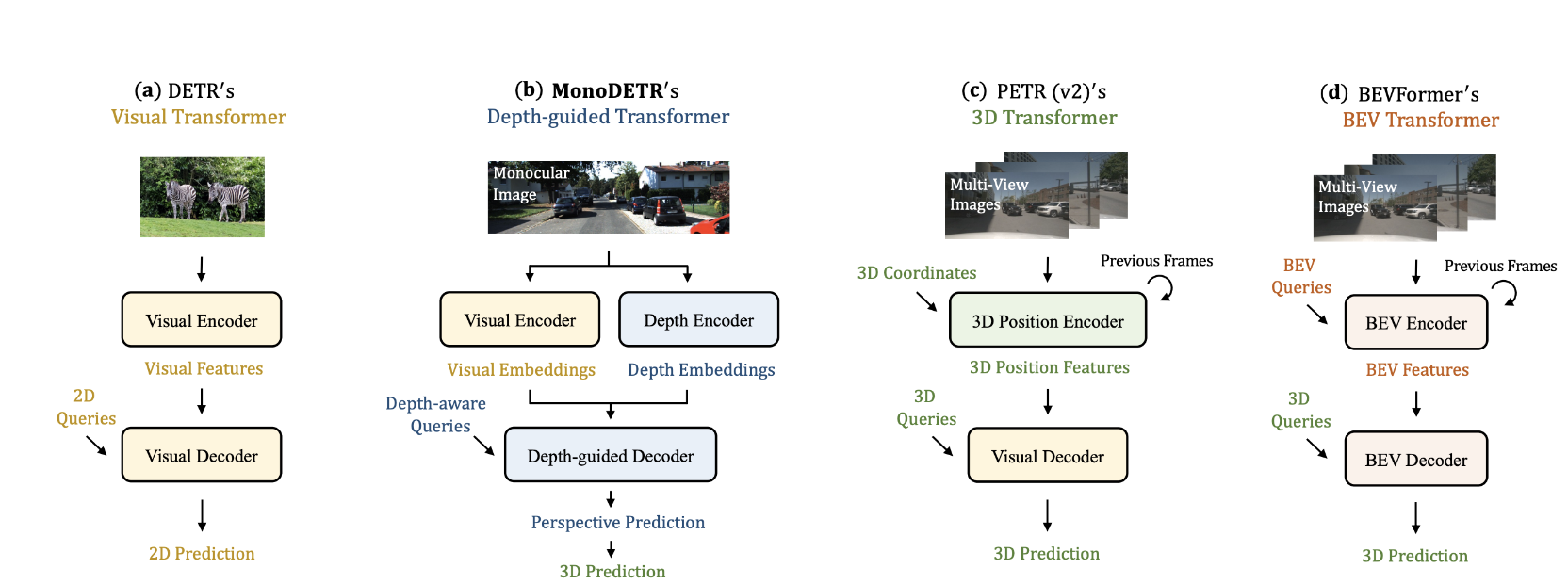
MonoDETR은 mono cam이기때문에 depth guidance가 더 튼튼할 필요가 있습니다.
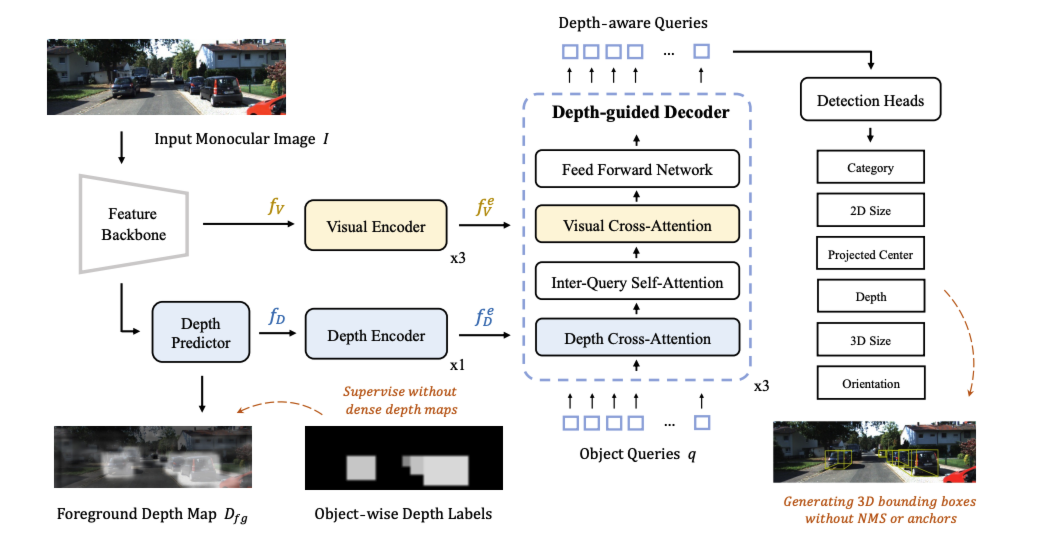
feature 백본에서는 resnet50을 이용해 multi scale feature map을 만들고 (x1/8,x1/16,x1/32) depth predictor에서는 이 multi-scale feature를 unify합니다(x1/16으로 bilinear pooling을 통해 downsizeing하고 element-wise aggregation). 이 후 conv를 거쳐서 최종 $f_{D}$에서는 depth feature map (H/16,W/16,C)를 얻습니다. forground depth map을 보면 사실 depth map을 구할필요가 없고 foreground depth만 알면 됩니다. 해당 부분에서는 1x1 conv를 거쳐 channel을 변경시키고(k+1), 이 foreground depth map은 3D label을 통해 (아마 중점값) 학습할 수 있습니다.
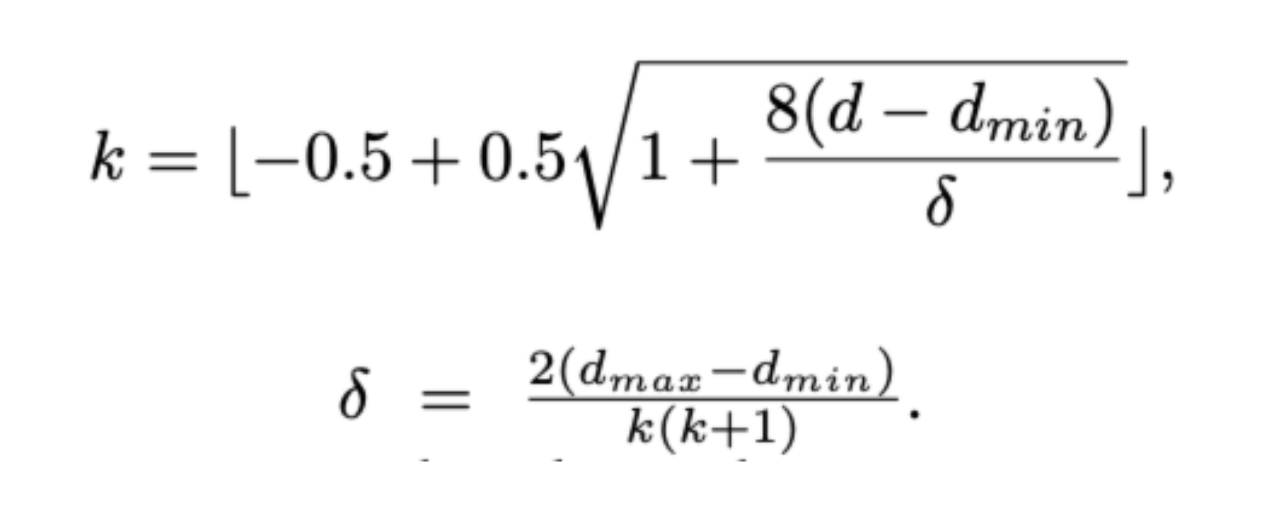
더 구체적으로는 실제 depth range를 k개만큼 나눠서(discretization) 실제 depth label이 몇번째 구간에 위치하는지는 위의 수식을 통해 알아냅니다.
Feature encoding는 3번의 blocks depth encoding은 1번의 block을 거칩니다. 각각의 block은 transformer encoding과정처럼 self-attention과 FFN을 적용합니다. 이후 Decoder과정에서 depth-guide decoder라는 모듈을 거치는데 learnable query N개를 생성한후에 처음으로는 depth cross attention을 통과시킵니다.
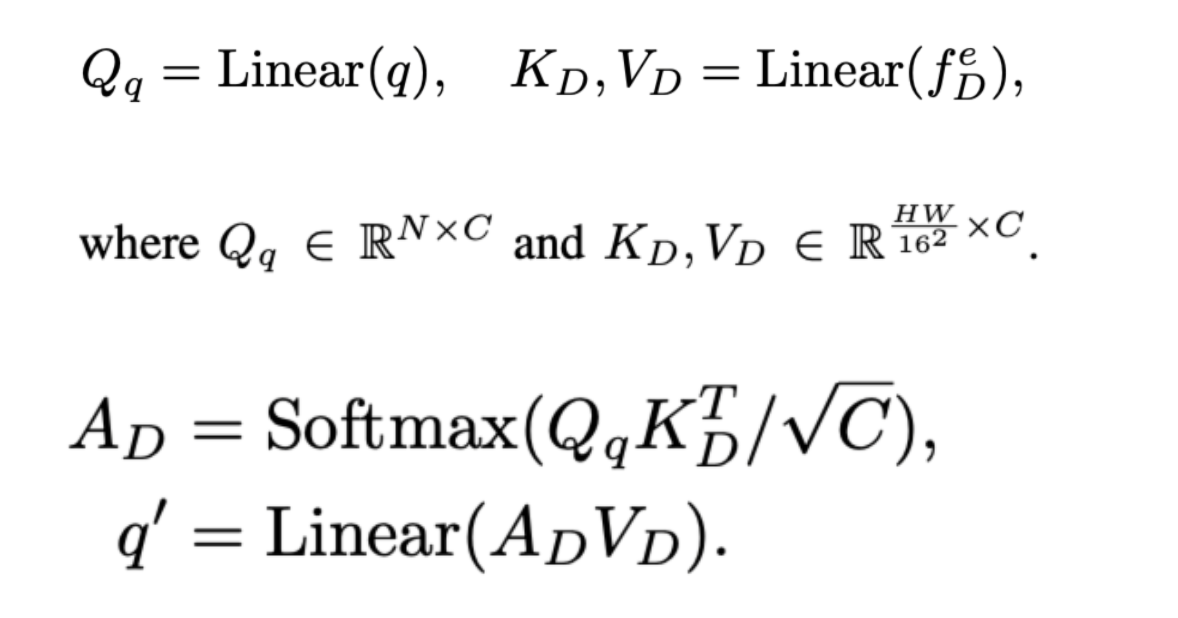
위의 공식은 일반적인 attention equation입니다. 이 후에 query를 self-attention을 수행하고 다시 update된 query와 visual feature map을 cross-attention을 수행하여 마지막으로 FFN을 통해 decoder를 완성시킵니다.
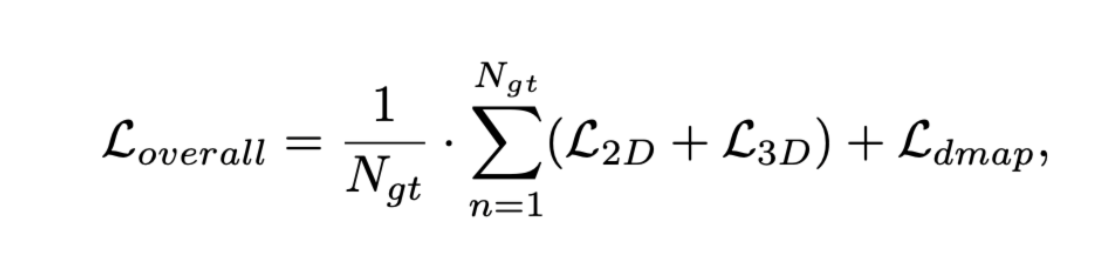
head를 통해 6개의 정보 class,2d size, projected center, depth, 3D size, rotation 으로 나오고 위와 같이 loss를 구성하며 시간에 지남에 따라 L3에 weight를 주는 방식으로 구현한다고 합니다. $L{depth}$는 focal loss를 사용합니다.(k개)
이상으로 mono cam 3D detector에 대해 간략하게 살펴보았습니다



