이번에 포스팅할 논문은 Zero 123++입니다.
123시리즈의 기점 논문인 zero 1 to 3 논문을 뭔저 읽기를 권합니다.
[paper review] zero-1-to-3 : zero-shot one Image to 3D object
안녕하세요. 오늘 포스팅할 논문은 ICCV 2023에 publish된 zero-1-to-3논문입니다. 사전에 dreamfusion논문을 살펴보면 좀 더 도움이 될 것 같습니다. [Paper Review] DreamFusion 논문 리뷰 안녕하세요. 오늘 포스
jaehoon-daddy.tistory.com
Intro
zero123++는 zero123과 마찬가지로 single image로 multi-view image를 생성하는 것을 목표로 합니다. zero123의 diffusion model의 consistency한 multi view를 생성하는 것에 한계점이 있어 이 부분을 개선한 점이 main contribution입니다.
multi-view generation
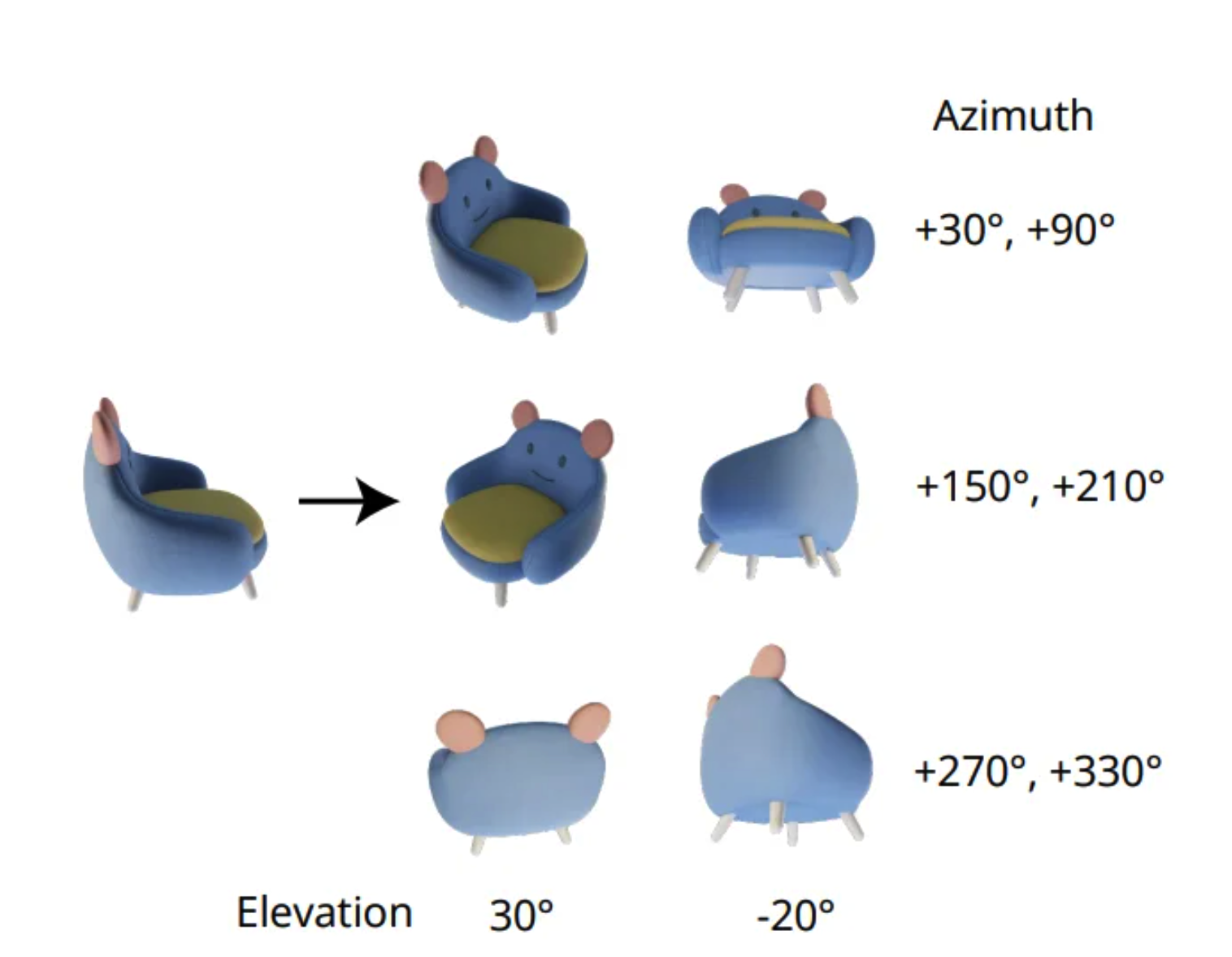
zero 123++에서는 위의 그림처럼 3x2의 레이아웃의 6개의 이미지를 tiling합니다. objaverse dataset의 object의 절대적인 방향이 너무 광범위 하기 때문입니다. 때문에 azimuth(방위각), elevation(고도각)을 고정하여 해당 camera pose에 대해서 diffusion model을 학습합니다.
Consistency
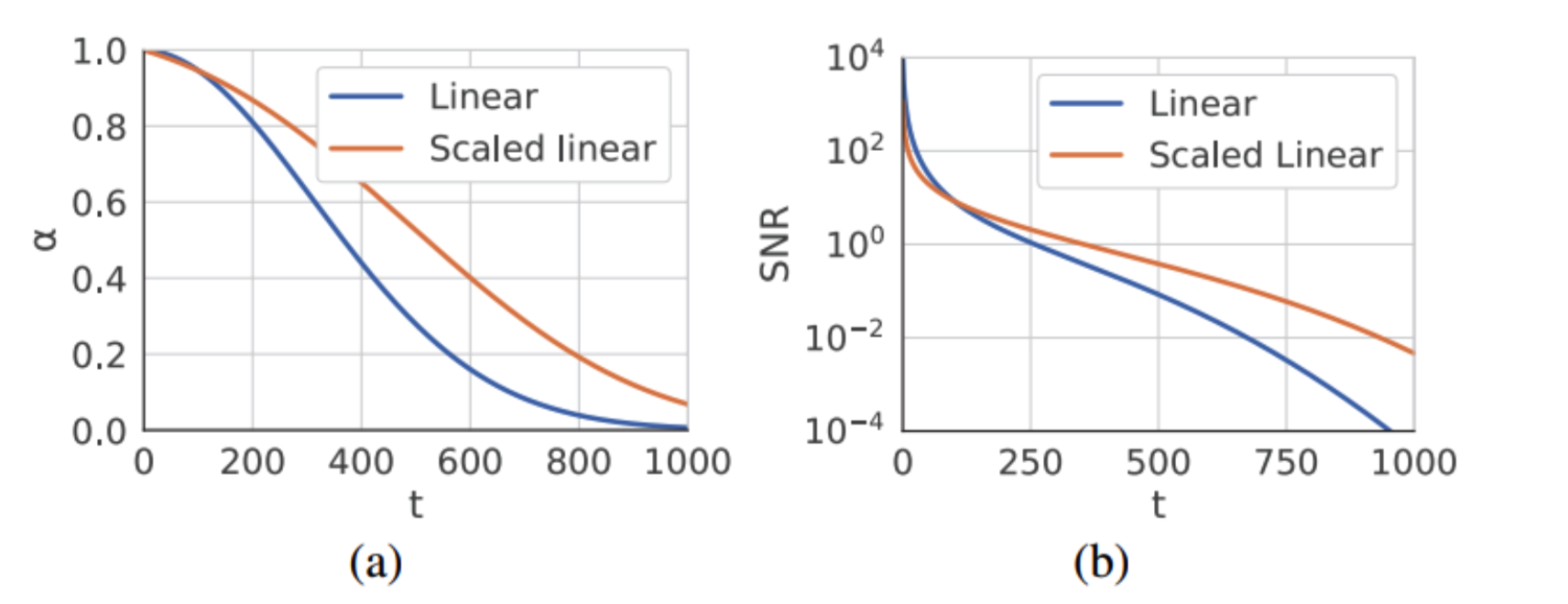
저자들은 noise schedule에 대해 실험을 해본 결과 noise를 scaled-linear schedule을 사용하면 overfitting할 수 없다는 것을 발견하였습니다. 반면에 lineardiffusion model의 noise에서 훨씬 더 overfit하는데 유리하다는 것을 실험을 통해 알아내었습니다.
즉, scaled-linear schedule에서 linear-schedule로 noise schedule을 변환해야하는데 이를 위해 stable diffusion 2 v-prediction 모델을 diffusion model로 설정하였습니다.
Local Condition
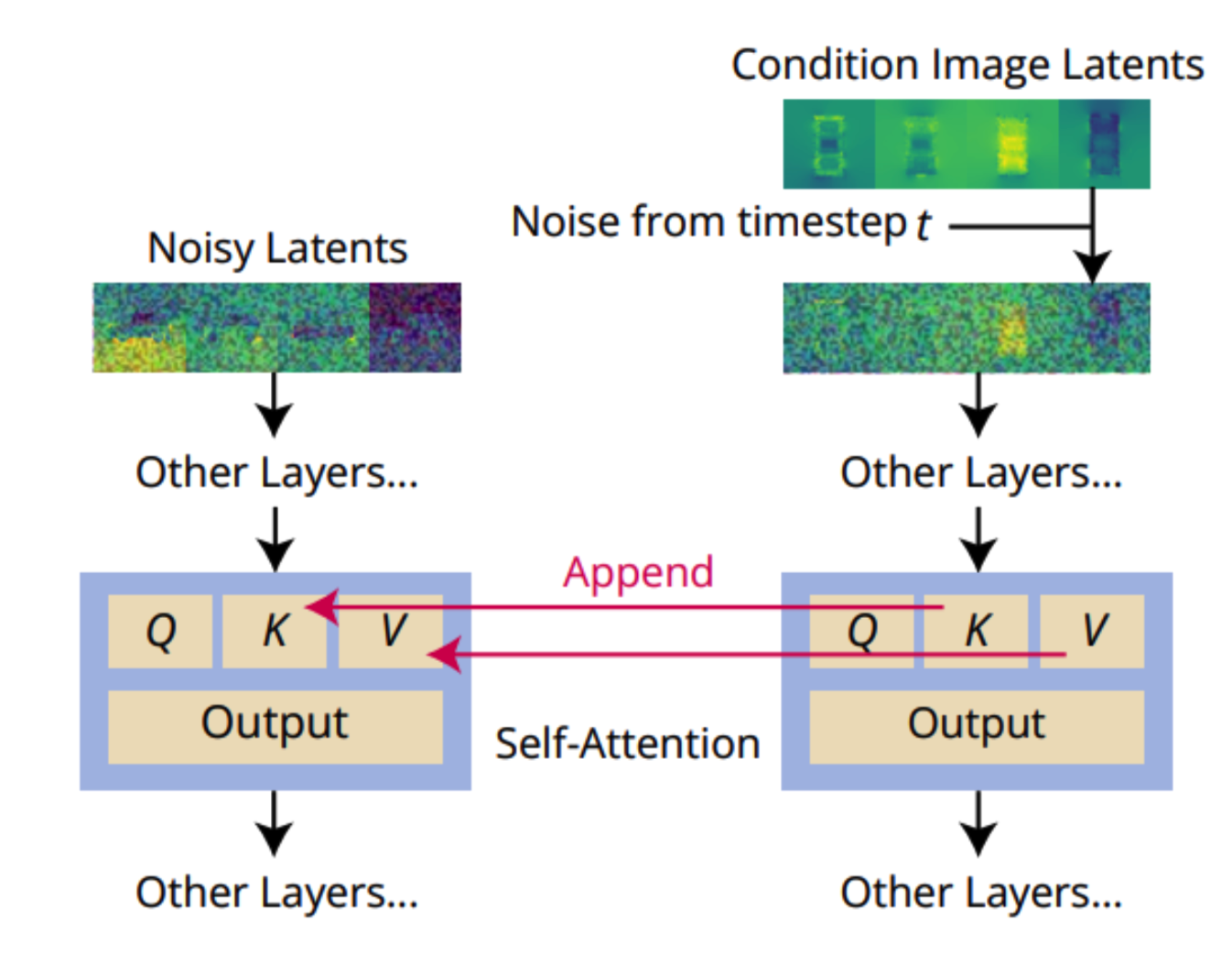
위의 그림은 reference attention으로 reference 추가 reference 이미지에서 denoising detector(U-net)을 통해 denoising할때 refernece image의 self-attention의 key와 value를 input image의 해당 layer의 key, value에 추가합니다. 이를 통해 diffusion model을 guidance 할 수 있어서 reference image와 texture를 공유하여 너무 벗어나지 못하게 bounding하는 역할을 합니다.
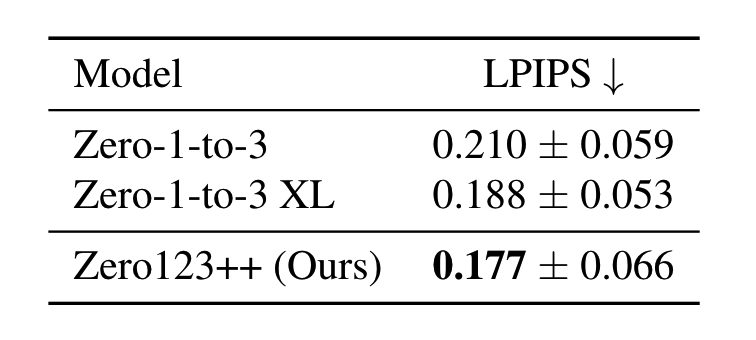
Experiments
zero123와 같이 objaverse dataset을 활용합니다.