안녕하세요 이번에는 PETR 이라는 camera기반의 3D detection 논문을 살펴보겠습니다.
최근 camera를 기반으로하는 3D detection 논문들이 많이 나오고 있습니다.
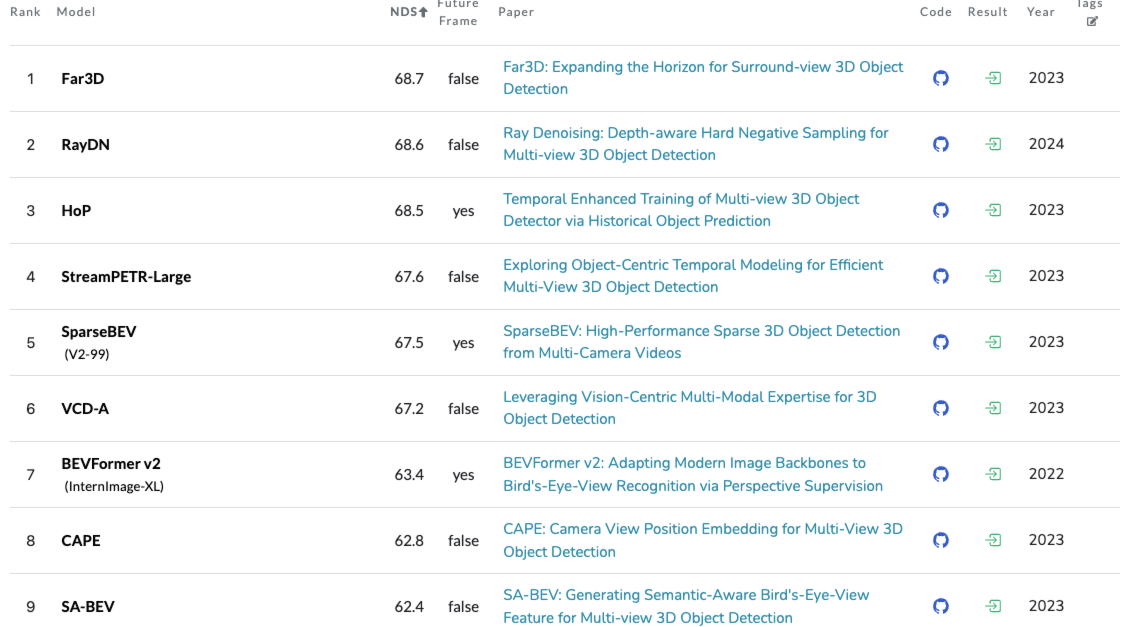
현재 multi-cam 3D detection분야는 BEV 방법론과 perspective 방법론으로 나눠져 있는데, 오늘 리뷰할 논문은 후자의 방법론을 사용하였습니다. 위의 벤치마크 순위에는 없지만 perspective 방법론은 해당 논문을 기반으로 설계되었습니다.
[paper review] BEVFusion 논문 리뷰
이번 논문리뷰는 BEVFusion이라는 논문으로 3D Detection에서 multi-modal 그 중에서도 camera-lidar에 관련된 논문입니다. ICRA 23에 publish되고 현재기준으로 multi model 3D detection쪽에서 opensource중에서는 최고성
jaehoon-daddy.tistory.com
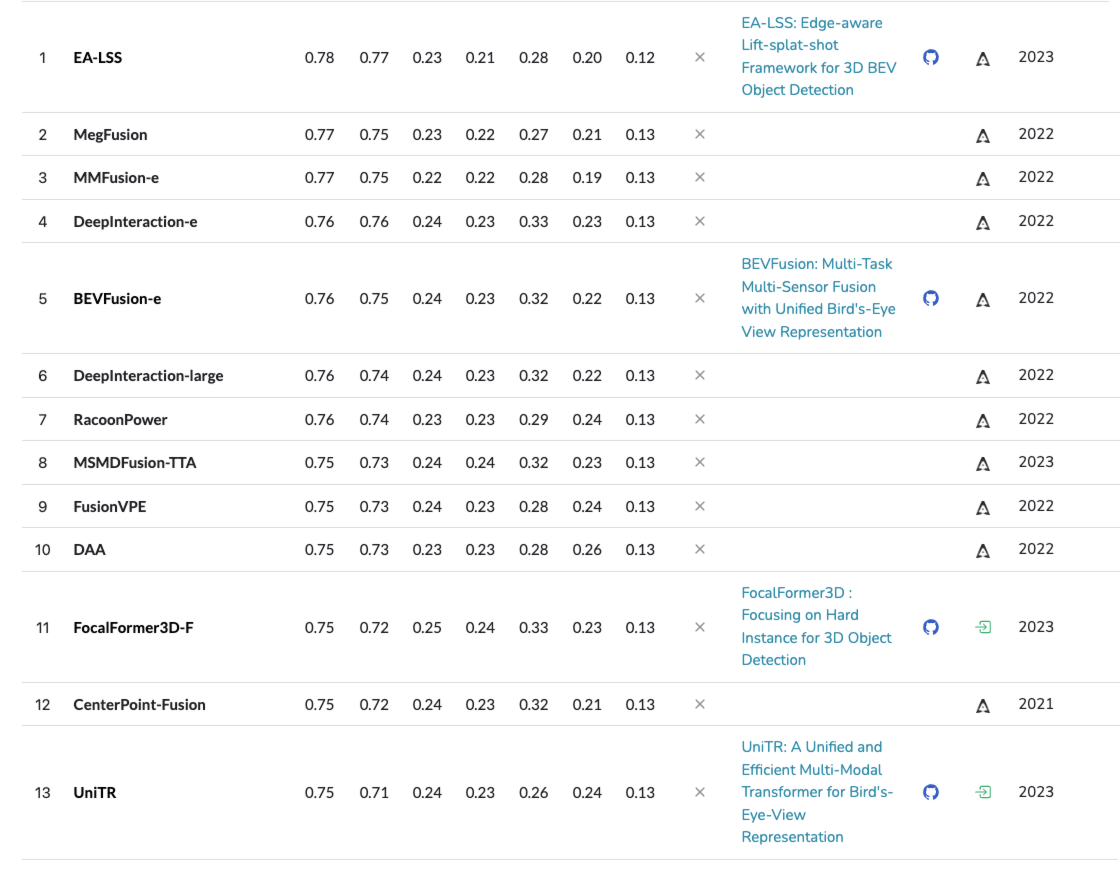
참고로 아래는 동일한 데이터셋의 lidar 혹은 lidar & camera 센서를 사용한 결과입니다. 생각보다 camera only 와 큰 차이(?)가 없습니다.
prior knowledge
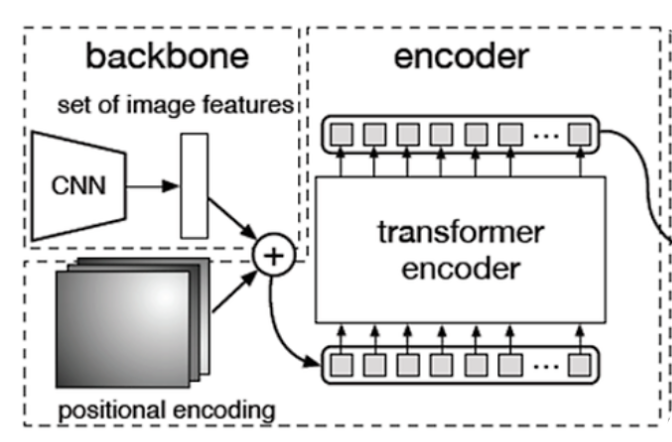
시작하기에 앞서 DETR을 먼저 보겠습니다. PETR은 Image분야의 현재 sota 아키텍쳐인 DETR를 참고하여 설계하였습니다.
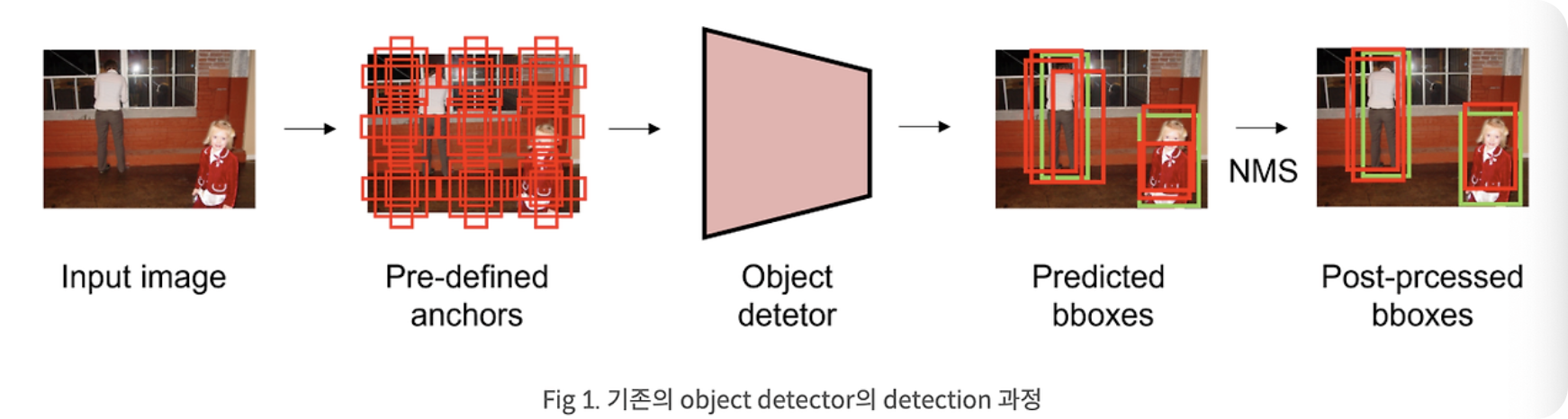
첫번째 사진은 기존의 detection 설계도 입니다. 보통 anchor box를 생성하여 prediction하고 이후에 NMS와 같은 함수를 통해 postprocessing과정을 거칩니다.
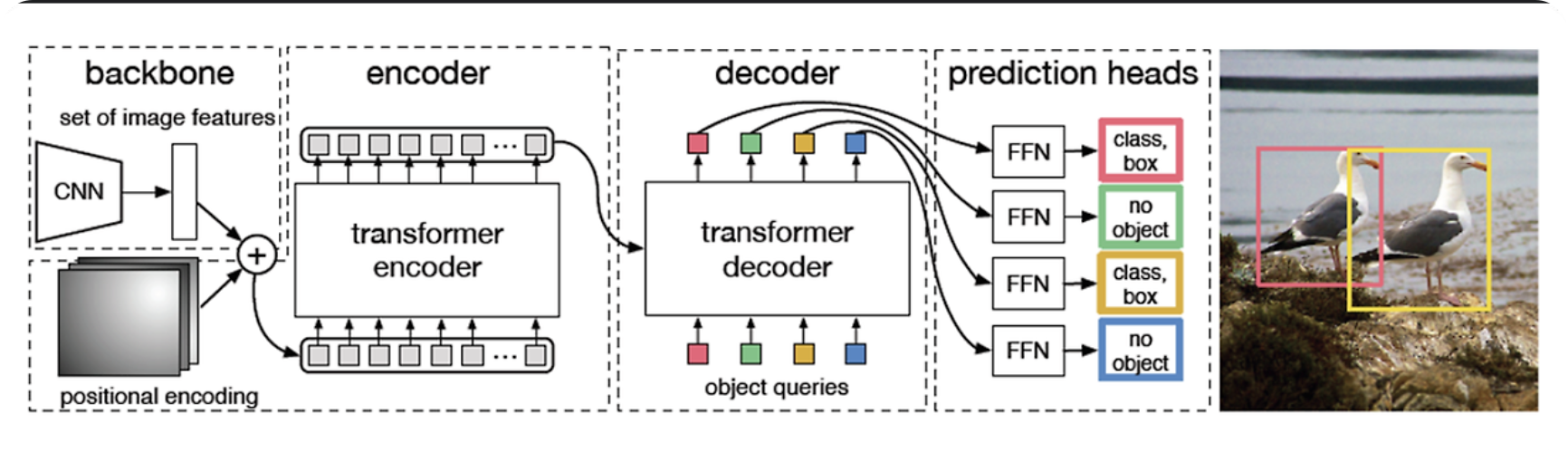
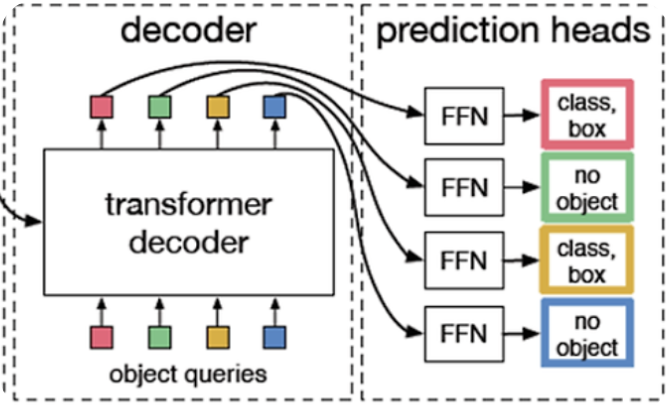
두번째 사진은 DETR의 설계도 입니다. 기존방법과는 다르게 N개의 bbox가 각각 object를 prediction합니다.
디테일한 내용은 아래 포스팅 확인하세요.
[CV / Detection] DETR기반의 Image Detector들
안녕하세요. 2D Detection관련하여 이번에는 DETR 모델에 관련해서 포스팅 하려합니다. 포스팅 시점 현재 2D image detection에서 bench mark SOTA에 올라와 있는 모델이 DETR기반의 모델이기 때문에 해당 모델
jaehoon-daddy.tistory.com
PETR
이제 PETR입니다. DETR과 같이 embedding과 transformer를 사용하여 prediction을 수행합니다. PETR이전에는 이와같은 방법이 3D에 없었냐? 있었습니다. DETR3D가 그것인데요. 문제는 reference point가 2D 기반에서 이뤄지다 보니 3D information을 충분히 담기 어려운 문제가 있었습니다.

이를 해결하기 위해 PETR는 3D 위치 정보를 2D feature에 encoding하여 3D space에서의 정확성을 향상시킵니다.
Overview
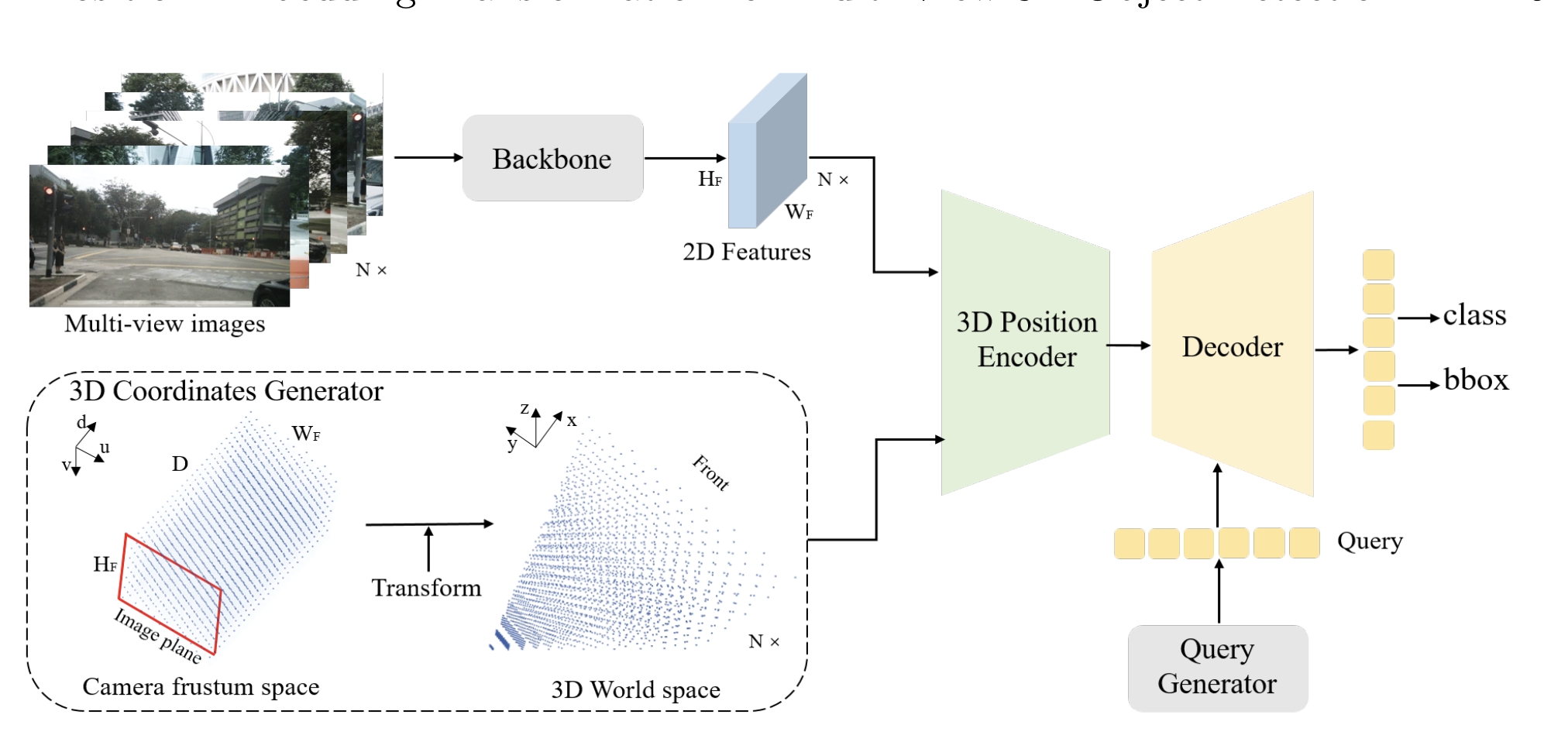
전체적인 overview입니다. multi-image가 들어오면 각각 resnet, ViT등을 이용해서 2D feature를 추출합니다. 3D Position Encoding하기 위해 coordinates Generator부분에서는 Camera공간을 3D world space로 transform하는 과정입니다. camera parameter를 알고있다는 가정하에 Inverse projection하여 camera frustum을 world space로 변경할 수 있습니다. 문제는 depth인데 이는 DGSN을 참고합니다.
다시 풀어서 설명하면 camera frustum공간을(혹은 2D feature(H,W,D)) 3D grid(meshgrid)화 시킵니다. - W,H,D 크기
해당 meshgrid를 camera parameter를 기반으로 world 좌표로 Inverse projection합니다.
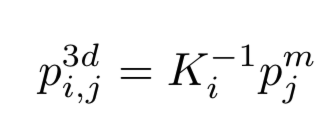
여기서 depth가 문제인데 이는 DGSN논문과 비슷한 방법으로 해결합니다.
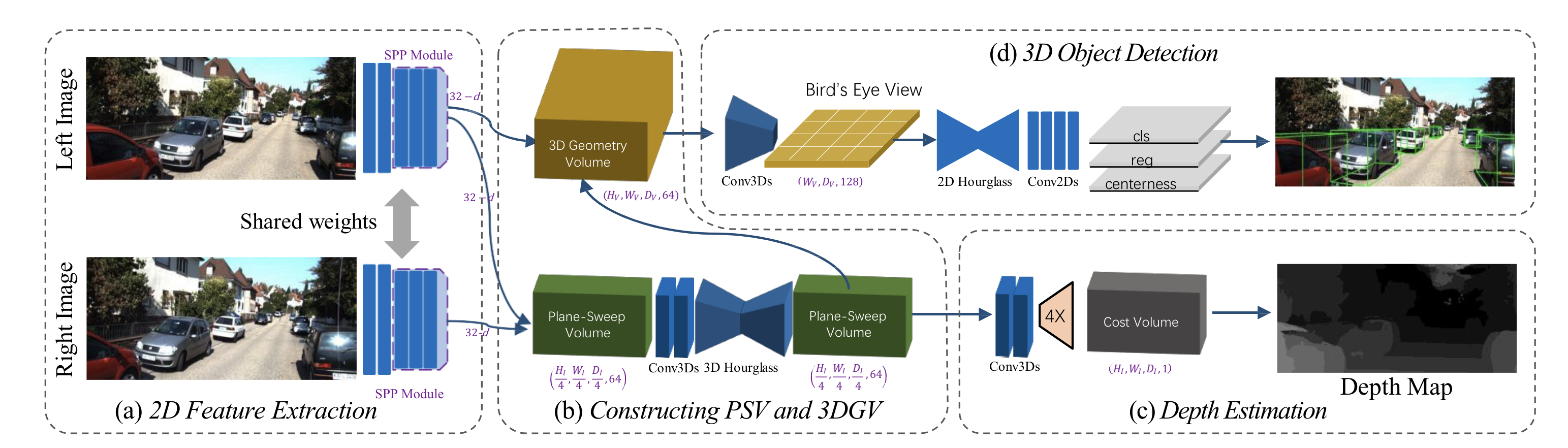
위의 그림에서 아래 부분에 plane-sweep volume을 만드는 것과 같이 PETR에서도 2D feature를 inverse projection후에 conv를 태워 (Dx4),H,W,(64-depth) 로 shape를 변환하면서 meshgrid화 합니다.(마치 depth map과 같음)
3D Position Encode
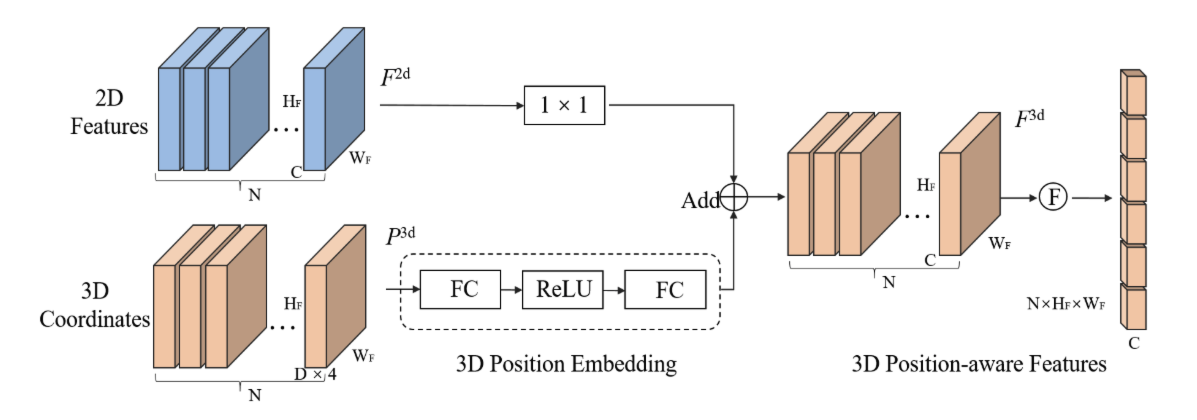
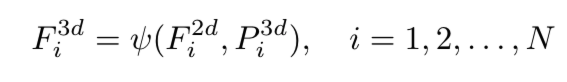
3D feature를 얻기위해 2D image features와 3D position 정보를 이용합니다. 우선 3D coordinate feature를 FC layer로 만들고 MLP를 태워 3D position embedding으로 변환합니다. 2D features는 각각 1x1크기로 conv를 이용해 변환합니다. 두 개의 features를 Add 하여 3D position의 정보가 추가된 feature를 생성해냅니다. DETR과는 다르게 encoder에서는 transformer를 사용하지 않는 것 같습니다.
Decoder
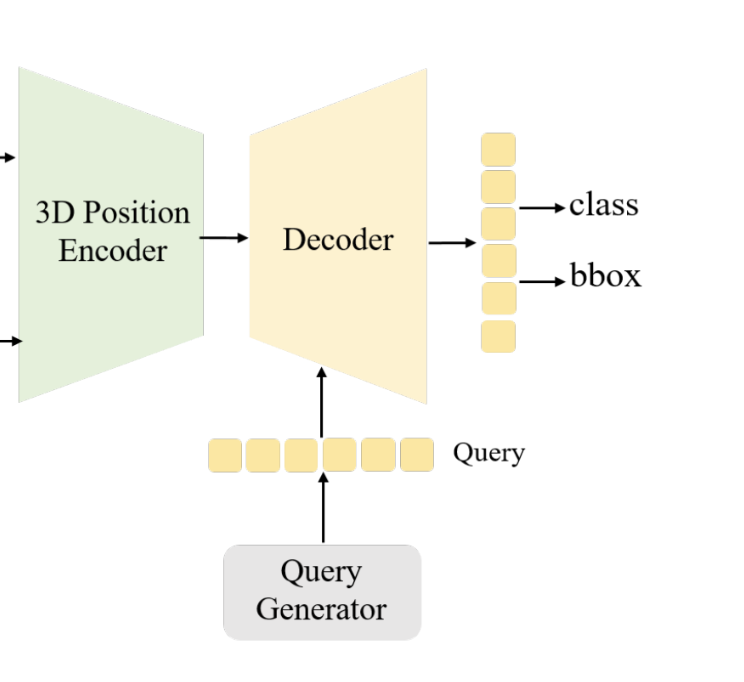
decoder에서는 우선 learnable anchor points들을 3D 공간상에서 random하게 생성하고 mini MLP를 통과시켜 initial queries를 만듭니다.
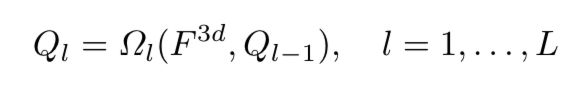
DETR처럼 L개의 decoder layer를 생성합니다. 위의수식은 L개 중 l번째의 layer를 뜻합니다. 하나의 decoder에서는 이전의 query와 encoder를 통해나온 3D feature를 multi-head attention을 진행합니다.
이후 query(N)개 만큼 각각 classification, bbox regression을 진행합니다.
Loss
loss는 classification과 3d bbox regression을 weight sum하여 구합니다. classification은 focal loss, regression은 L1 loss를 사용하고 GT와 각각의 prediction은 DETR과 같이 Hungarian 알고리즘을 통해 매칭합니다.
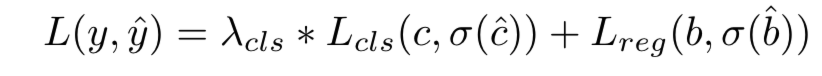
Experience
성능은 사실 PETR보다 높은 것들이 많지만 perspective model들은 대부분 PETR의 downstream의 것들이라고 보시면 됩니다.
nuscenes 데이터를 기반으로 한 결과값입니다.
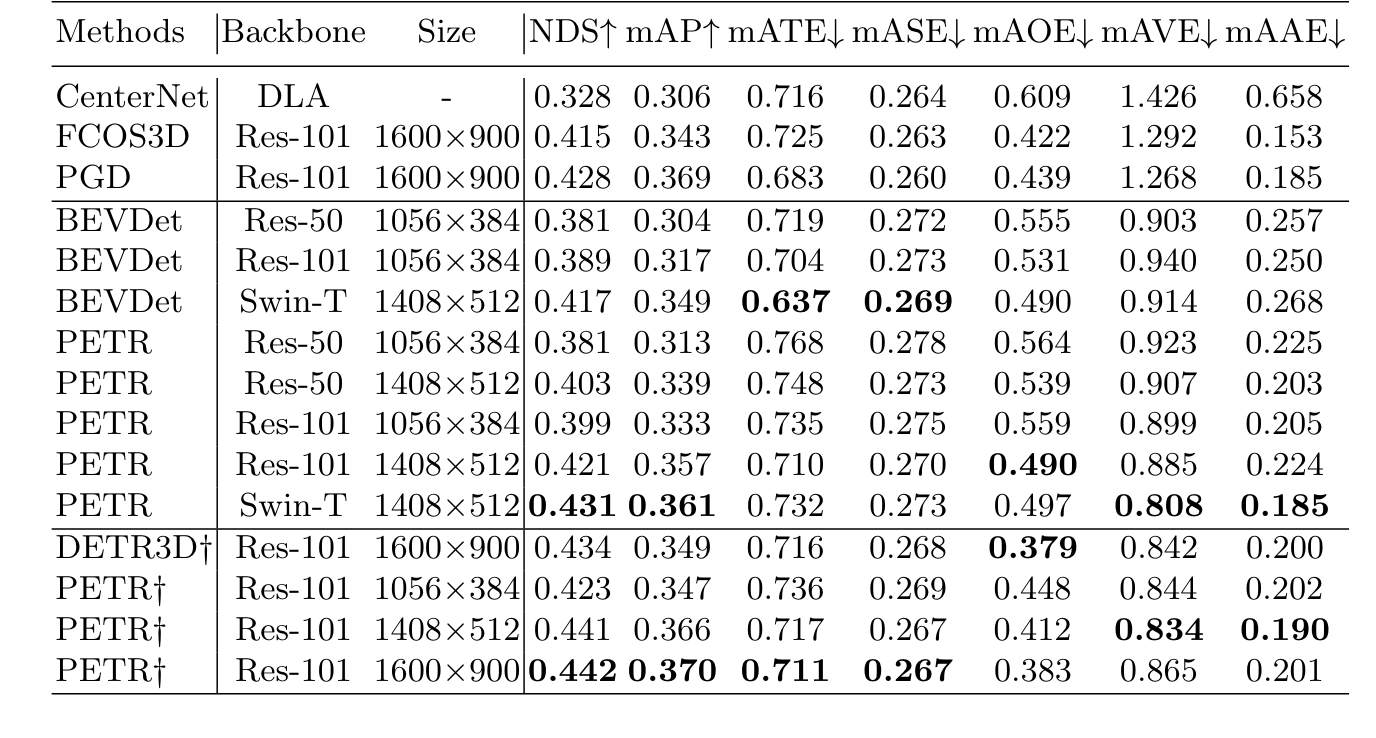
LIDAR detection모델인 CenterNet보다 성능이 좋은게 눈에 띕니다.

또한 10fps inference도 가능하다고 합니다.



