안녕하세요. 이번 포스팅은 딥러닝 모델 경량화 실습이라는 제목으로 이전 포스팅에 이어서 경량화 예제코드를 분석해 볼 생각입니다.
경량화에 대한 이론은 아래 포스팅 참고하세요.
[Optimization] 모델 경량화 이론 (ONNX, TensorRT)
안녕하세요. 이번에는 모델 경량화 관련하여 포스팅하도록 하겠습니다. 경량화의 목적 경량화를 하는 이유는 보통 edge device에서 딥러닝 모델을 inference하고 싶은데 보통의 edge device의 리소스가
jaehoon-daddy.tistory.com
실습할 모델은 DSVT라는 모델입니다. pointcloud detection model인데 기존의 pointcloud model은 3D backbone에서 3D convolution을 이용합니다. 그 과정에서 sparse convolution 모듈을 사용하는데 custom cuda를 사용하는지라 onnx변환이 쉽지 않습니다.
하지만 DSVT는 trasnformer를 사용하기 때문에 onnx변환이 비교적 쉽습니다.
ONNX 실습
우선 onnx변환을 먼저 봐봅시다. 여기선 onnx변환후에 tensorrt변환을 할 예정입니다. 다른 방법(바로 tensorrt로 변환하는)도 있습니다.
<environment>
onnx version : 1.16.0
torch version : 2.0.1
cuda : cu118
####### read input #######
batch_dict = torch.load("/path/to/input_dict.pth", map_location="cuda")
inputs = batch_dict
####### model #######
with torch.no_grad():
DSVT_Backbone = model.backbone_3d
dsvtblocks_list = DSVT_Backbone.stage_0
layer_norms_list = DSVT_Backbone.residual_norm_stage_0
inputs = model.vfe(inputs)
voxel_info = DSVT_Backbone.input_layer(inputs)
set_voxel_inds_list = [[voxel_info[f'set_voxel_inds_stage{s}_shift{i}'] for i in range(2)] for s in range(1)]
set_voxel_masks_list = [[voxel_info[f'set_voxel_mask_stage{s}_shift{i}'] for i in range(2)] for s in range(1)]
pos_embed_list = [[[voxel_info[f'pos_embed_stage{s}_block{b}_shift{i}'] for i in range(2)] for b in range(4)] for s in range(1)]
pillar_features = inputs['voxel_features']
alldsvtblockstrt_inputs = (
pillar_features,
set_voxel_inds_list[0][0],
set_voxel_inds_list[0][1],
set_voxel_masks_list[0][0],
set_voxel_masks_list[0][1],
torch.stack([torch.stack(v, dim=0) for v in pos_embed_list[0]], dim=0),
)
jit_mode = "trace"
input_names = [
'src',
'set_voxel_inds_tensor_shift_0',
'set_voxel_inds_tensor_shift_1',
'set_voxel_masks_tensor_shift_0',
'set_voxel_masks_tensor_shift_1',
'pos_embed_tensor'
]
output_names = ["output",]위 코드에서는 없지만 pcdet에서 dsvt model을 불러와 model 변수에 담습니다. 이론 포스팅에서 언급하였듯이 여기서는 trace모드로 변환을 할 예정이기에 sample input data가 필요합니다. 미리 pth파일로 준비해주었습니다.
이후 model의 vfe mehod에 sample input data인 inputs데이터를 forward합니다. 여기까지는 기존의 python을 사용합니다. 그 이유는 vfe는 voxel feature encoding으로 처음 pointcloud raw data를 voxel feature로 만드는데 custom cuda를 사용하기 때문에 여기부분은 onnx변환을 하지 않습니다.
voxel encoding이후에 dsvt에 전단계로 positional embedding등의 과정을 거칩니다. 이 과정 또한 onnx에서 지원하지 않는 operator가 사용되기에 기존의 python으로 진행하게 됩니다. input layer 이후에 나온 position embedding과 voxel list들이 input으로 들어가게 됩니다.
base_name = "./deploy_pillar_sfaw_3d_origin/deploy_pillar_sfaw_3d_origin"
ts_path = f"{base_name}.ts"
onnx_path = f"{base_name}.onnx"
allptransblocktrt = AllDSVTBlocksTRT(dsvtblocks_list, layer_norms_list).eval().cuda()
torch.onnx.export(
allptransblocktrt,
alldsvtblockstrt_inputs,
onnx_path, input_names=input_names,
output_names=output_names, dynamic_axes=dynamic_axes,
opset_version=14,
)다음 onnx export과정입니다. dsvt model을 onnx에서 사용가능한 operator으로만 수정해서 다시 구현한 model이 AllDSVTBlocksTRT입니다. export API에는 model 객체, dsvt의 input으로 들어갈 위에서 선언한 alldsvtblockstrt_inputs, 저장할 onnx path, input_names(option, alldsvtblockstrt_inputs와 input_names의 length가 같아야함) 등을 설정합니다.
# test onnx
ort_session = ort.InferenceSession(onnx_path)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# compute ONNX Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(pillar_features),
ort_session.get_inputs()[1].name: to_numpy(set_voxel_inds_list[0][0]),
ort_session.get_inputs()[2].name: to_numpy(set_voxel_inds_list[0][1]),
ort_session.get_inputs()[3].name: to_numpy(set_voxel_masks_list[0][0]),
ort_session.get_inputs()[4].name: to_numpy(set_voxel_masks_list[0][1]),
ort_session.get_inputs()[5].name: to_numpy(torch.stack([torch.stack(v, dim=0) for v in pos_embed_list[0]], dim=0)),}
ort_outs = ort_session.run(None, ort_inputs)
두 번째 과정이 잘 실행되었다면 onnx파일이 생성되었을 것입니다. 마지막으로 해당 onnx파일을 이용해서 실제 inference test하는 과정입니다.
InferenceSesson API를 통해 onnx를 로드해서 deserialize합니다. 이후 실제 input데이터들과 onnx 를 만들때 사용한 input_name과 알맞게 binding시킵니다.
마지막으로 run API를 실행하여 output을 얻을 수 있습니다.
TensorRT
<environment>
onnx version : 1.16.0
torch version : 2.0.1
cuda : cu118
tensorrt : 10.0
다음으로 TensorRT를 이용하여 inference해보겠습니다.
onnx로 변환한 파일을 tensorrt package를 이용해서 engine파일을 만들어야합니다. 저는 tar파일을 설치하여 cli를 이용하였습니다.
Nvidia Developer 사이트에서 본인에 맞는 버전의 Tar파일을 다운로드합니다. (RPM, Debian Installation 하여도 됩니다)
저의 경우 아래 명령어를 통해서 Tar 파일을 다운로드하고 installation하였습니다.
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/10.0.0/tars/TensorRT-10.0.0.6.Linux.x86_64-gnu.cuda-11.8.tar.gz
python3 -m pip install tensorrt-10.0.0b6-cp38-none-linux_x86_64.whl
export PATH=/path/to/tensorrt/bin:$PATH
source ~/.bashrc
이후에는 cli통해 engine파일을 만듭니다.
trtexec --onnx=./deploy_pillar_sfaw_3d_origin/dsvt_3d_bb_origin.onnx --saveEngine=./deploy_pillar_sfaw_3d/dsvt_3d_bb.engine --verbose --fp16
다음은 inference하는 단계입니다.
def load_trt_engine(path: str) -> trt.ICudaEngine:
"""Deserialize TensorRT engine from disk.
Args:
path (str): The disk path to read the engine.
Returns:
tensorrt.ICudaEngine: The TensorRT engine loaded from disk.
"""
# load_tensorrt_plugin()
with trt.Logger() as logger, trt.Runtime(logger) as runtime:
with open(path, mode='rb') as f:
engine_bytes = f.read()
engine = runtime.deserialize_cuda_engine(engine_bytes)
print(f"TensorRT engine {path} successfully loaded.")
return engine
trt.init_libnvinfer_plugins(None, '')
if isinstance(trt_path, str):
engine = load_trt_engine(trt_path)
if not isinstance(engine, trt.ICudaEngine):
raise TypeError(f'`engine` should be str or trt.ICudaEngine, \
but given: {type(engine)}')
context = engine.create_execution_context()engine파일을 read하고 deserialize하고 execution하기위한 context 객체를 생성합니다.
bindings = [None] * (len(input_names) + len(output_names))
profile_id = 0
idx = 0
for input_name, input_tensor in inputs.items():
profile = engine.get_profile_shape(profile_id,input_name)
print(f'profile : {profile}')
print(f'type : {input_tensor.dtype}')
print(f'shape : {input_tensor.size()}')
context.set_input_shape(input_name,tuple(input_tensor.shape))
bindings[idx] = input_tensor.contiguous().data_ptr()
idx+=1
bindings[-1] = output.data_ptr()input_tensor를 차례대로 binding하는 과정입니다. input tensor의 시작주소를 순서대로 binding list에 append합니다.
context.execute_v2(bindings)마지막으로 binding한 리스트를 매개변수로 하여 execute를 합니다.
tensor([[-0.9653, -0.2267, -0.1353, ..., -1.1621, -0.1450, -0.2219],
[-1.0186, -0.1864, -0.1697, ..., -1.1982, -0.1243, -0.2854],
[-1.0752, -0.1381, -0.1663, ..., -1.0742, 0.1079, -0.2844],
...,
[-0.3411, 0.4285, -0.3716, ..., -0.9014, -0.8604, -0.0605],
[-0.6758, 0.6250, -0.0422, ..., -1.0859, -1.0088, -0.3896],
[-0.7290, 0.2339, 0.1506, ..., -1.0791, -0.2252, -0.5078]],
device='cuda:0', grad_fn=<CloneBackward0>)
실행결과는 python으로 수행한 matrix값과 거의 비슷하여 잘 inference된 것을 확인할 수 있습니다.
Benchmark
이번에는 어느정도의 속도의 이점이 있는지 보겠습니다. 기본 python code vs onnx(cpu) vs tensorRT 를 비교해보도록 하겠습니다.
또한 pointcloud Detection은 voxel encoding -> 3D backbone -> BEV -> 2D backbone의 아키텍쳐를 가지고 있는데 3D BB, BEV, 2D BB의 모듈 각각을 벤치마크 해보았습니다.
latency
<environment>
GPU : TITAN RTX
TRT : 16fp
ONNX : cpu, 16fp
time : s(second)
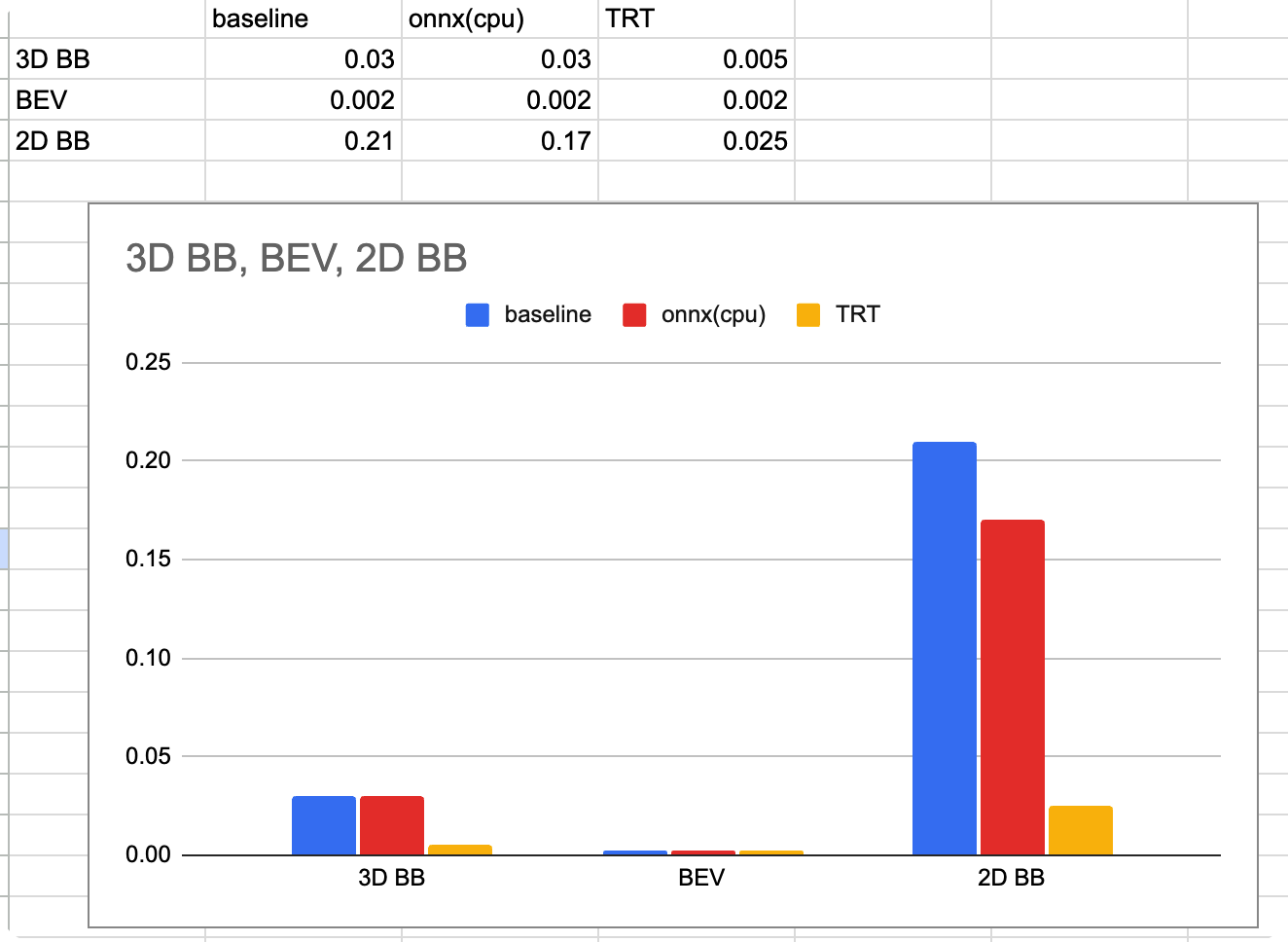
위의 그래프를 분석해보자면 우선 2D backbone에서 모든 case에서 computing cost가 제일 컸습니다. 아마 3D BB은 transformer로 되어있는데 오히려 GPU friendly한 측면이 있어서 시간적으로는 더 유리한 것 같습니다. 또한 TRT가 예상했듯이 가장 빨랐고 onnx의 경우 cpu로
inference했음에도 GPU로 inference한 baseline과 비슷한 것을 알 수 있었습니다.
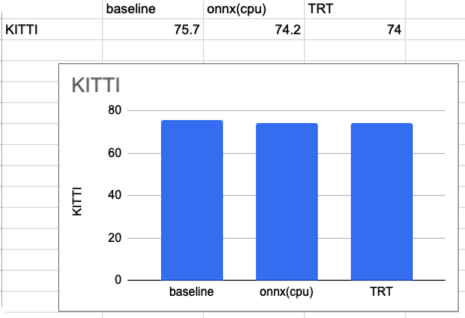
accuracy
정확도는 KITTI를 사용하였습니다. VFE와 HEAD는 baseline 코드를 이용하였습니다. 수치는 mAP입니다.

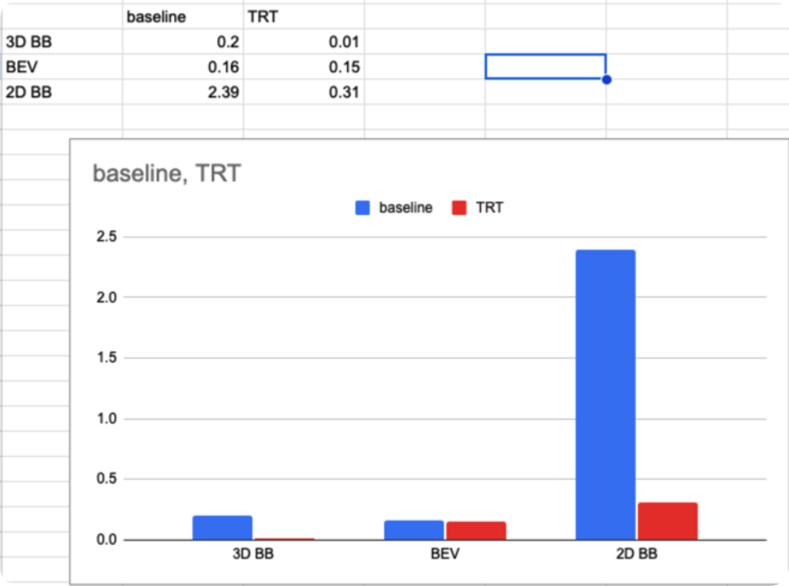
memory 사용량
단위는 Gb입니다.
여기까지해서 경량화 관련하여 실습 포스팅을 마치겠습니다.

Inference


